

도입
•
LLM이 가진 한계 (최신 정보 부족, Private 데이터에 대한 지식이 없음 등)를 극복하고 기업이 내부 데이터를 활용하여 LLM 기반 어플리케이션을 만들 수 있는 가장 유망한 방법으로 최근 Retrieval-Augmented Generation(RAG) 방법을 널리 활용하고 있으며, 이에 따라 주어진 질의 해결에 적합한 문서를 검색해오기 위한 뛰어난 Embedding Model에 대한 관심이 점차 높아지고 있음
•
그러나 고객이 사용하는 데이터는 단순 Text로만 이루어진 것이 아니라 다양한 형태의 이미지를 처리하고 이해해야 하는 경우가 많으며, 따라서 이미지와 텍스트를 동시에 이해할 수 있는 Multi-modal Embedding Model이 필요함
•
이 아티클에서 소개할 E5-V는 LLM을 통하여 Text Embedding Model을 만드는 방법을 확장하여 Vision Language Model(VLM)으로부터 Multi-modal Embedding Model을 만드는 방법을 제안하고 있음
•
개요
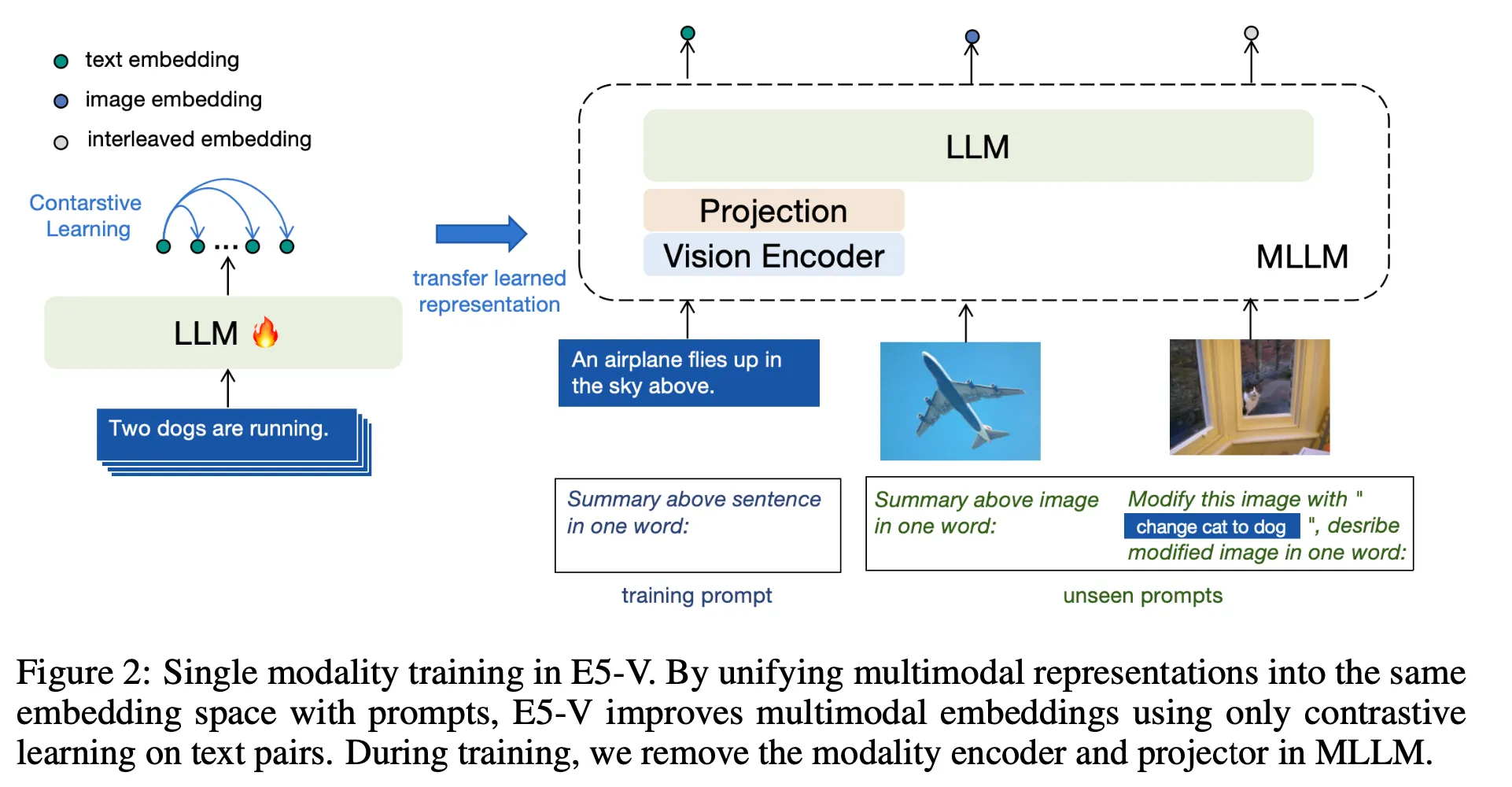
•
한줄 요약 : 기존에 존재하는 VLM을 활용하여 Image-text Paired 데이터가 아닌 텍스트 데이터로만 파인튜닝하여 뛰어난 Multi-modal Embedding Model을 만들 수 있음
•
LLM 기반으로 embedding model을 만들 때 최근 널리 사용하는 방식(https://arxiv.org/abs/2307.16645)을 확장하는 방법을 제안. 입력 텍스트 혹은 이미지 등을 넣고 적절한 프롬프트를 붙인 후 마지막 Token의 Hidden Representation을 Embedding Vector로 사용하는 방식
•
텍스트 데이터만 사용한 Contrastive Learning으로 파인튜닝했을 때 충분히 뛰어난 Multi-Modal Embedding Model을 만들 수 있음을 보여준 점이 주요 Contribution이라고 생각
•
Text-image Retrieval, Image-image Retrieval, Text Embedding 측면에서 모두 SOTA이거나 SOTA 에 비견되는 뛰어난 성능을 보여줌
Method
•
백본 모델 : LLaVA-NeXT-8B (LLaMA-3-8B + CLIP ViT-L), 뒤에 ablation study를 위해 Phi-3, LLaVA-1.6B (Mistral) 도 사용
•
학습
◦
데이터 : NLI, 273k Sentence Pairs
◦
방법 : Constrastive Learning, QLoRA, 768 Batch Size, 1000 Steps
◦
Prompt : "<text> \n Summary above sentence in one word:". <text>에 변환할 입력 문장이 들어가가며 마지막 토큰의 Hidden Representation을 Embedding Vector로 학습
Results
•
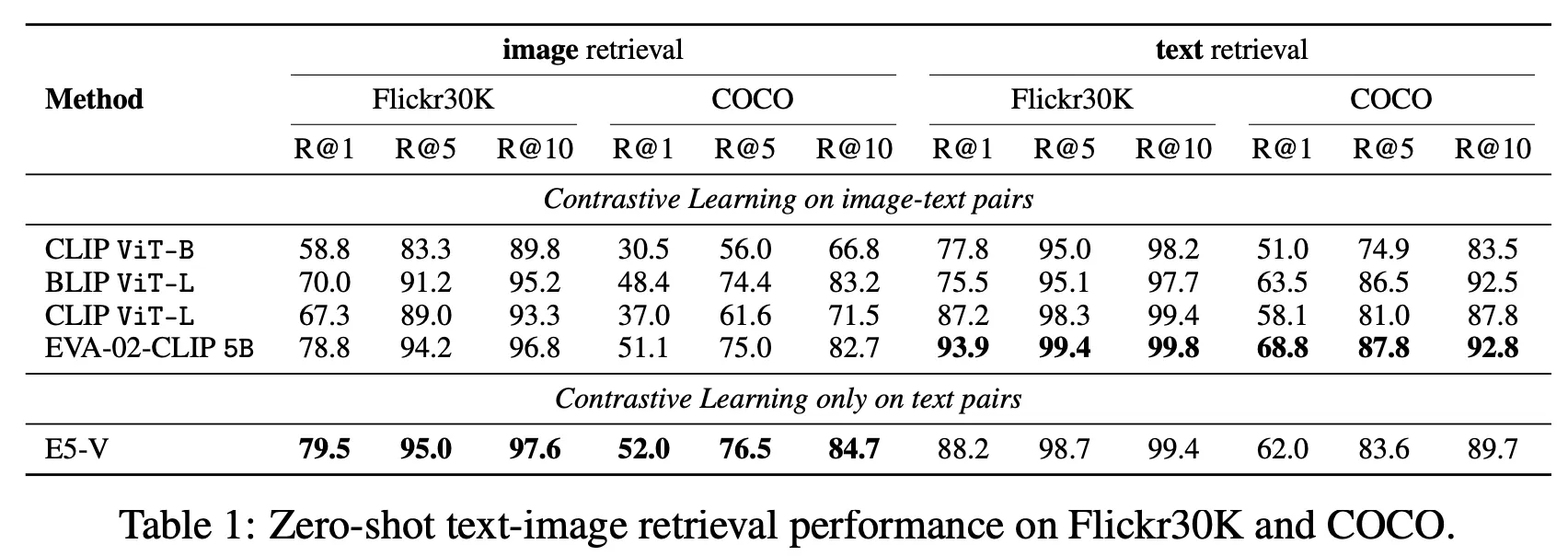
Text-image Retrieval
◦
Zero-shot Image Retrieval과 Text Retrieval 성능 측정
◦
비교 대상 모델 대비 꽤 괜찮은 성능을 보여줌
▪
EVA-02-CLIP 5B의 경우 4.4B 크기의 Image Encoder를 사용하며 대량의 Image-text Pairs 데이터로 튜닝한 모델
▪
반면 E5-V의 경우 CLIP ViT-L 수준의 Image Encoder를 사용
◦
사용한 벤치마크 데이터 : Flickr30K, COCO
◦
Prompt

◦
Performance
•
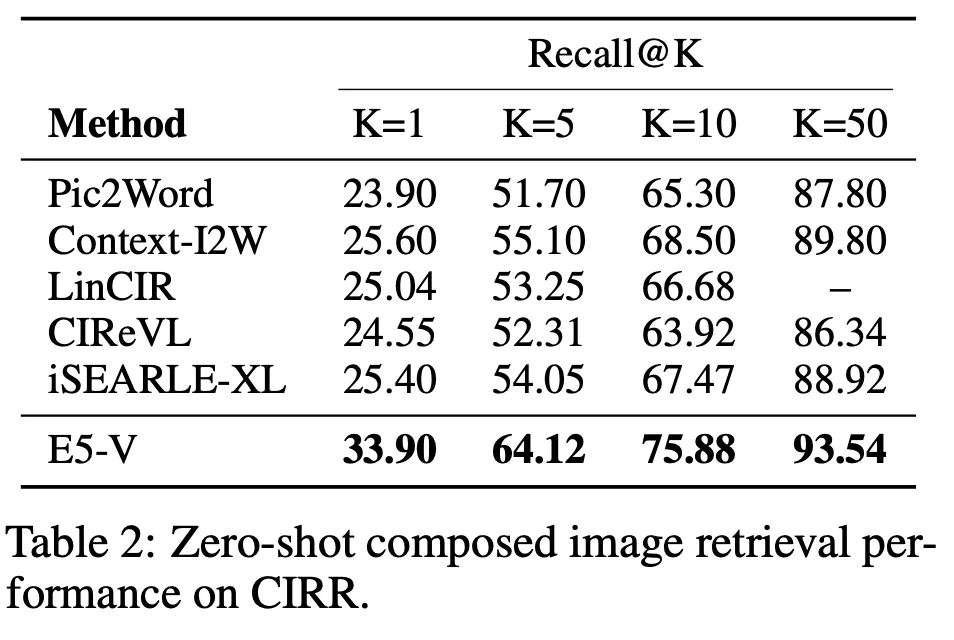
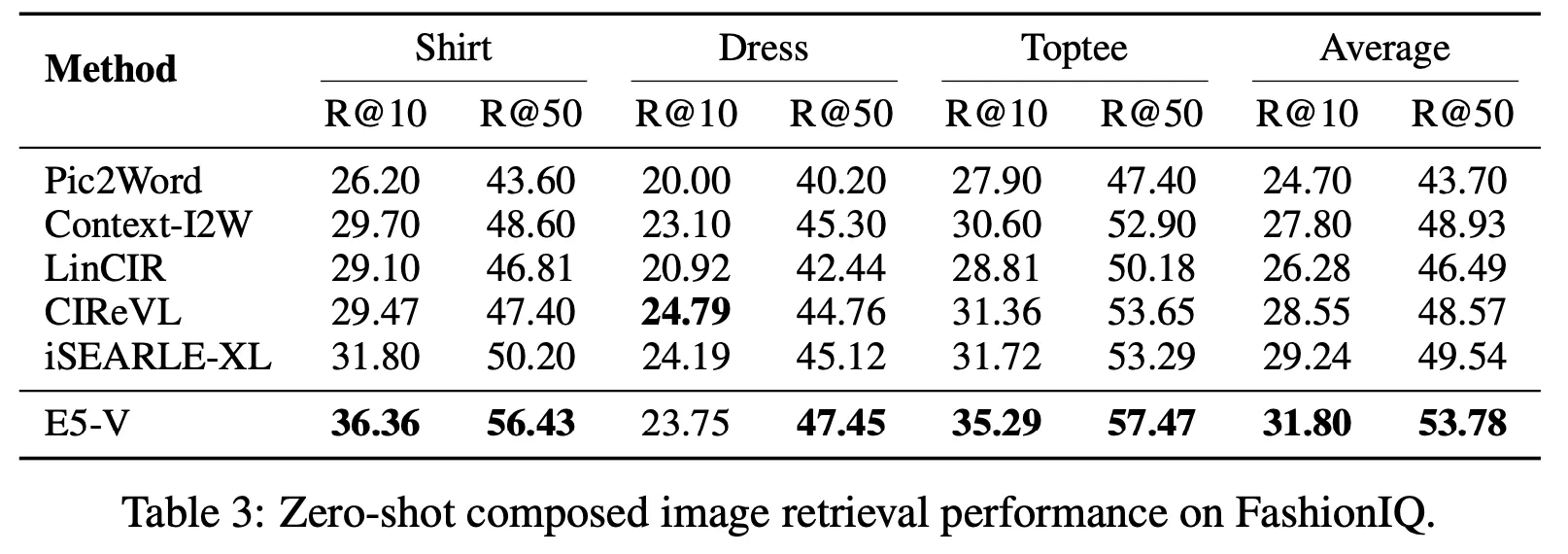
Composed Image Retrieval
◦
원본 이미지와 텍스트로 표현된 지시문(이미지 중 어떤 부분을 수정하라는 내용)을 입력으로 받음. 수정의 결과와 가장 비슷한 최종 이미지를 검색하는 문제
◦
비교 대상 모델 대비 거의 모든 점수에서 가장 뛰어난 성능을 달성
◦
사용한 벤치마크 데이터 : CIRR, FashionIQ
◦
Prompt

◦
Performance
•
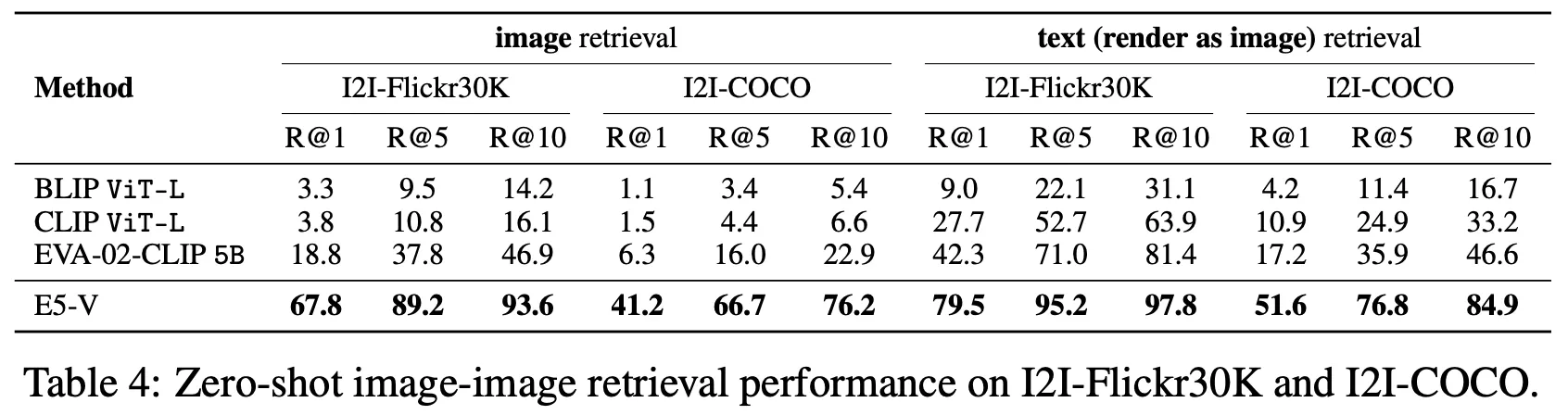
Image-Image Retrieval
◦
Text-Image Retrieval 문제에서 Text 부분을 아래와 같이 이미지로(Arial font with 40 pixels, 800x400 resolution) 만든 후 동일한 task 수행

◦
비교 대상 모델은 이미지로 된 텍스트를 제대로 이해하지 못하였으나 E5-V의 경우 텍스트 입력을 사용했을 때 대비 약 80~90% 정도 수준으로 꽤 효과적인 모습을 보여줌.
◦
사용한 벤치마크 데이터 : CIRR, FashionIQ
◦
Prompt : "<image> \n Summary above image in one word:"
◦
Performance
•
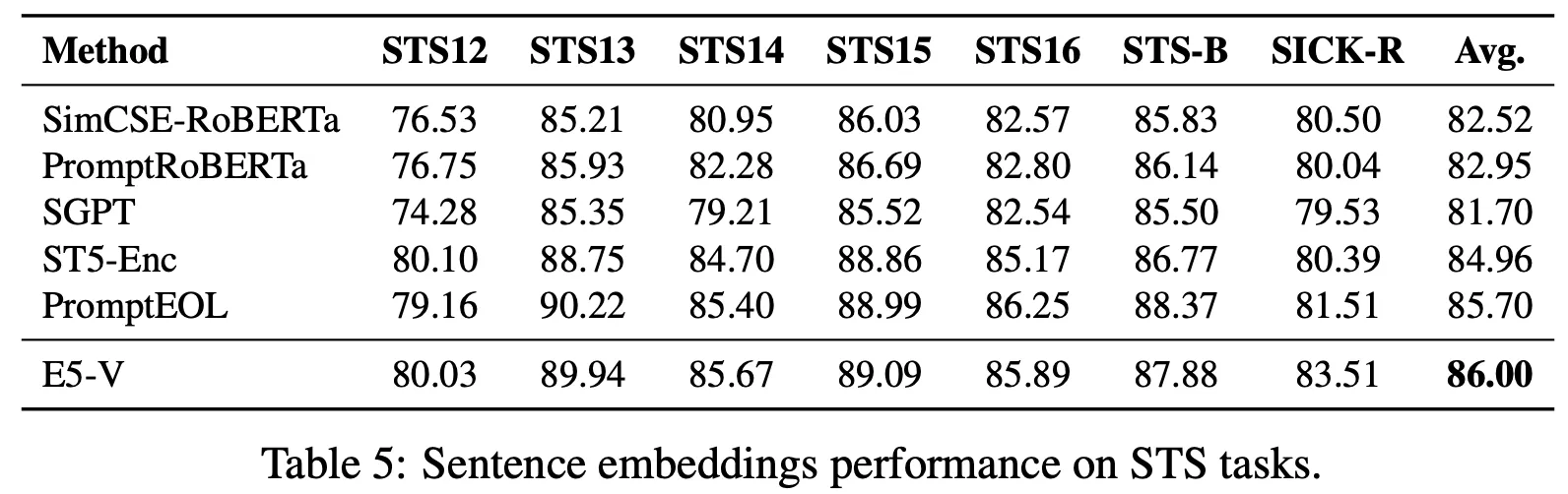
Text Sentence Embeddings
◦
사용한 벤치마크 데이터 : STS
◦
Prompt : "<text> \n Summary above sentence in one word:"
◦
Performance
◦
참고) MTEB 상위권 모델들과의 STS 성능 비교
모델명 | STS12 | STS13 | STS14 | STS15 | STS16 | SICK-R | Avg. |
E5-V | 80.03 | 89.94 | 85.67 | 89.09 | 85.89 | 83.51 | 85.69 |
stella_en_1.5B_v5
(24.7.25 현재 1위) | 80.09 | 89.68 | 85.07 | 89.39 | 87.15 | 82.89 | 85.71 |
voyage-lite-02-instruct
(STS 쪽 1위) | 86.46 | 87.76 | 86.6 | 90.1 | 86.39 | 78.44 | 85.96 |
google-gecko.text-embedding
(Google) | 77.59 | 90.36 | 85.25 | 89.66 | 87.34 | 81.93 | 85.36 |
sfr-embedding-mistral
(Salesforce) | 79.47 | 89.15 | 84.93 | 90.74 | 87.82 | 82.92 | 85.84 |
e5-mistral-7b-instruct | 79.66 | 88.43 | 84.54 | 90.43 | 87.68 | 82.64 | 85.56 |
NV-Embed-v1
(Nvidia) | 76.22 | 86.3 | 82.09 | 87.24 | 84.77 | 82.8 | 83.24 |
Cohere-embed-english-v3.0
(Cohere) | 74.37 | 85.2 | 80.98 | 89.23 | 84.67 | 81.27 | 82.62 |
text-embedding-3-large
(OpenAI) | 72.84 | 86.1 | 81.15 | 88.49 | 85.08 | 79.00 | 82.11 |
Further Analysis
•
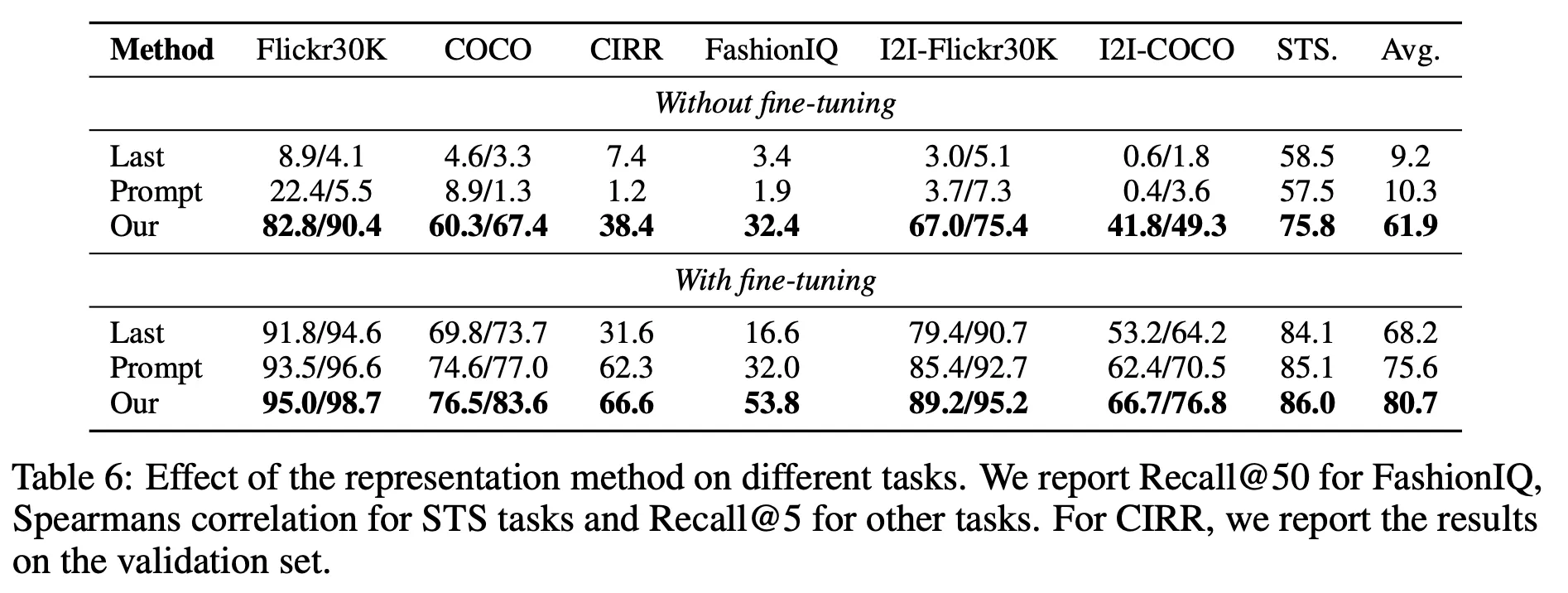
Tuning 및 프롬프트에 따른 성능 분석
◦
어떤 프롬프트를 사용하는지에 매우 민감한 모습을 보임

◦
현재 사용하는 프롬프트는 별도 파인튜닝을 하지 않아도 어느 정도 Representation 능력이 존재하나 비교 대상 다른 두 방법은 현저히 저하됨
◦
파인튜닝하면 세 방법 모두 꽤 높은 수준으로 성능이 향상되지만 제안하는 프롬프트가 가장 효과가 좋음
◦
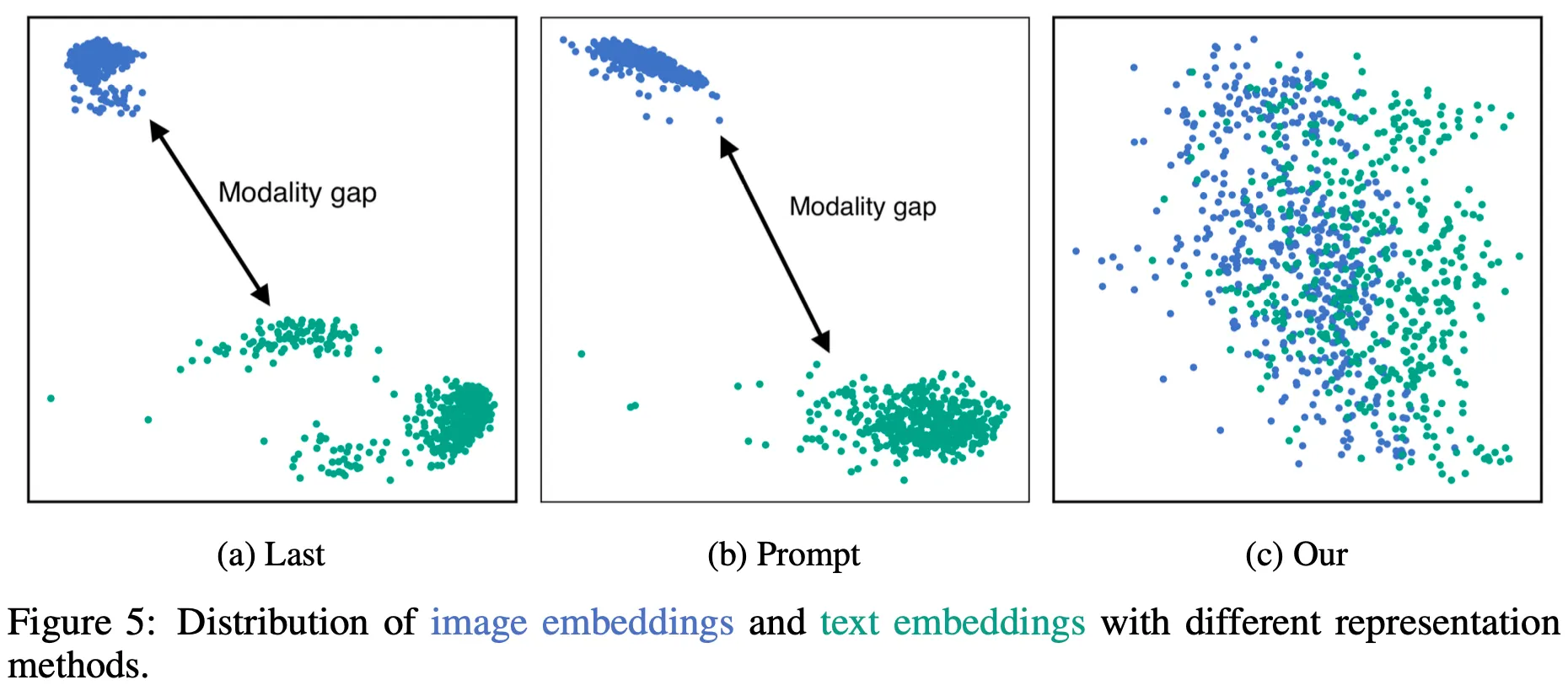
Embedding Vector의 분포를 살펴보면 비교 대상의 다른 2가지 방법은 텍스트와 이미지의 Embedding이 여전히 따로 놀고 있으나 제안 방법은 잘 섞여 있는 것을 확인할 수 있음
◦
이는 LLM의 뛰어난 Instruction Following 능력을 적절히 잘 활용할 수 있는 프롬프트를 사용하기 때문인 것으로 보임
◦
또한, 그렇기 떄문에 적절한 프롬프트를 사용하여 다양한 케이스에 대한 좋은 Multi-modal Embedding을 생성하는 일반화 능력이 존재한다고 볼 수 있음
•
Single Modality Training 효과 분석
◦
비교 대상 Multi-modal 학습 데이터 : CC3M 558K text-image pairs
◦
텍스트에 대해서만 튜닝한 것이 학습 시간도 거의 4% 수준(34.9h vs 1.5h; V100 32장 기준)이고 성능도 더 뛰어남

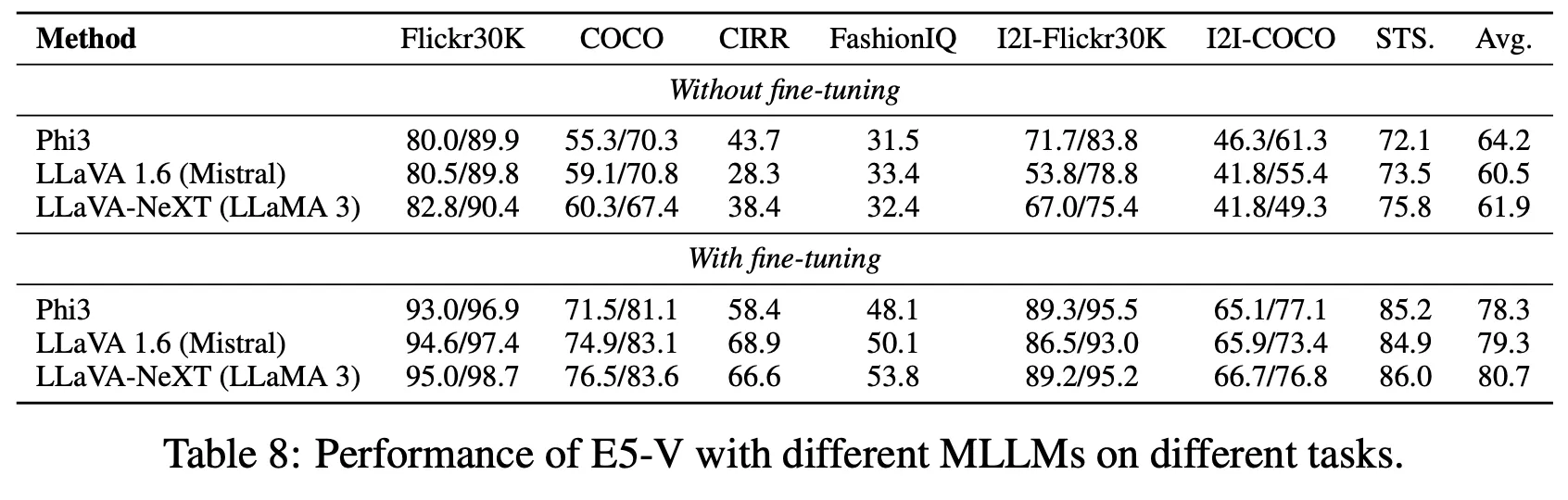
•
사용 백본 모델에 따른 성능 비교
◦
비교 대상 모델 모두에서 제안 방법의 효과를 확인
Discussion
•
최근 Foundation Model의 연구 방향이 LLM에서 Multi-modal LLM으로 중심이 넘어간 것과 마찬가지로 Embedding Model의 경우에도 Multi-modal Embedding에 대한 관심이 점차 커지고 있는 추세임
•
특히 이미 뛰어난 능력을 가진 Visual Foundation Model의 능력을 활용할 수 있는 방법론은 앞으로도 계속 각광을 받을 것으로 판단하며, E5-V에서 제안한 텍스트 데이터만으로 파인튜닝하여 고품질의 Multi-modal Embedding을 만들 수 있는 방법은 꽤 의미가 있고 흥미로운 접근이라 생각함
•
다만, 텍스트의 경우에도 LLM 기반의 Embedding은 모델이 크고 연산하는데 비용 및 시간이 많이 걸리는 단점이 있어서 실용적인 측면에서 여전히 의문이 존재하는 상황으로 E5-V와 같은 방법에서도 동일한 문제가 존재함
•
따라서 VLM을 활용한 연구와 Encoder 계열의 경량 모델의 연구가 당분간은 동시에 진행될 것으로 예상함