

도입
•
LLM의 능력은 매우 뛰어나며 많은 Task에서 사람을 뛰어 넘는 모습을 보여주고 있음
•
그렇지만 사람처럼 다른 사람과의 Interaction을 통하여 배우고 경험을 쌓으며 전문가로 성장하는 능력에 대한 탐구는 아직 부족함. 이것이 AI가 실제 업무 및 비즈니스에 적용되는데 어려움을 겪는 주요 원인 중 하나라 판단
•
이 아티클에서는 이처럼 사람과의 Interaction을 통하여 점차 배우고 똑똑해지는 방법에 대한 사례를 소개
•
개요
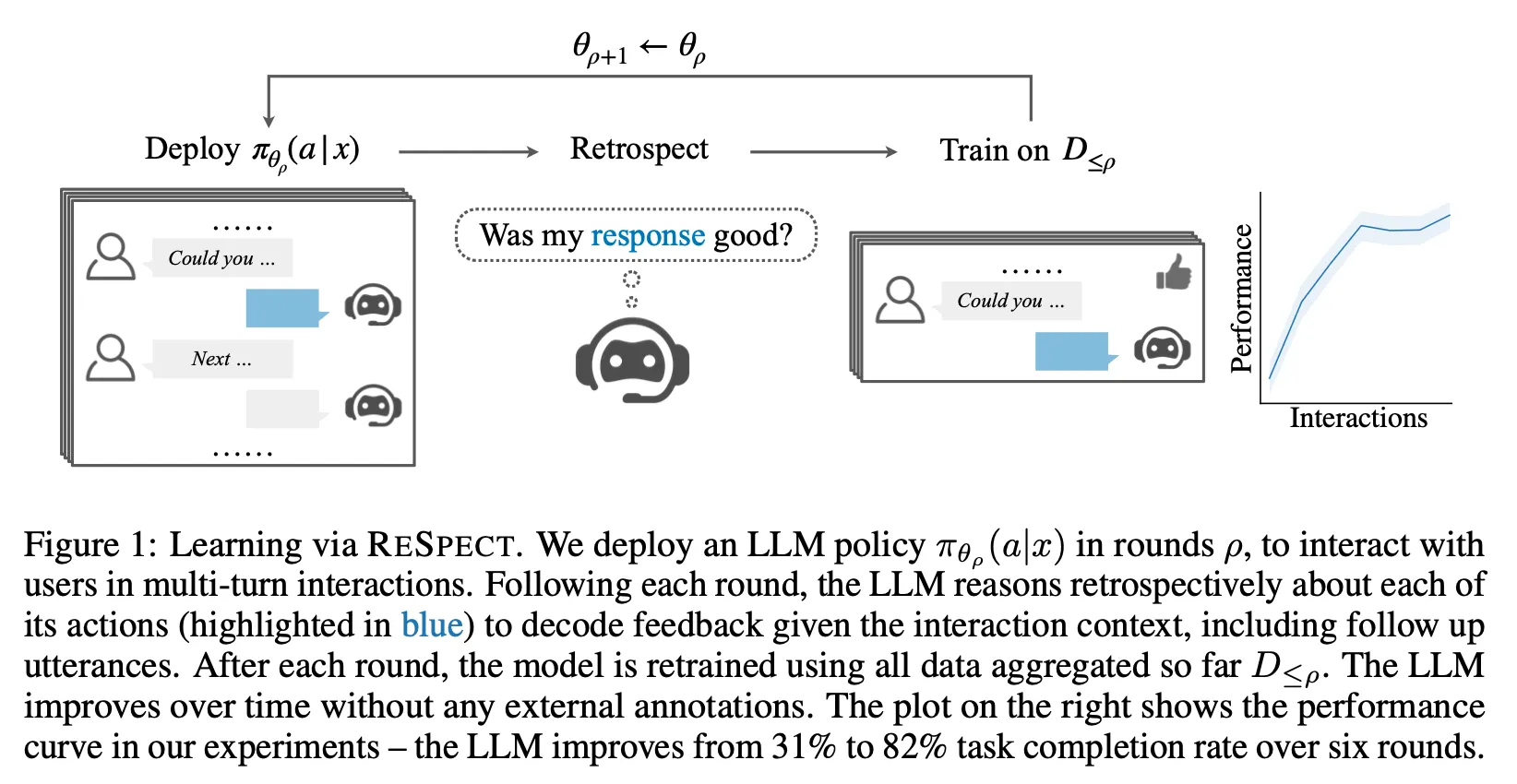
•
요약 : 대화형 Agent에서 멀티턴 대화를 하면서 사람의 반응으로부터 피드백을 추출하고 이것을 학습하여 Task 수행 성공률을 31%에서 82%로 향상
•
Tangram 퍼즐을 바탕으로 여러 턴의 대화를 통하여 Speaker가 요청하는 모양을 Listener가 맞추는 Task인 MultiRef 데이터를 제작
•
이전 Interaction과 Speaker의 반응을 토대로 Feedback을 추출하여 성능을 개선시키는 ReSpect 방법론을 제안하였으며, 제작한 MultiRef 데이터에서 그 효과를 입증함
Method
•
대상 Task : MultiRef
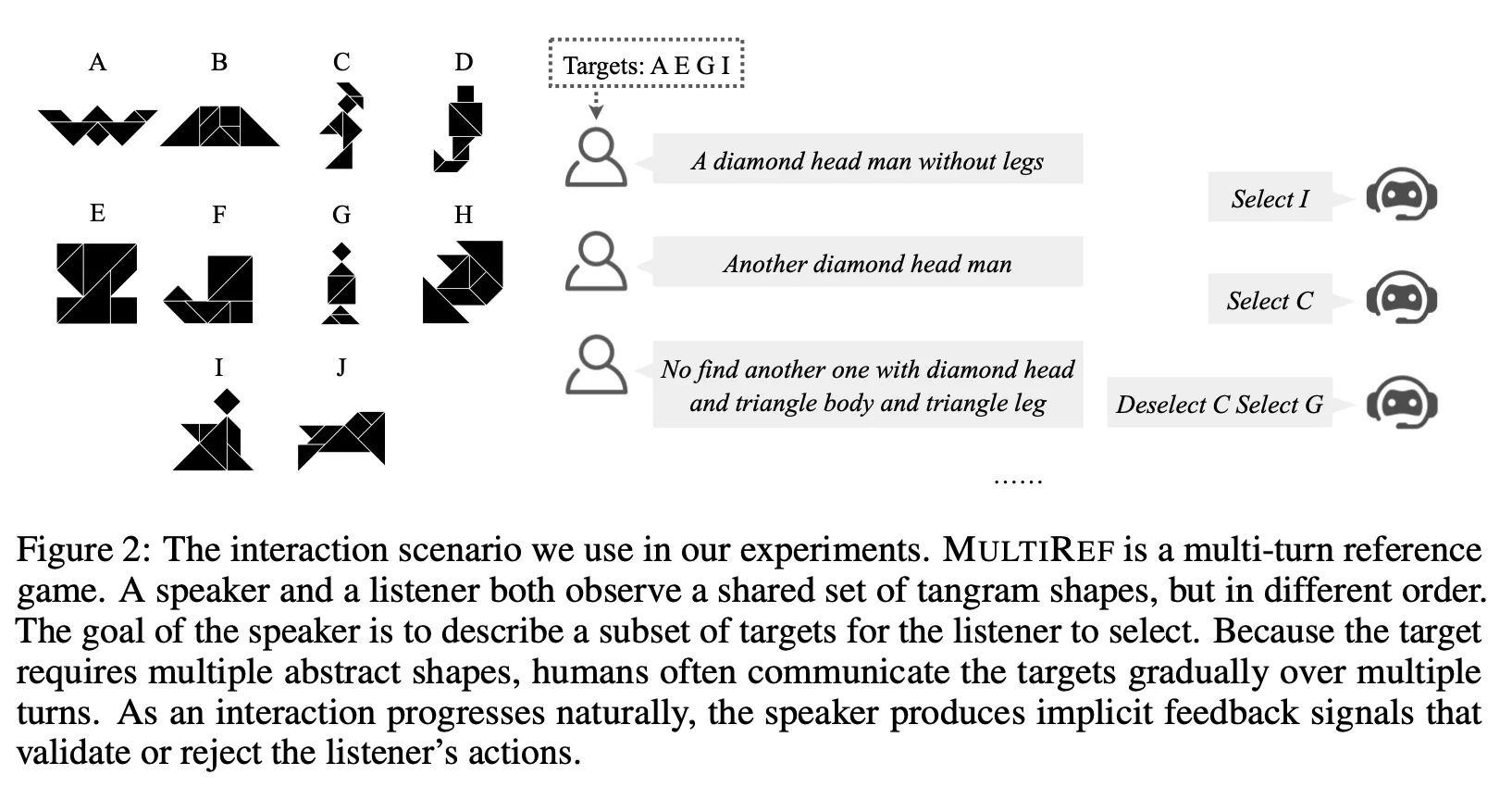
◦
Multi-turn Grounded Interaction Scenario
◦
2명의 화자(문제를 내는 Speaker와 문제를 맞추는 Listener)가 존재. 이 연구에서 Speaker는 항상 사람이며 Listener는 항상 AI Agent가 담당
◦
Tangram을 활용한 다양한 모양 중 Speaker가 설명하는 것을 Listener가 맞추는 방식으로 대화가 이어짐.
◦
Metric
▪
Interaction 성공률 : 성공적인 Interaction의 비율. 이 때 10턴 이내로 Listener가 의도한 모든 모양을 맞춘 경우 성공으로 판단함
▪
Interaction 당 턴 수 : 각 Interaction 별로 진행한 평균적인 대화 턴 수
▪
Exact Match : 전체 턴 중 모델의 행동이 사람 평가자가 레이블링한 행동과 일치하는 턴의 비율
▪
Similarity : 정답 Action과 실제 Action과의 유사도. 유사도는 아래와 같이 정의하며, 이 때 은 모델이 선택한 Action, p는 select, q는 deselect를 의미. 는 정답 Action을 의미함

▪
Positive Feedback : 전체 턴 중 Positive Feedback을 받은 턴의 비율
▪
Click Accuracy : 전체 행동(Select / Deselect) 중 정답에 기여하는 행동(타겟을 Select하기, 타겟이 아닌 것을 Deselect하기)의 비율

•
ReSpect
◦
2가지 단계로 구성 : 1) 다음 턴 Speaker의 반응을 보고 Implicit Feedback을 예측, 2) 추출한 Feedback을 활용하여 학습
◦
Implicit Feedback을 예측
▪
LLM에 다음과 같은 프롬프트를 입력하여 긍정/부정(혹은 긍정/부정/중립) 여부를 판단

◦
학습
▪
Supervised Learning : 긍정 피드백을 받은 데이터만 모아서 튜닝
▪
Reinforcement Learning : REINFORCE, KTO 등의 방법으로 수집한 피드백 데이터를 대상으로 RL 수행
Results
•
총 실험 대상 : 총 6가지
◦
Feedback 종류에 따른 분류 : Binary(B) / Tenary(T)
◦
학습 방법에 따른 분류 : Supervised(Sup), REINFORCE(RL), KTO
•
매 라운드마다 330개 Interactions, 대략 2400턴으로 구성된 데이터를 적용하여 평가 및 학습에 활용
•
대화 Example

•
Main Result
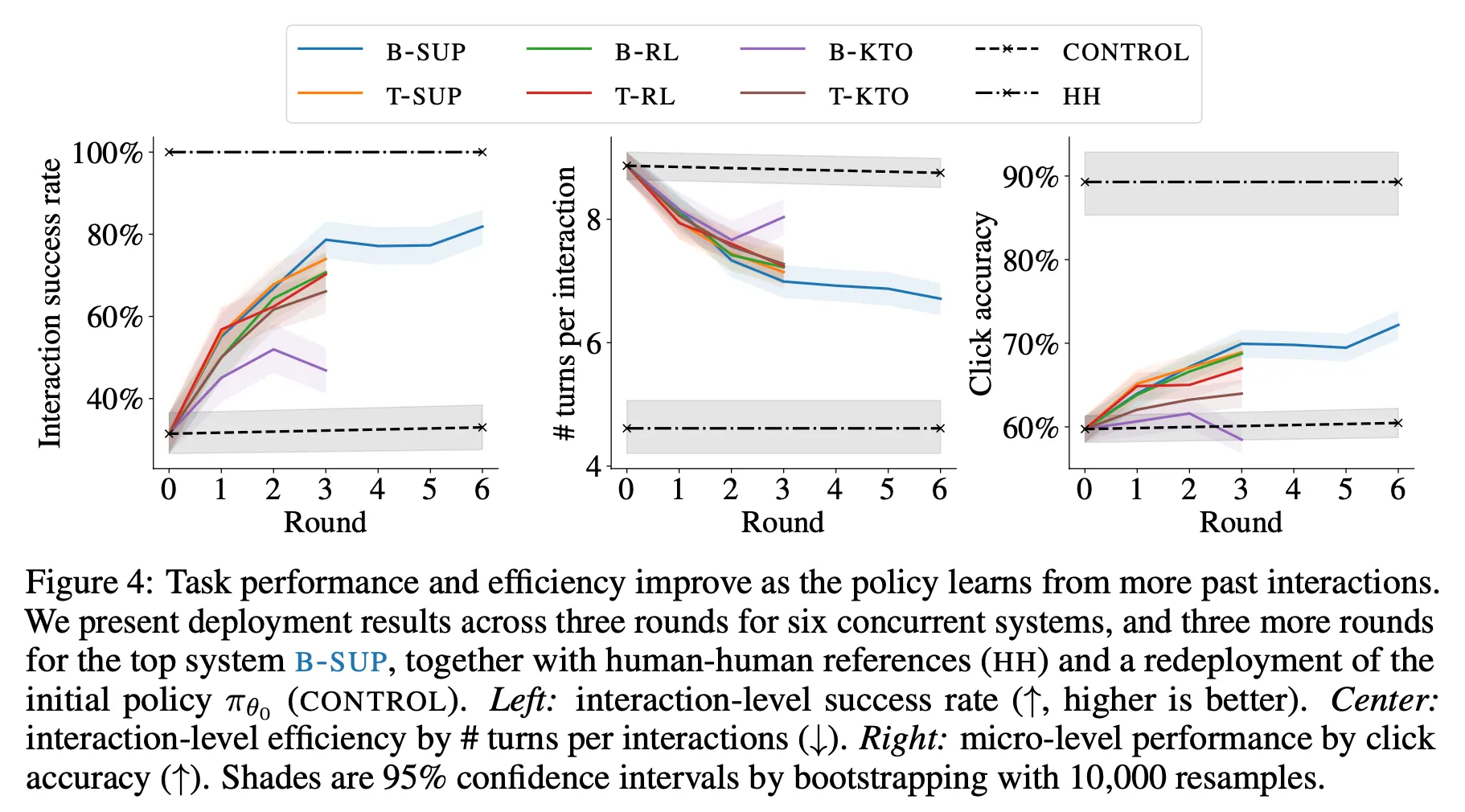
◦
3라운드까지 가장 좋은 성능을 보인 B-Sup에 대해서 추가로 3라운드를 더 수행하여 경향을 관찰
◦
라운드가 거듭될수록 성능이 향상(B-KTO 3라운드 제외) : 성공률 향상, 평균 턴수 감소, click accuracy 증가 등
◦
Supervised > RL > KTO
◦
Binary와 Tenary는 학습 방법에 따라 경향이 다름. 즉, 어느 쪽이 항상 더 좋다고 말하기 애매함
◦
턴별 성능을 살펴봐도 유사하게 라운드에 따라 향상하는 모습이 관찰됨
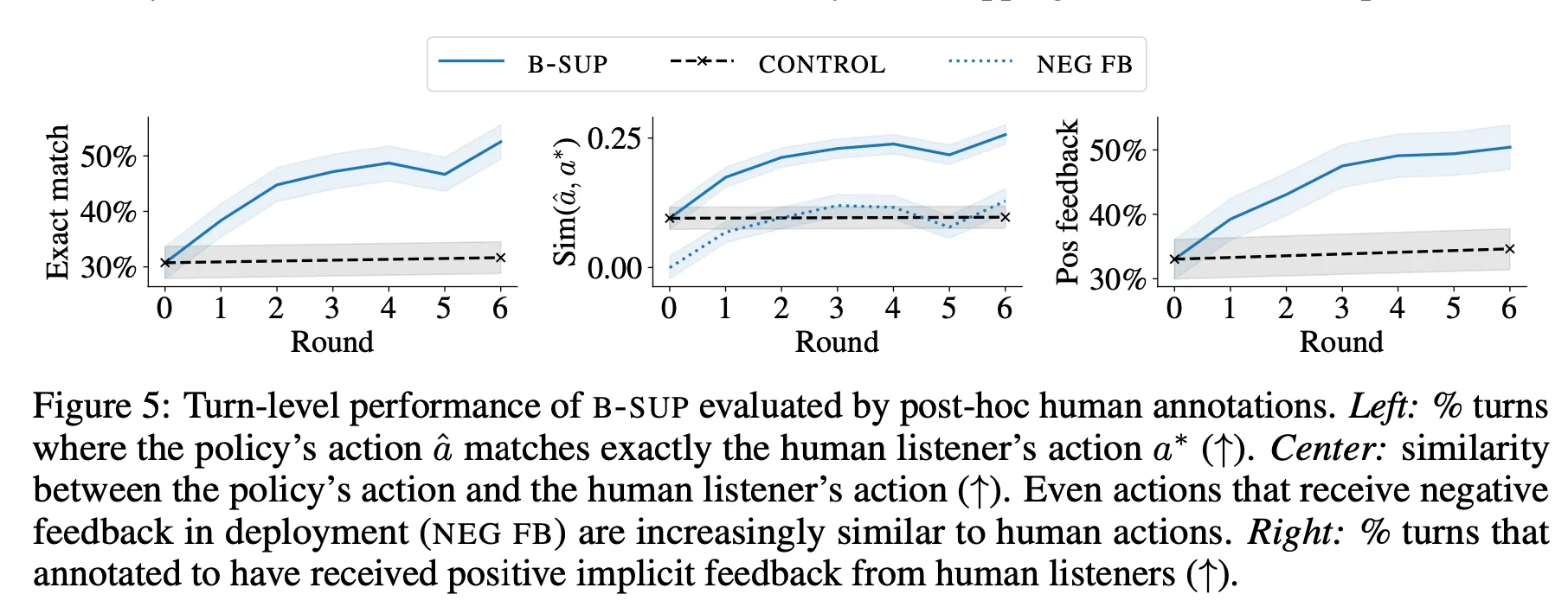
Further Analysis
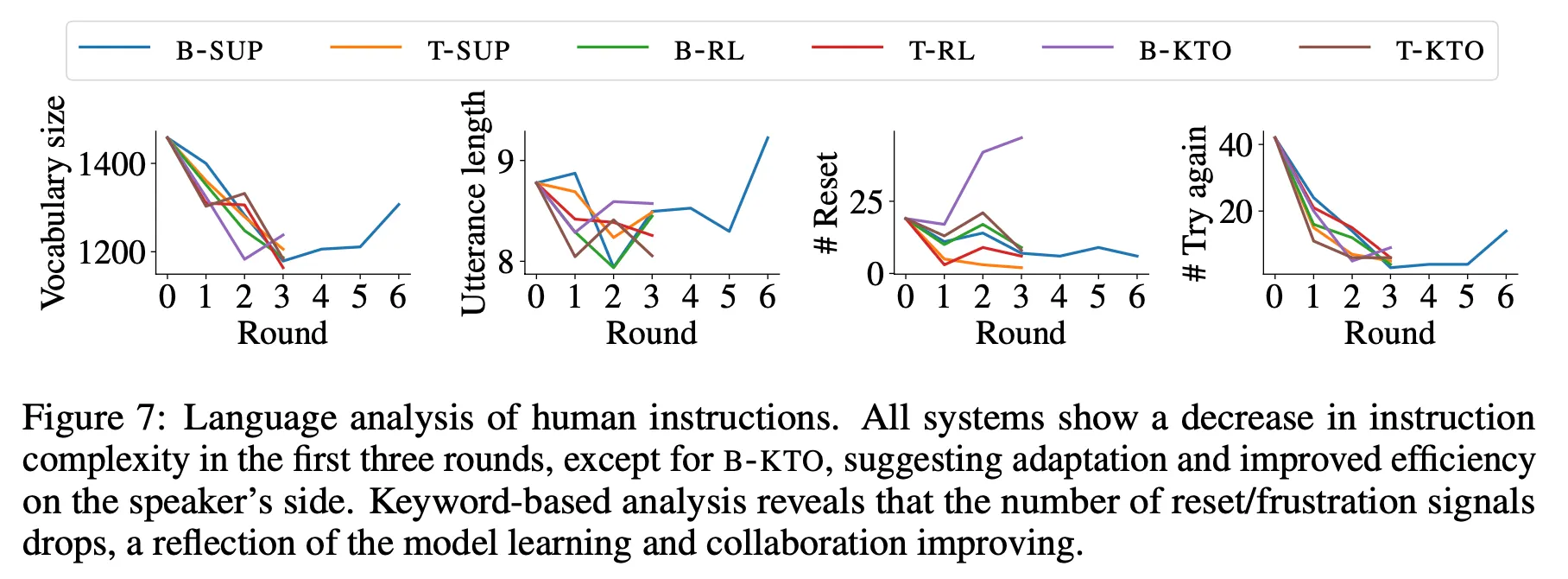
•
3라운드까지는 사용하는 단어의 개수, 발화의 길이, Reset 횟수, 재시도 횟수 등이 감소하는 경향을 보임.
•
이는 모델이 Task에 적응하면서 한번에 보다 정확한 결과를 만들기 때문인 것으로 해석 가능
•
그렇지만 B-Sup을 6라운드까지 진행할 때는 오히려 몇몇 수치(단어 개수, 발화 길이, 재시도 횟수 등)가 증가하는 예상치 못한 경향이 나타남
Discussion
•
검색 시스템에서 사용하는 Implicit Relevance Feedback(IRF)은 유저의 행동으로부터 피드백을 추출하여 검색 결과를 개선하는데 활용하는 방법으로 현재 검색 엔진에 널리 적용되어 있음
•
그렇지만 대화형 Agent에서는 아래와 같은 이슈로 IRF의 적용이 그다지 성공적이지 못했음
◦
사용자의 응답으로부터 어떤 eFedback을 어떻게 추출하는지 이슈
◦
추출한 피드백을 어떻게 응답 성능 개선에 활용하는지 이슈
•
LLM의 뛰어난 추론 능력과 최근 발전하는 Preference Learning 기법들을 활용하여 대화형 Agent에서 IRF를 추출하고 활용하는 한 가지 방향을 제시하였다는 측면에서 의의가 있다고 판단
•
다만 방법론 자체는 단순한 편으로 개선의 여지가 많이 존재하며, 게다가 저자들이 생성한 Task 대상으로만 실험을 했으므로 보다 범용적인 Task에 대한 유효성 검증은 필요하다고 생각함