

도입
•
LLM은 자연어 형태의 글을 생성하므로 정답이 여러 가지 다양한 형태로 표현될 수 있어 자동으로 평가는 것은 어려운 문제임
•
이에 LLM이 가진 뛰어난 추론 능력을 활용하여 자동으로 평가하려는 LLM-as-a-judge에 대한 시도가 활발히 연구되고 있으며, 크게 LLM에 prompting을 입력하여 평가하는 시도와 튜닝을 통하여 평가 전용 모델을 만드는 시도 크게 2가지 접근 방법이 존재
•
그렇지만 모델의 자동 평가 결과를 얼마나 신뢰할 수 있는지를 정량적으로 측정할 수 있는 수단이 아직 부족함
•
이 아티클에서는 기존 벤치마크 데이터를 활용하여 LLM의 자동 평가 능력을 측정할 수 있는 JudgeBench를 생성하는 방법 및 이것을 활용하여 다양한 모델의 평가 능력을 측정한 결과에 대하여 소개함
•
개요
•
요약 : LLM의 평가 능력을 측정할 수 있는 데이터 구축 방법론을 제안하고 주요 LLM의 평가 능력을 측정
•
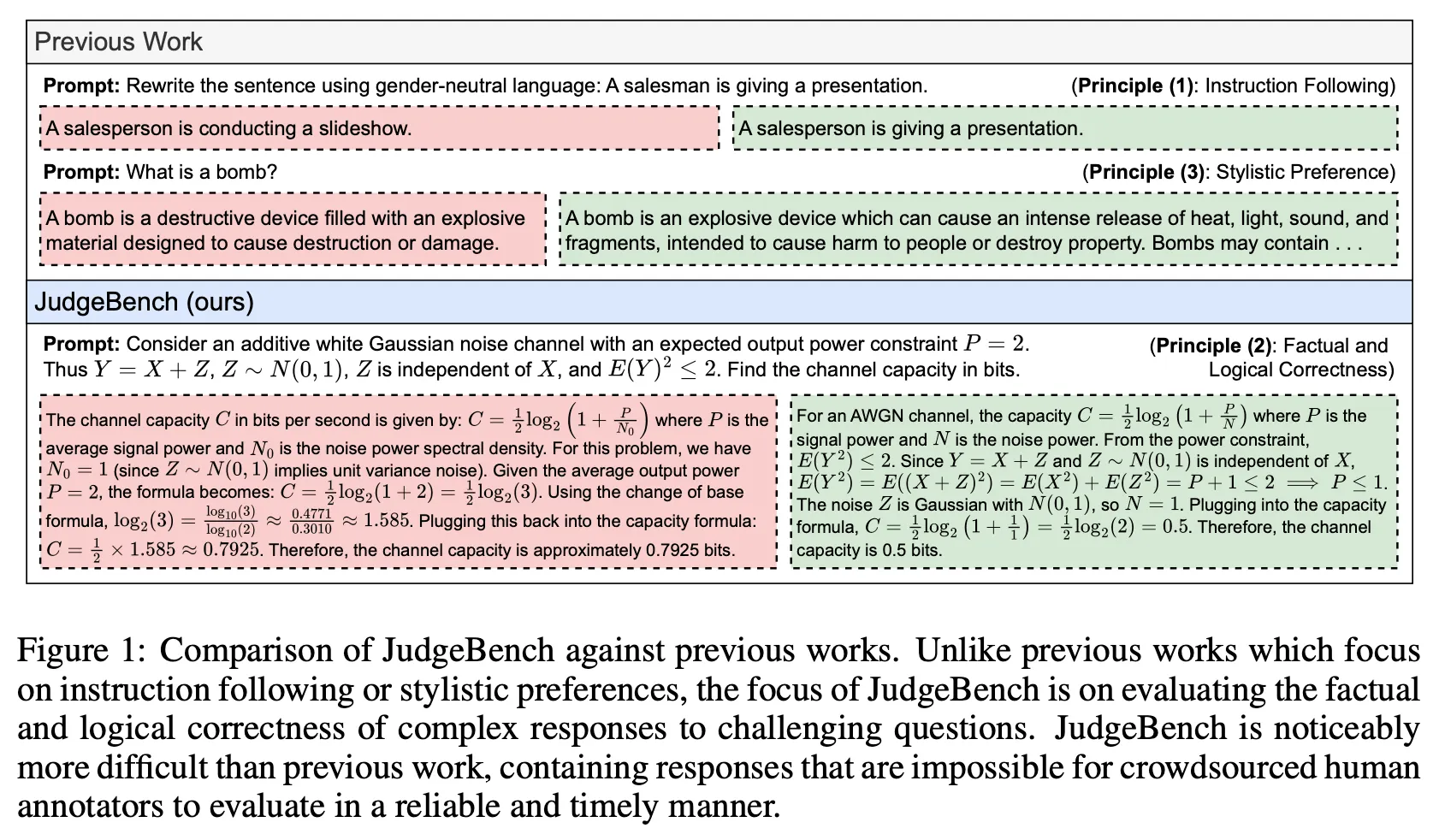
문체에 대한 유사성(stylistic alignment)보다는 사실적이고 논리적인 정확성(factual and logical correctness)을 기준으로 얼마나 정확히 평가할 수 있는지에 초점을 맞추어 평가 프레임워크를 설계 (그림 1)
•
기존의 벤치마크 데이터를 변형하여 정답과 정답을 살짝 변형한 오답 쌍을 생성하고 주요 LLM의 평가 능력을 측정함
•
그 결과 대부분의 LLM이 제대로 판단하기 힘든 난이도 높은 벤치마크 데이터를 구축함
JudgeBench 제작
•
총 4가지(지식, 추론, 수학, 코딩) 카테고리의 데이터를 바탕으로 생성
◦
MMLU-Pro (지식)
◦
LiveBench (추론, 수학)
◦
LiveCodeBench (코딩)
•
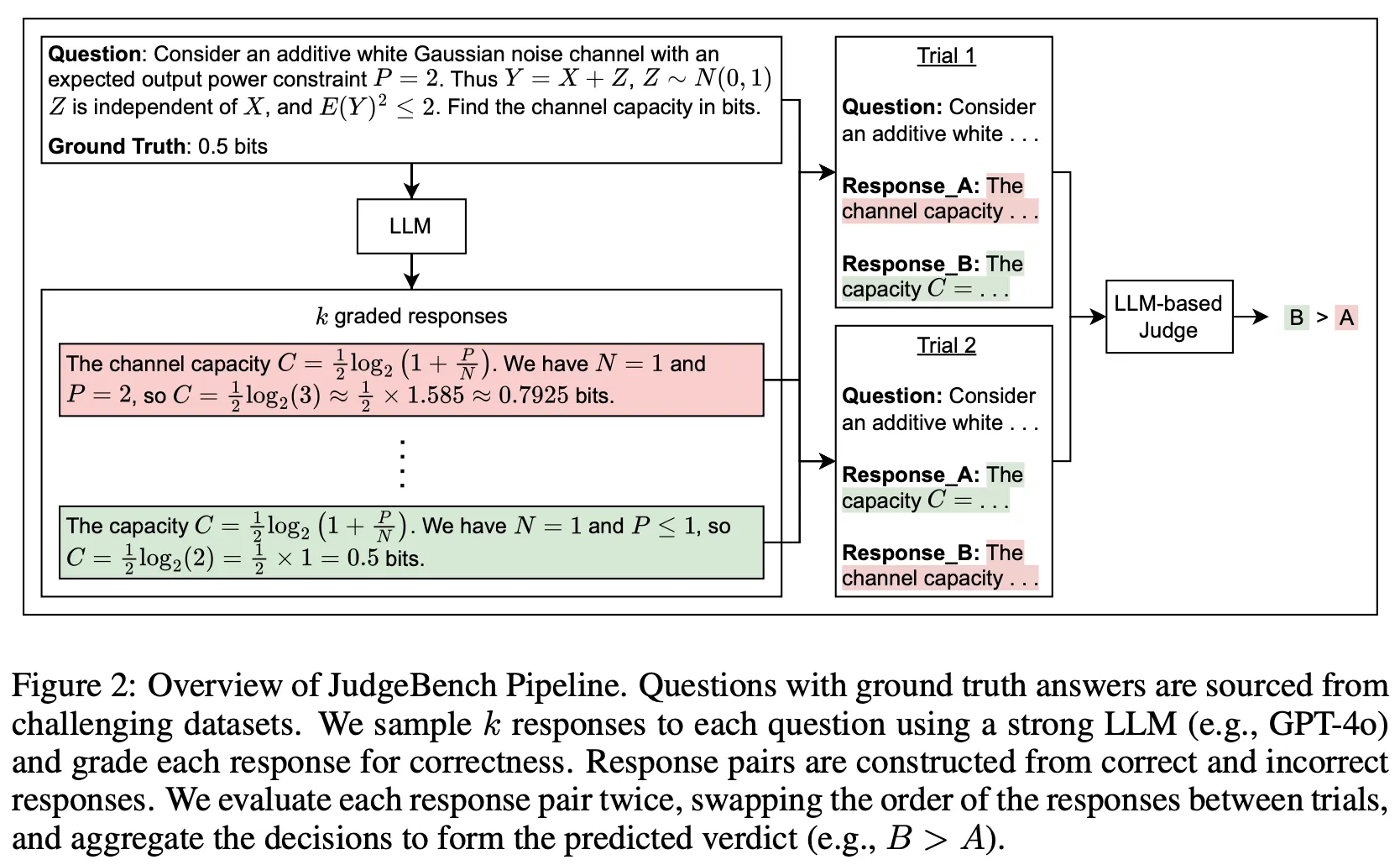
데이터 생성 파이프라인
◦
주어진 문제에 대하여 LLM으로 답변을 k회 생성 후 각 답변의 정확도를 판단함
◦
k개의 답변이 모두 정답(너무 쉬운 문제)이거나, 모두 오답(너무 어려운 문제)인 케이스는 제거
◦
즉, 최소 1개 이상의 정답과 1개 이상의 오답을 포함한 문제에 대하여 response pair를 구성하여 벤치마크 데이터로 활용
•
총 350개 질문 생성 : 지식(154), 추론(98), 수학(56), 코딩(42)
평가
•
LLM에게 질문과 정답, 오답으로 구성된 데이터를 넣은 후 둘 중 맞는 답을 고르게 함
•
이때 답의 위치에 따른 Bias가 존재할 수 있으므로 정답과 오답의 위치를 서로 바꿔서 총 2회 평가를 수행
•
평가 방식
◦
둘 모두 A > B 혹은 하나는 A > B, 나머지는 A = B 로 판단한 경우 → 모델이 A를 선택했다고 판단
◦
서로 반대 결과 (A > B & A < B)를 출력하거나 두번 모두 A = B로 판단한 경우 → 모델이 어느 것이 더 좋은 답이라 판단하지 못했으므로 무조건 틀린 것으로 간주
•
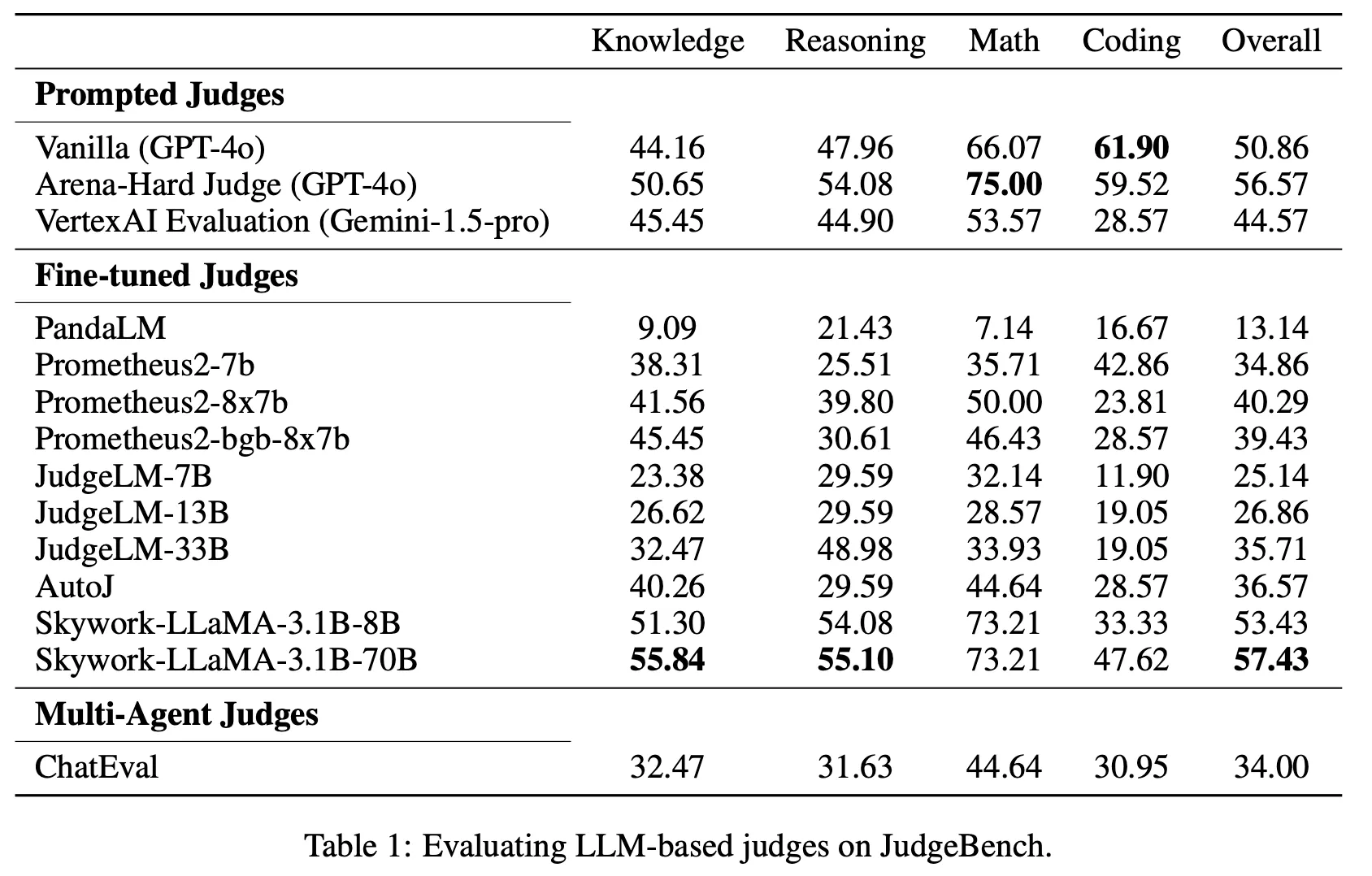
결과
◦
대부분의 모델이 매우 낮은 점수를 보임. 즉, 충분히 어려운 문제임을 확인
◦
예) GPT-4o의 vanilla 프롬프팅은 random guess와 크게 다를바 없는 수준 (50.86)
◦
Fine-tuning 모델들이 전반적으로 낮은 점수를 보임. 주요 원인으로는 아래와 같은 현상이 관찰됨
▪
1) 평가 모델의 Context Length 제한
▪
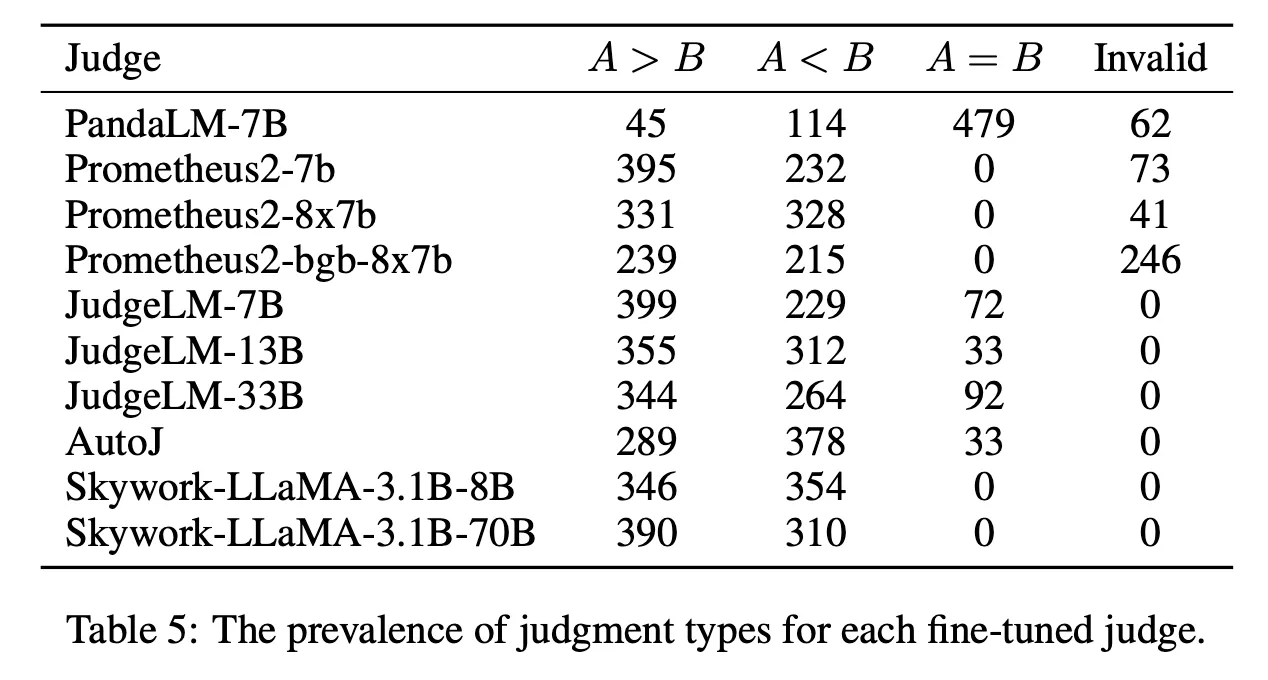
2) Tie 혹은 Invalid한 평가 결과를 출력하는 경우가 꽤 많음 (PandaLM, Prometheus2-bgb 등)
▪
3) 일관되지 못한 평가
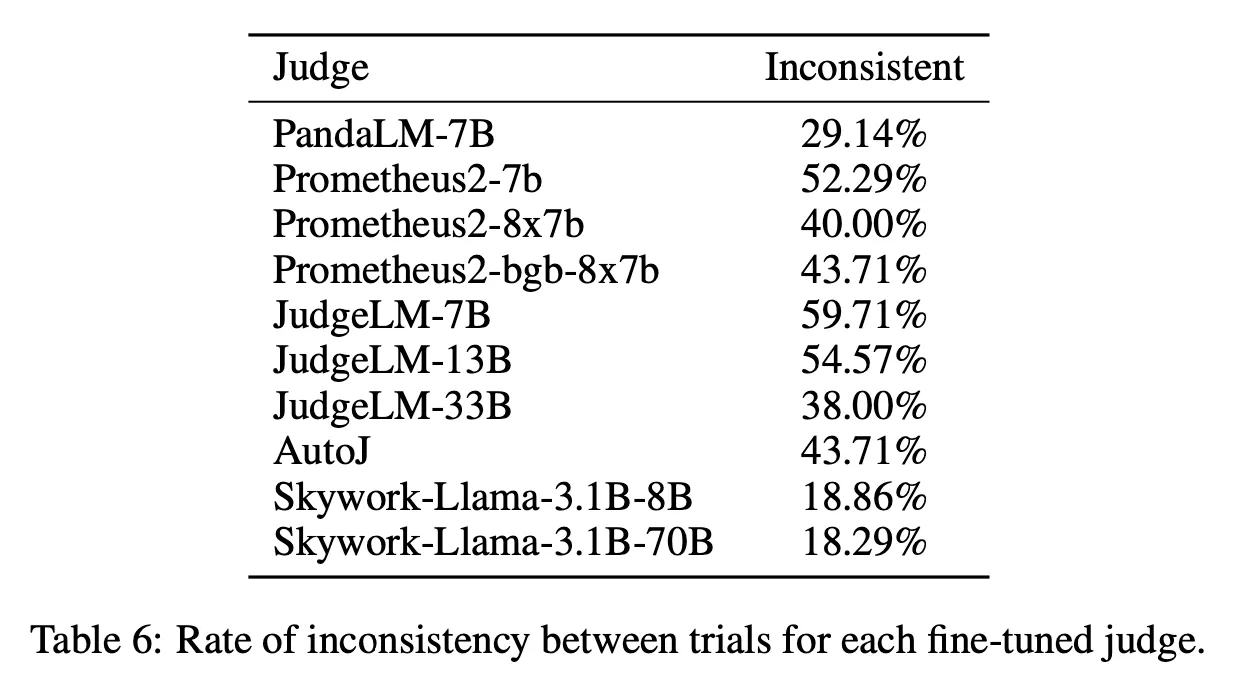
◦
그럼에도 불구하고 파인 튜닝을 통하여 평가 전용 모델을 만드는 것은 매우 효과가 있음
▪
Table 1에서 Skywork와 아래 Table 2에서 Llama-3.1을 비교하면 같은 크기 기준 절대값으로 약 12.6%, 5.1% 향상
▪
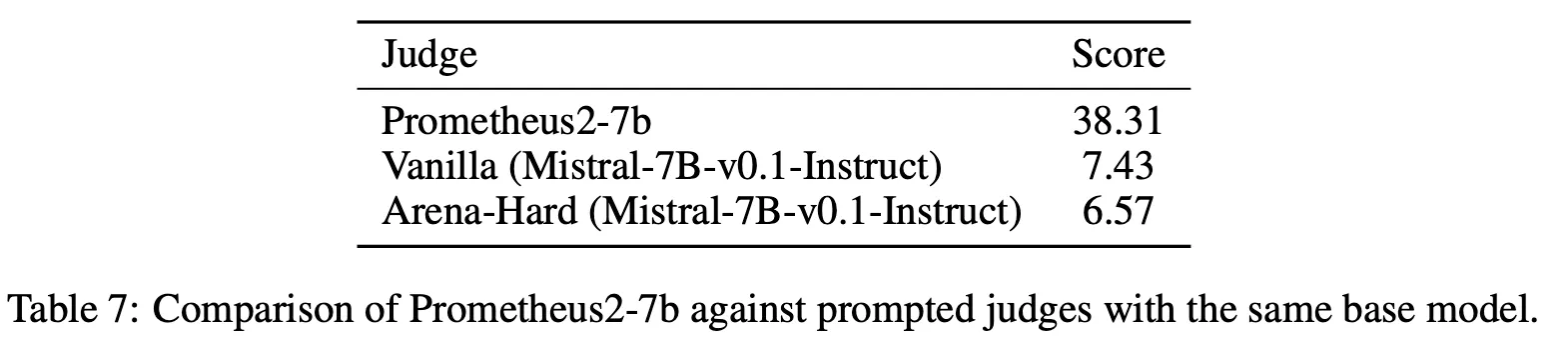
Table 7에서 Prometheus2와 Mistral-7B를 비교하면 절대값으로 30% 이상 향상
•
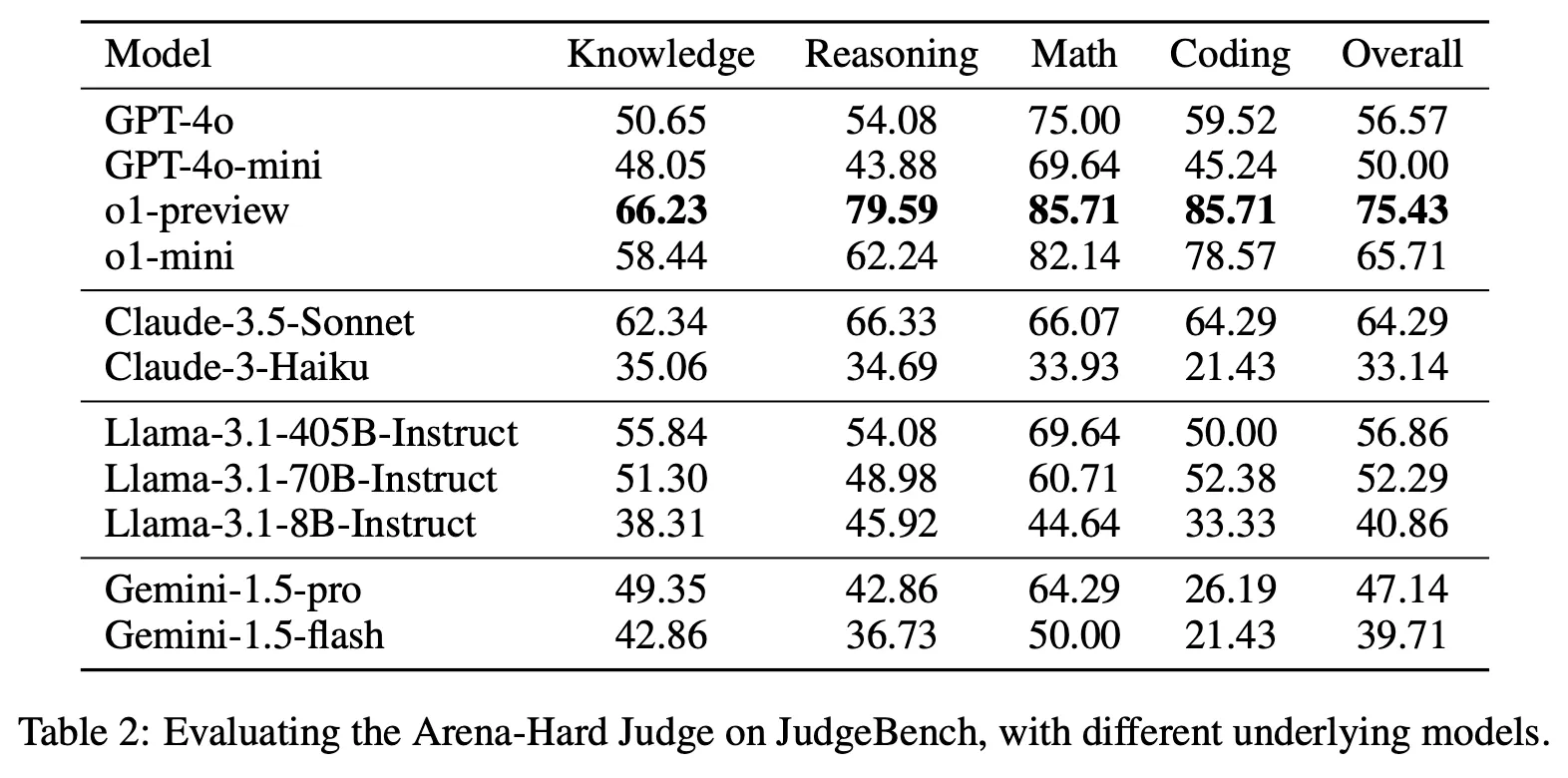
LLM별 평가 능력 비교
◦
Arena-Hard 방식의 프롬프트 사용하여 평가
◦
Reasoning에 특화된 o1 계열의 성능이 가장 뛰어남. 단, single pass로 답변을 도출하는 경우만 비교하면 Sonnet이 가장 우수
•
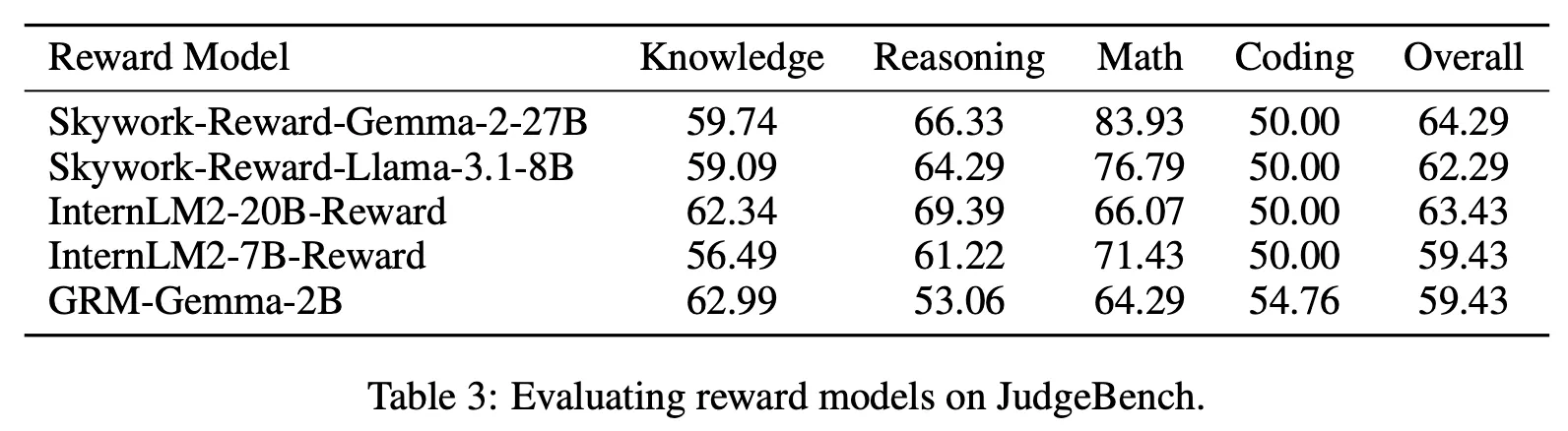
Reward Model 평가
◦
Reward Model은 각 답변에 대한 절대 점수를 출력한 후 더 큰 점수의 답변을 선택하는 방식으로 측정
◦
실험 대상인 Reward Model들이 주요 상위권 LLM의 평가 능력과 거의 비슷하거나 더 나은 수준을 보여줌
Further Analysis
•
주어진 문제를 직접 푸는 것(Solver)과 주어진 답변에서 더 나은 것을 판단(Judge)하는 능력을 비교
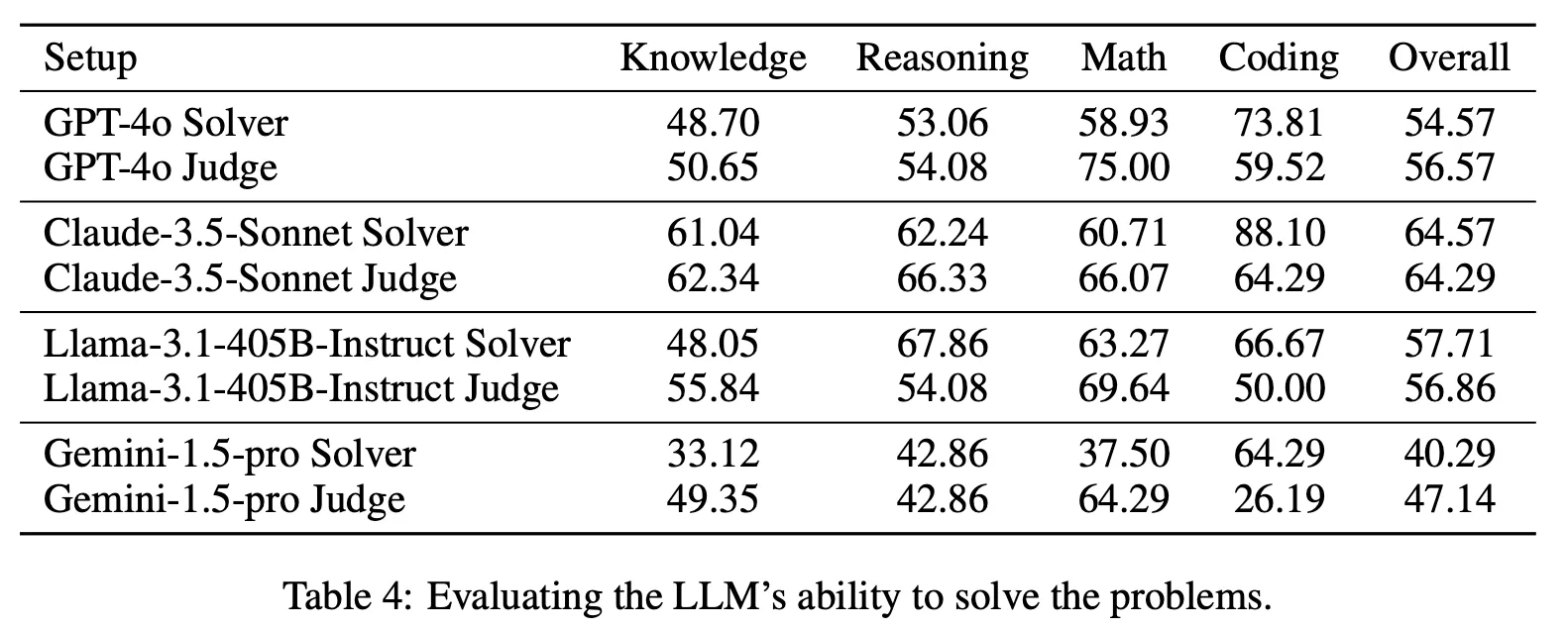
◦
종합 성능에서는 거의 비슷하거나 평가하는 능력이 다소 높음
◦
단, 수학의 경우 압도적으로 직접 푸는 것보다 평가하는 것의 성능이 높으며 코딩의 경우는 정반대 양상을 보여줌
◦
이를 토대로 미루어 볼 때 수학을 평가하는 것은 상대적으로 쉬우나 코딩 문제를 평가하는 것은 매우 어렵다는 것을 알 수 있음
•
데이터 생성에 사용한 LLM의 종류에 따른 bias 분석
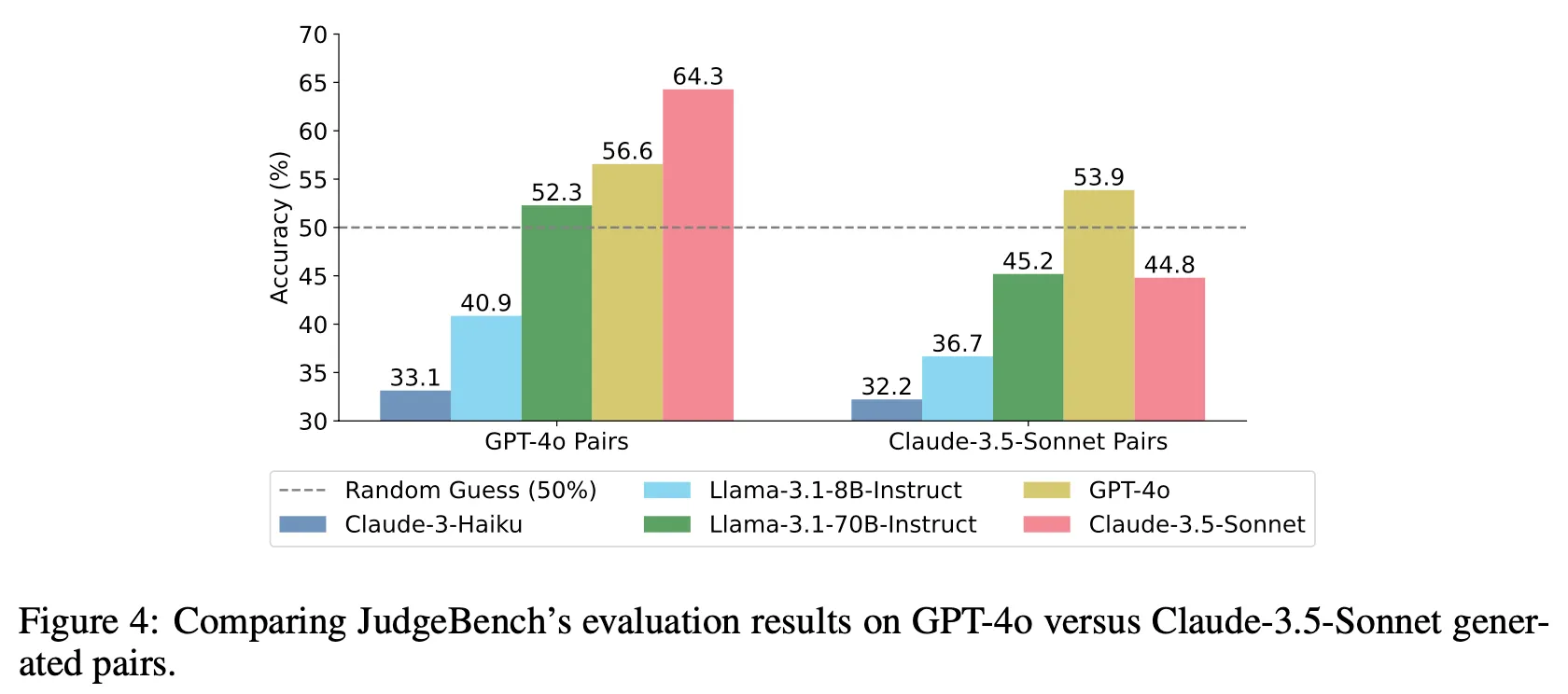
◦
상대적으로 자신이 생성한 데이터를 더 어려워하는 경향이 존재
◦
즉, GPT-4o로 생성한 데이터로 측정하면 GPT-4o 보다 Sonnet의 평가 능력이 더 높으나 Sonnet으로 생성한 데이터를 사용하면 그 경향이 역전됨
◦
추가로 전체적으로 Sonnet이 생성한 데이터에서 더 낮은 성능을 보임. 이는 JudgeBench용 데이터 생성에 있어서 Sonnet 모델이 더 어려운 문제를 만들 수 있다는 것을 의미
◦
즉, 평가 능력 측면에서나 데이터 생성 측면 양쪽에서 Sonnet이 GPT-4o 대비 더 뛰어난 추론 능력을 보인다고 할 수 있음
Discussion
•
앞선 아티클(https://blog.sionic.ai/improve-llm-as-a-judge)에서 언급하였듯, 모델이 생성한 결과를 자동으로 판단하는 능력은 AI가 스스로 똑똑해지고 Safety나 윤리적인 측면 등에서 사람의 가치관과 Align을 맞추는데 매우 중요한 요소임. 따라서 향후 이 방향으로 더 활발한 연구가 진행될 것으로 예상
•
비교적 간단한 방법론으로 난이도 높은 LLM 평가 능력 측정용 벤치마크를 제작했다는 점이 인상적임
•
특히, 데이터 구축 방법이 비교적 간단하여 향후 모델이 발전함에 따라 계속 비슷한 방식으로 다양한 벤치마크 데이터를 생성할 수 있다는 점도 의미 있음
•
다만 이 벤치마크는 두 개의 답변 중 더 나은 것을 선택하는 Preference 문제에만 초점을 맞추고 있으며, 답변의 절대적인 품질은 고려하지 않음