


도입
•
LLM은 다양한 Task에서 전반적으로 뛰어난 모습을 보여주고 있지만 많은 계산량으로 인하여 응답 속도가 느리고 비용이 높다는 이슈가 존재함
•
SFT(Supervised Fine Tuning)는 작은 크기의 모델로 특정 도메인이나 Task에 특화하여 뛰어난 성능을 얻을 수 있으며 모델을 사람이 원하는 대로 제어하고 Align하기 위한 대표적인 방법
•
그렇지만 특히 LLM을 파인튜닝하는 것은 많은 컴퓨팅 자원이 필요하므로 최소한의 데이터만 학습하여 원하는 성능을 얻을 수 있는 Data Selection 방법에 관심이 많음
•
이 아티클에서는 파인 튜닝할 때 효과적인 Data Selection 방법에 대한 논문을 소개함
•
리뷰 논문
◦
https://arxiv.org/abs/2410.09335 (by Jilin University, Alibaba Group)
개요
•
요약 : LLM을 파인 튜닝할 학습 데이터를 선택할 때 Random으로 선택하여도 충분하다는 내용
•
SFT를 수행할 때 적은 학습 데이터로 원하는 최적의 성능을 얻기 위한 다양한 Data Selection 방법들이 존재
•
본 논문에서는 데이터의 크기가 충분히 큰 경우 Random Selection을 해도 충분히 효과적임을 실험으로 입증함
•
또한, 학습 데이터의 품질 보다는 다양성이 더 중요하다는 점을 확인함
비교 대상 Data Selection 방법론들
•
스스로 데이터를 판단하는 Self-scoring 기반의 방법론들만 비교 대상으로 선택
◦
외부 강력한 모델이 평가해준 결과를 사용한다는 것은 일종의 Distillation 효과가 있으므로 Random Selection 과는 공정한 비교라 할 수 없음
•
각 방법론의 개략적인 컨셉만 설명함. 상세한 내용은 논문을 참고
•
품질 기반 (Quality-based Selections)
◦
▪
Gradient를 기반으로 가장 "영향력 있는" 데이터를 선택하는 아이디어
▪
Gradient가 가장 큰(보다 정확히는 Sub-validation Set들과의 유사도가 가장 큰) 데이터들을 위주로 선택하는 방식
◦
▪
(Q, A) 페어에 대하여 A만 넣었을 때의 점수(s(A)) 대비 Q를 조건으로 추가했을 때의 점수(s(A|Q))가 높은 데이터 위주로 선택
▪
여기서 점수는 negative log probability를 사용
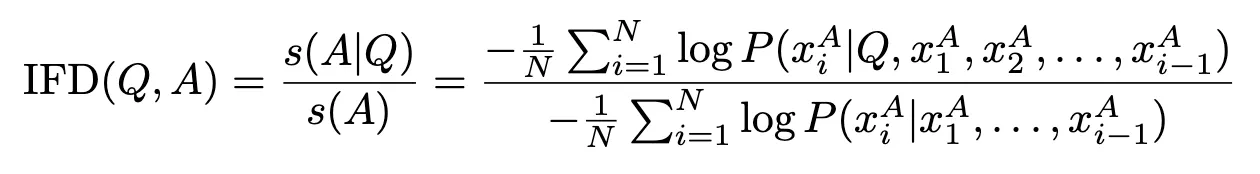
◦
▪
LLM의 Output 토큰 확률 값을 기반으로 계산한 점수가 높은 데이터를 위주로 선택하는 방식
▪
Token-level, Sentence-level, Model-level 총 3단계의 측정 방법이 있음
◦
Cross-entropy
▪
입력 데이터 (Q, A) 페어에 대하여 Cross Entropy가 높은 값을 갖는 것을 위주로 선택하는 방식
▪
Cross-entropy 계산 시 확률 함수는 모델을 사용
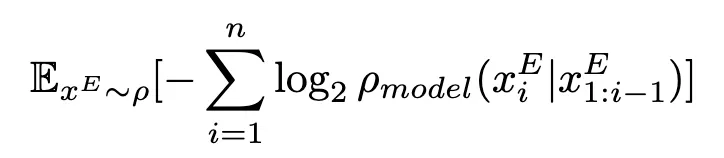
•
다양성 기반 (Diversity-based Selections)
◦
▪
기존 데이터와 가장 거리가 멀리 떨어진 (가장 이질적인) 데이터를 선택하는 아이디어
▪
현재 선택된 데이터 중 자신과 가장 가까이 있는 데이터와의 거리가 최대가 되는 데이터를 위주로 선택
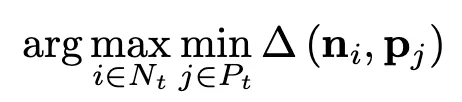
◦
▪
모델 성능은 데이터의 압축률과 음의 상관관계가 있다는 사실을 활용하는 아이디어
▪
낮은 데이터 압축률을 보이는 데이터를 위주로 선택
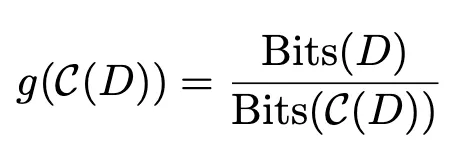
Results
•
실험 대상 모델 : Qwen2-7B, Llama3-8B
•
실험 대상 학습 데이터 : Openhermes2.5 (1M), WildChat-1M (전체 1M개 중 영어 데이터 440k만 선택하여 사용)
◦
위 데이터 중 주어진 방법론에 의거하여 10k 개씩 선택하여 학습에 사용
•
벤치마크 데이터 : BBH, GSM, CODE(HumanEval), MMLU, IFEVAL
•
종합 결과
Model | Qwen2-7B | Llama3-8B | ||
방법론 | Openhermes2.5 | WildChat | Openhermes2.5 | WildChat |
Base | 52.9 | 52.9 | 43.24 | 43.24 |
All Data | 59.73 | 61.65 | 57.17 | 54.58 |
Random 1 | 57.04 | 59.44 | 51.64 | 52.79 |
Random 2 | 59.26 | 58.52 | 52.77 | 53.22 |
Random 3 | 58.29 | 59.54 | 53.69 | 52.92 |
Random 4 | 57.83 | 58.74 | 54.01 | 53.48 |
Random 5 | 58.12 | 59.55 | 52.89 | 54.35 |
LESS | 55.5 | 53.81 | 50.79 | 53.52 |
IFD | 55.13 | 57.43 | 48.69 | 53.08 |
SelectIT | 57.99 | 58.72 | 51.79 | 51.15 |
Entropy | 54.02 | 60.39 | 47.59 | 54.10 |
DiverseEvol | 59.58 | 59.7 | 53.45 | 52.06 |
ZIP | 58.76 | 60.5 | 52.89 | 54.59 |
◦
각 컬럼별 가장 높은 점수는 빨간색, 두 번째로 높은 점수는 파란색으로 표시
◦
모든 task에서 Random Selection을 이기는 방법론은 존재하지 않았음. 오히려 Llama3의 경우 Random이 가장 좋은 성능을 보이기도 함
◦
DIversity-based 방법들이 Quality-based 방법보다 전체적으로 더 나은 성능을 보여줌
•
상세 결과
◦
Openhermes2.5
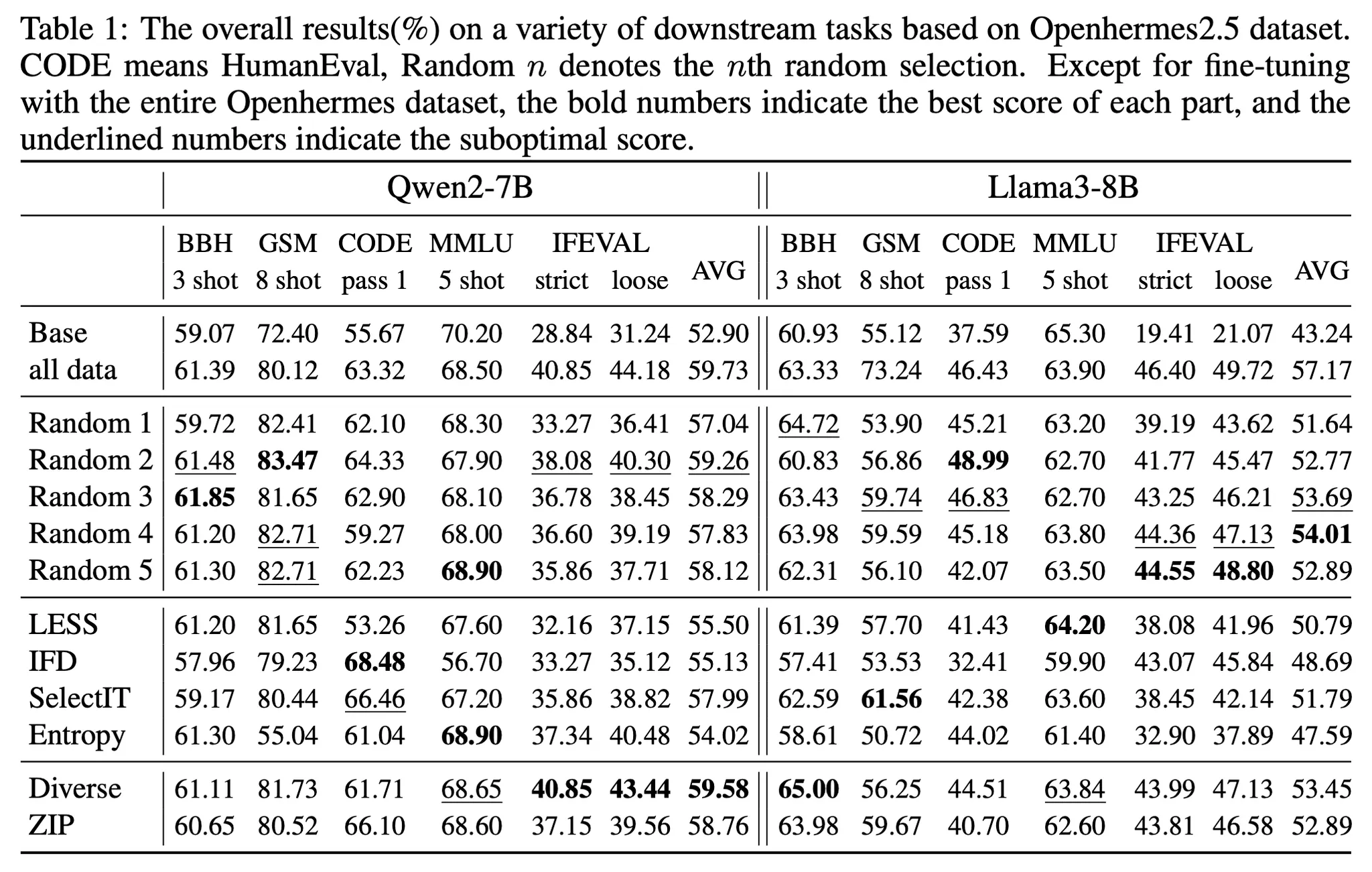
◦
WildChat
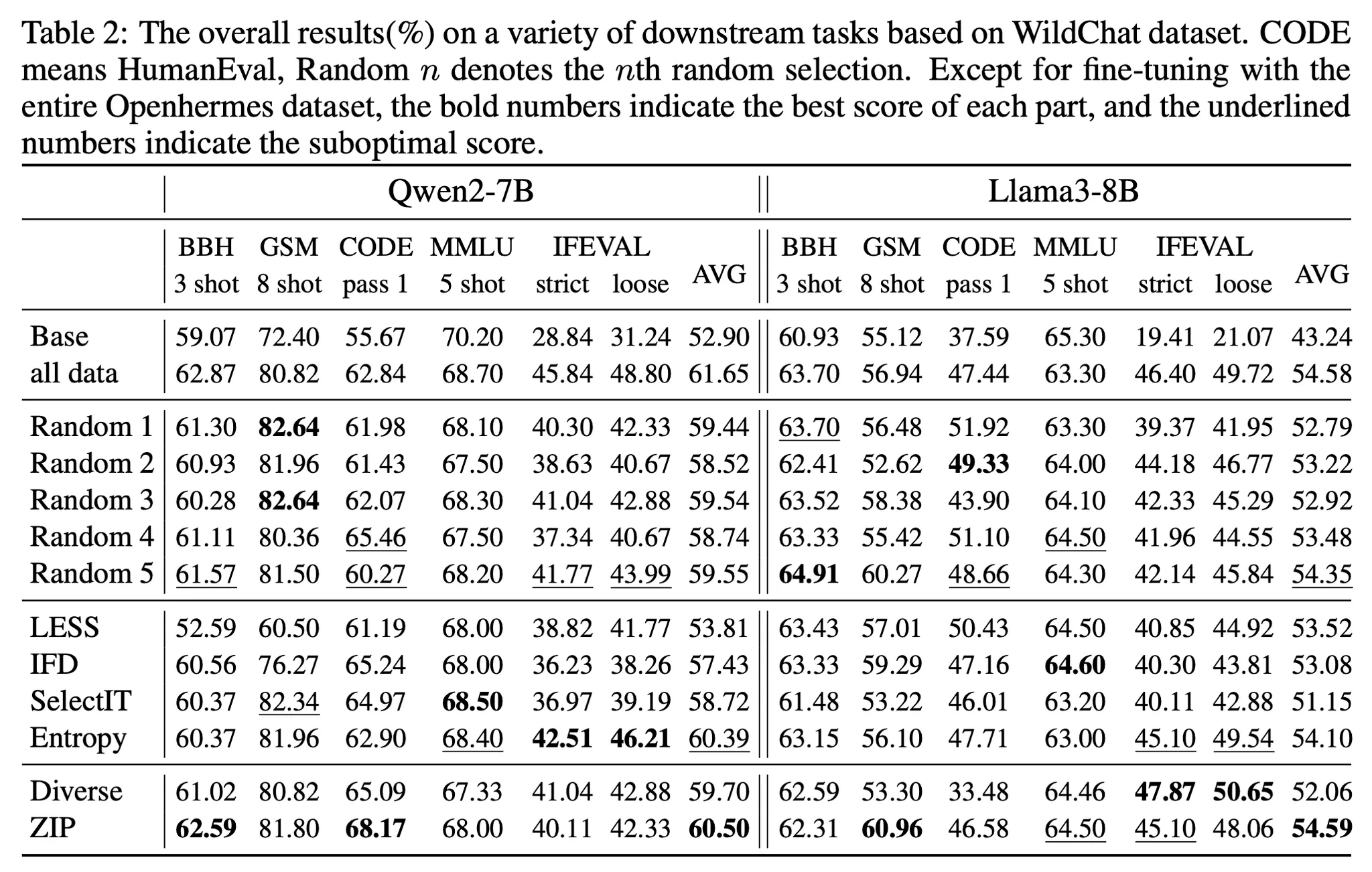
•
추가 실험
◦
원본 데이터 크기에 따른 성능
▪
10k-300k 인 경우 성능 향상 효과가 존재(파란색)하지만 1M 정도로 커지면 효과 없음 (빨간색)
▪
특히 품질 기반 방법론의 경우 훨씬 큰 차이를 보여줌
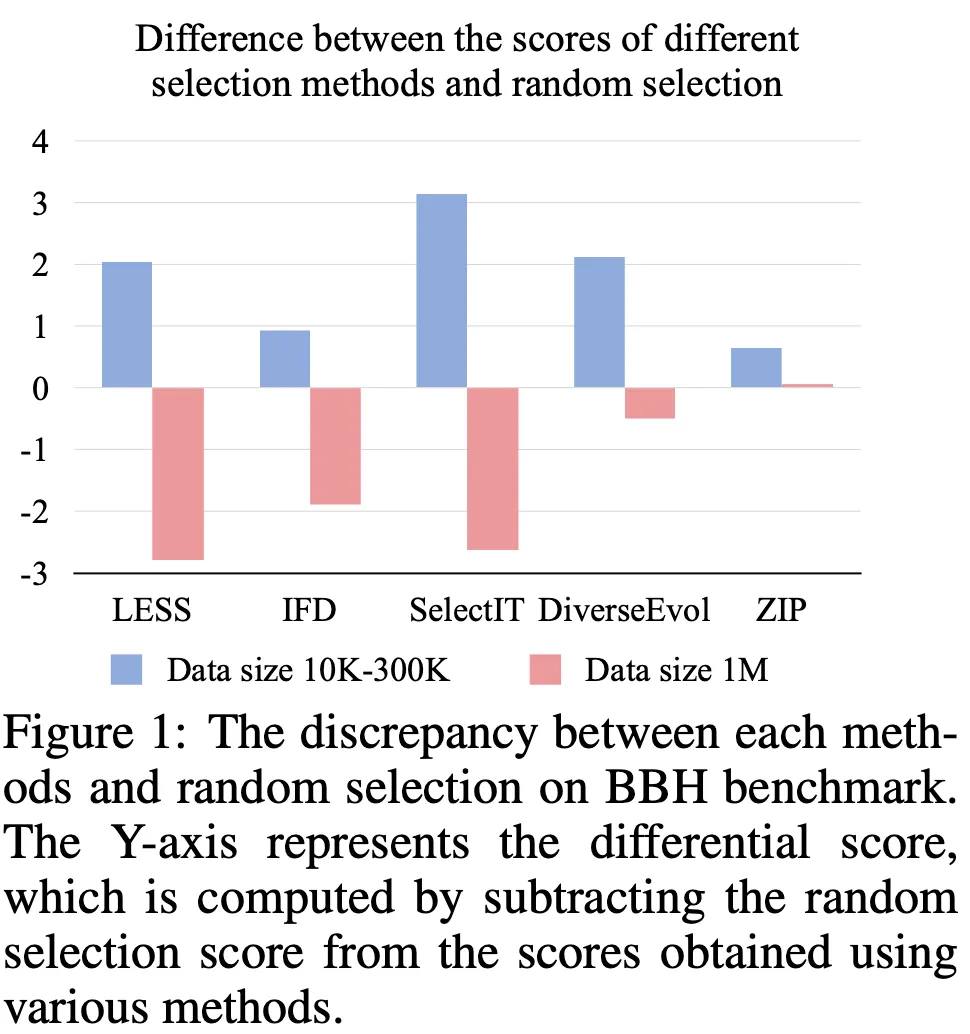
◦
다양성에 대한 실험
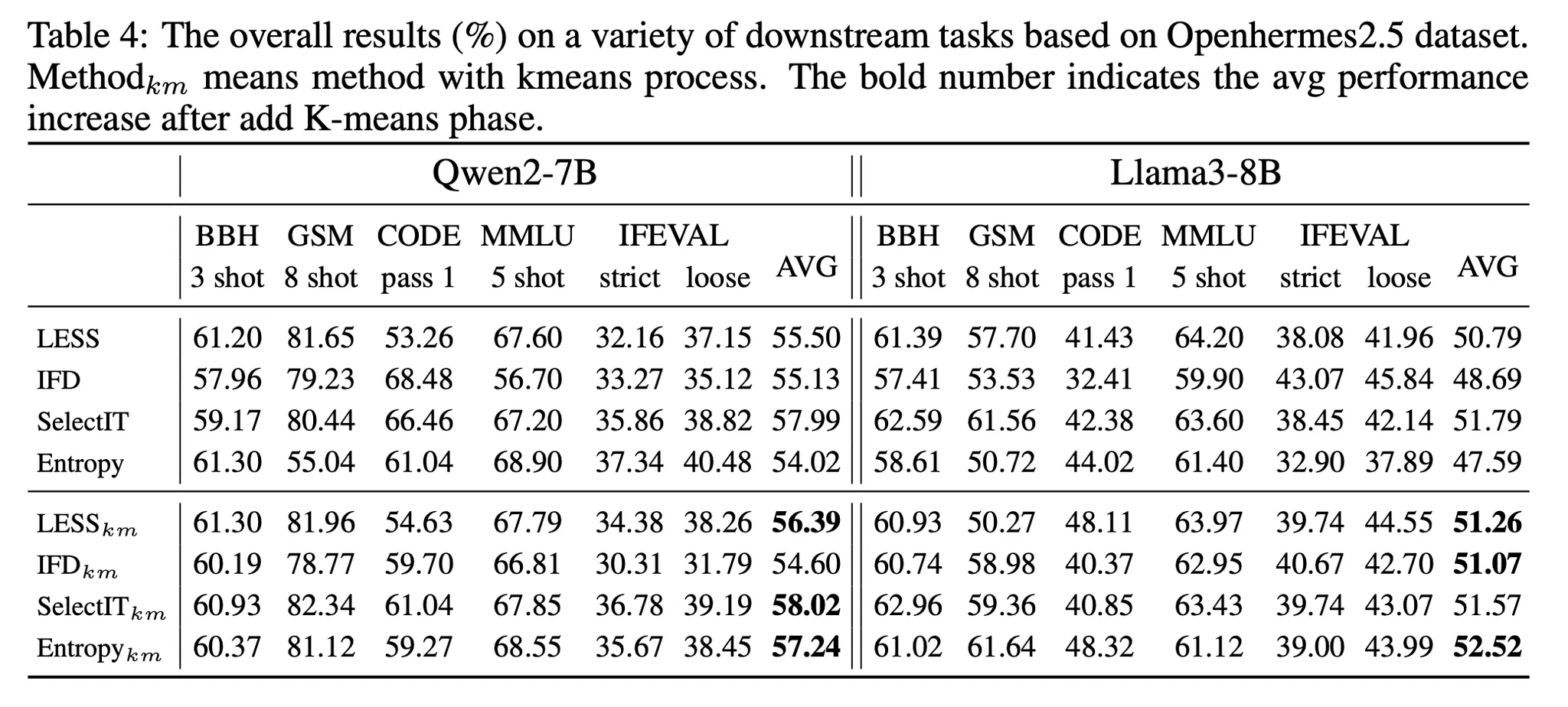
▪
아래 4가지(km이 붙어있는 항목)는 우선 데이터를 K-means 클러스터링으로 나눈 후 각 클러스터에서 Quality 점수가 높은 데이터를 선택하도록 한 경우의 점수
▪
거의 모든 케이스에서 성능이 향상되었으며 특히 Entropy 방법은 약 5%(Llama3), 3%(Qwen2) 향상이 존재함
▪
즉, 학습 데이터의 다양성이 최종 성능에 중요한 요소임을 알 수 있음
Further Analysis
•
좋은 AI 모델을 만들기 위해서는 데이터의 중요성을 아무리 강조해도 지나치지 않음
•
좋은 성능을 얻기 위한 학습 데이터의 조건 : Diversity > Quality > Quantity
◦
일반적으로 AI 모델을 개발할 때, 초기에는 데이터의 양(quantity)이 중요하지만, 그 다음에는 품질(quality)이 중요
◦
반면 데이터의 다양성이 중요하다는 점은 일반적으로 널리 알려진 사실이나 데이터의 품질 보다도 더 중요한 요소라는 점은 흥미로움
•
효과적인 데이터 선택 방법
◦
가장 좋은 학습 데이터는 최소의 양으로 모델이 학습하고자 하는 분포를 최대한 표현한 형태
◦
그렇지만 우리는 학습하고자 하는 분포를 미리 알 수 없음 (미리 알고 있다면 애초 모델의 학습 과정 자체가 필요가 없음)
◦
즉, 데이터가 10K~300K 수준인 경우는 본래 학습하고자 하는 분포를 충분히 표현하기 어렵지만 1M 정도 이상이 되면 일반적으로 학습하고자 하는 분포와 거의 흡사해 진다고 볼 수 있음(Law of Large Number).
◦
따라서 분포를 충분히 표현하지 못하는 데이터 규모에서는 조금이라도 더 의미 있는 데이터를 선택하는 다양한 selection 방법들이 효과가 있는 것이라 볼 수 있음. 반면 1M 이상 커지게 되면 어차피 전체 분포를 거의 잘 표현하고 있기 때문에 단순 Random Selection으로도 충분한 것이라 해석할 수 있음
◦
더욱이 일반적으로 위에서 비교한 Data Selection 방법들이 꽤 많은 계산량이 필요하다는 점을 감안할 때 꼭 필요한 상황이 아니면 Random Selection이 훌륭한 대안이 될 수 있음