



Abstract
•
ModernBERT는 2023년 12월의 MosaicBERT 코드베이스를 다음과 같이 개량해서 공개한 모델이라고 할 수 있다.
1.
초대규모 2조(2 trillion) 토큰 사전학습
•
MosaicBERT가 수십~수백억 단위의 C4 데이터를 1~2 epoch로 학습하던 것에 비해, ModernBERT는 훨씬 더 큰 규모(2T 토큰)로 사전학습하여 모델의 언어적, 도메인적 범위를 크게 확장.
2.
코드(Code) 데이터 포함
•
MosaicBERT는 주로 일반 텍스트(C4 등)에 맞춰 최적화되었으나, ModernBERT는 코드 토큰까지 함께 학습해 프로그래밍-related 태스크(예: code retrieval, StackOverflow QA 등)에서 높은 성능.
3.
더 긴 문맥 길이(최대 8192 토큰) 기본 지원
•
MosaicBERT가 최대 128~512 단위로 report 했는데, ModernBERT는 처음부터 8192 토큰 길이를 타겟으로 로컬-글로벌(Local-Global) attention 및 RoPE를 적용해 긴 문맥 상황에서 효과적.
Introduction
•
BERT(Devlin et al., 2019)가 등장한 뒤, NLP의 여러 응용 분야에서 인코더(encoder)-기반 트랜스포머 모델이 큰 인기를 얻었다.
•
이후 GPT, Llama, Qwen 등 디코더(decoder)-기반의 대규모 언어 모델(LLM)이 주목받고 있으나, 여전히 인코더-only 모델은 비생성(generative)이 아닌 다양한 다운스트림 태스크(검색, 분류, NER 등)에서 널리 활용되고 있다.
•
상대적으로 낮은 추론 비용과 효율적인 문서 처리가 가능하여 대규모 문서 집합에 대한 검색(IR)이나 신속한 분류 작업에 적합하다.
•
인코더 모델은 크기 대비 좋은 성능(quality vs. size tradeoff) 을 제공하기 때문에, 데이터 규모가 클수록 인코더-decoder나 디코더-only 모델보다 이점이 있다.
•
인코더 모델은 검색(semantic search) 분야에서 핵심 기술로 자리잡고 있으며, 최근 LLM의 인기에도 불구하고, RAG(Retrieval-Augmented Generation) 파이프라인에서 LLM과 결합하여 문맥을 제공해주는 용도로 다시금 주목받고 있음.
•
분류(Classification), NER 등 비생성 모델이 필요한 영역에서도 인코더 모델은 여전히 강력함. 예를 들어 유해 발화(toxic prompts) 탐지, 에이전트 프레임워크에서의 질의 라우팅 등이 그 예시가 된다.
•
실무 환경에서 여전히 구형 BERT를 사용하는 경우가 많다. 512 토큰으로 제한된 입력 길이, 비효율적인 아키텍처 설계, 제한된 어휘(vocabulary size), 좁은 도메인의 데이터(코드 데이터 부족 등) 등 여러 한계가 있다.
•
최근 몇몇 인코더 개선 모델(MosaicBERT, CrammingBERT, AcademicBERT, NomicBERT, GTE-en-MLM 등)이 발표되었지만, 부분적으로만 문제를 해결하거나 특정 영역만 집중, 혹은 여전히 구형 데이터셋을 활용한다는 점 등 아쉬움이 존재한다.
Previous Works
E5, GTE, BGE, InstructOR, Jina
•
multi-stage regimes 가 최근의 대세가 되고 있음
◦
weakly paired data 470M. 쿼라(Quora), Reddit 등에서 긍정/부정 쌍 만들기
◦
small-sized constrative learning 235M. MSMarco 등 인위적으로 라벨링된 고품질 데이터로 후처리
NomicBERT
•
•
Training Stages
1.
MLM Pretraining
a.
BooksCorpus, Wikipedia (800M words, 2.5B words respectively),
b.
bert-base-uncased tokenizer, 2048 chunking ⇒ nomic-bert-2048
c.
masking ratio to 30% from 15%, removing NSP loss
d.
AdamW optimizer, lr = 5e-4, β1=0.9, β2=0.98, weight decay=1e-5
e.
bs = 4096, ga = 8
2.
Unsup constrastive pretraining: 29개 데이터셋에서 총 470M pair. 이후 consistency filtering (gte-base 모델을 사용해서 q, d pair 에서 q가 상위 2개 내에 존재하지 않으면 버린다 → 235M 쌍으로 남음). 이후 대부분의 쌍이 2048 토큰 보다 짧은 문서를 포함하고 있으므로 long-context range dependencies를 길러주기 위해서 Full wikipedia + S2ORC 논문 전문을 포함하였음.
a.
infonce loss
b.
bs = 16384
c.
optimizer: AdamW, LR=2e-5, β1=0.9, β2=0.999, weight decay=0.01, gradient clipping=1.0
d.
lr: 700 step warming up, inverse square root deduction.
e.
2048 seq length, 1 epoch for total data.
f.
grad cache & mixed precision.
g.
task specific prefix.
3.
Supervised Contrastive FT: MSMarco, NQ, NLI, HotpotQA, Fever, MEDI 일부
a.
Hard Negatives
i.
MSMarco, NQ, HotpotQA, FEVER와 같은 검색 태스크는 “gte-base” 모델을 이용해 (q, d) 주변에 있는 유사 문서를 가져와 “hard negatives”로 삼음
1.
다른 태스크(NLI 등)는 랜덤 네거티브 사용
b.
Batch Size=256, 한 쌍에 7개의 hard negatives 추가
i.
한번에 너무 많은 negatives(7개 초과)를 늘려도 성능 향상은 크지 않음
ii.
1 epoch만 학습, 여러 epoch 돌리면 성능이 떨어짐
c.
Learning Rate=2e-5, β1=0.9, β2=0.999, weight decay=0.01, gradient clipping=1.0
i.
400스텝 워밍업 후 선형적으로 0까지 감소(linear cooldown)
d.
Prefix 사용
i.
Unsupervised Contrastive와 동일한 prefix 전략을 유지

GTE-en-MLM
•
base (12 layers), large (24 layers), RoPE, SwiGLU, attention dropout = 0, vocab size is multiply of 64, unpadding
•
데이터: C4-en
•
training stage
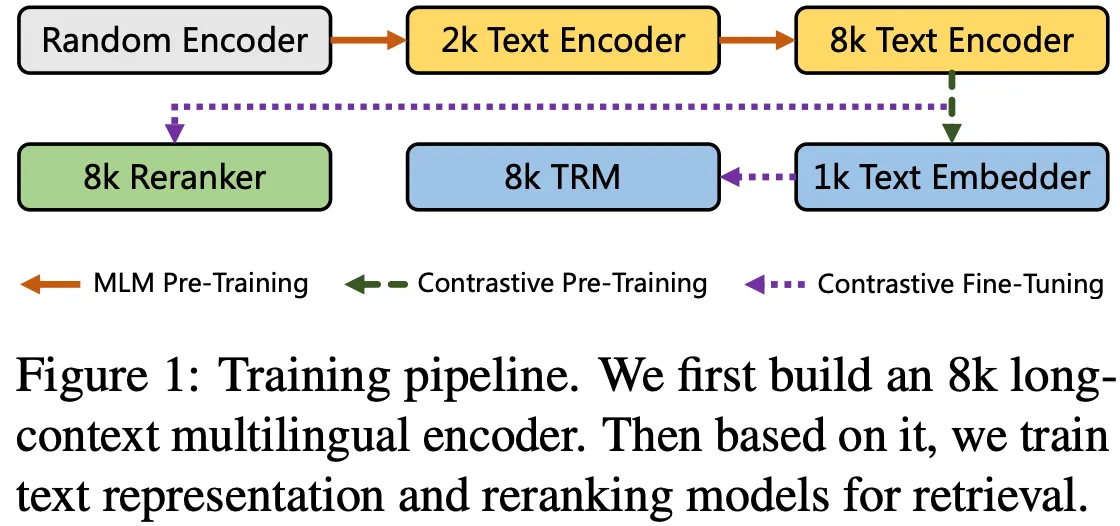
◦
MLM-512
▪
lr = 2e-4, masking ratio 30%, bs = 4096, 300K steps
◦
MLM-2048
▪
lr = 5e-5, masking ratio 30%, bs = 4096, rope base = 10K, 30,000 steps
◦
MLM-8192
▪
lr = 5e-5, masking ratio 30%, bs = 1026, rope base = 160K, 30,000 steps


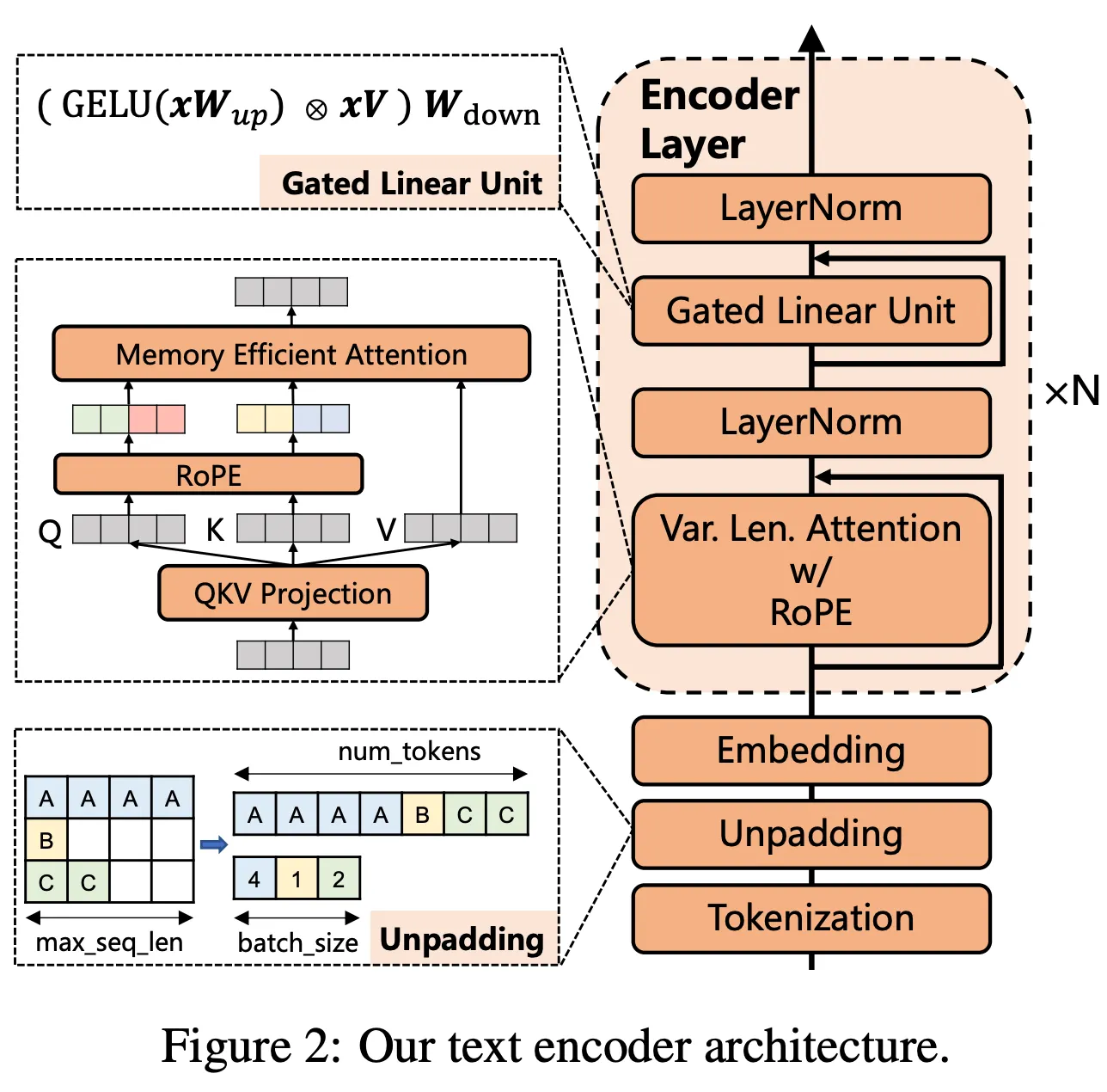
MosaicBERT (Databricks)
•
FlashAttention, ALiBi, GLU (adding a gate), Unpadding, bfloat16 LN
•
MLM 30%, bfloat16, vocab multiplier 64, C4 ⇒ Pareto Optimality !
•
전통적 BERT-Base가 같은 GLUE 점수(83.2)에 도달하는 데 약 11.5시간이 걸렸으나, MosaicBERT-Base는 4.6시간 만에 달성(약 2.38배 빠름).
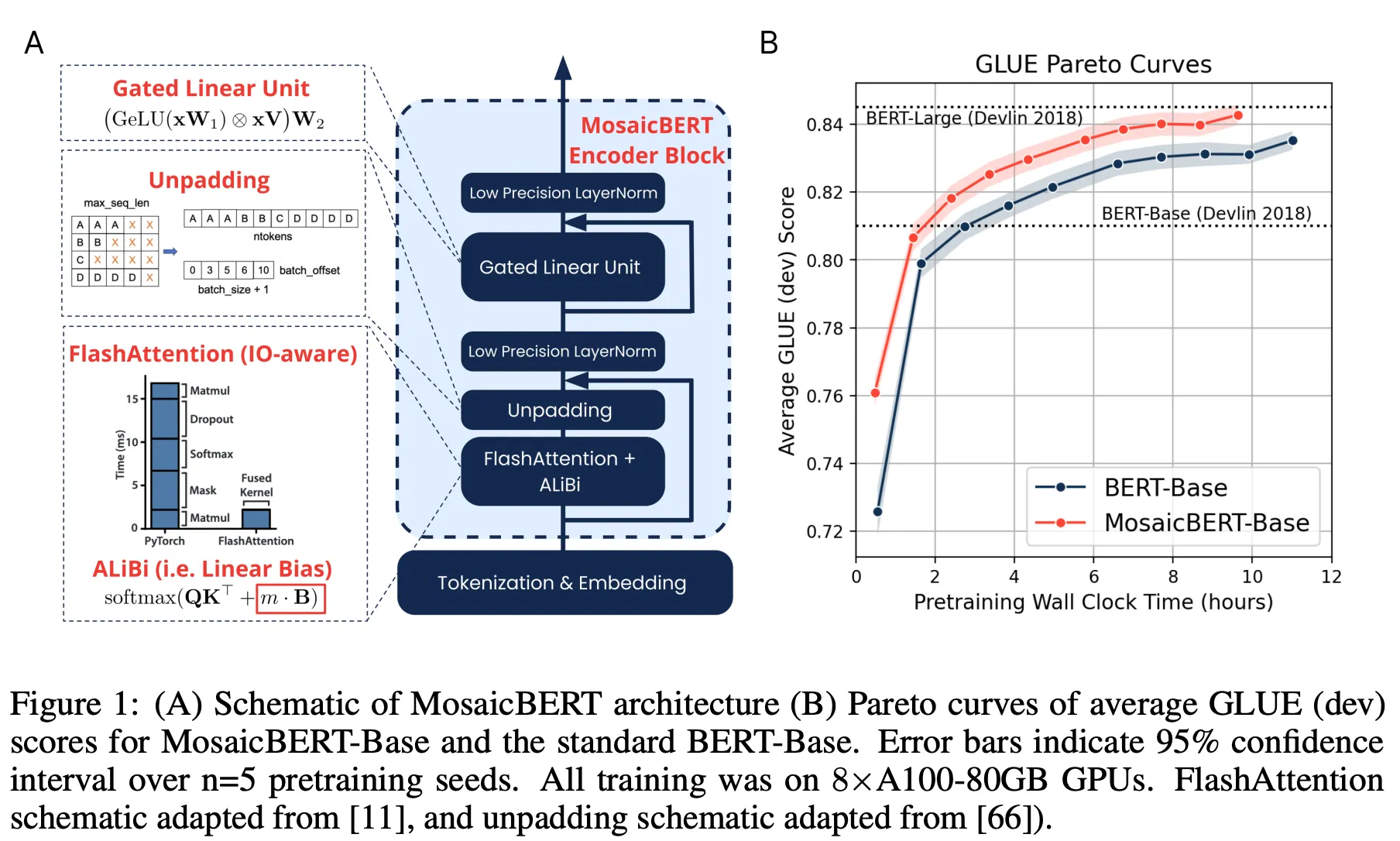

•
그렇다면 MosaicBERT와 어떤 차이가 있나?
◦
RoPE & Local Attention
◦
Unpadding을 “전면적으로” 적용했다.
◦
GeGLU over SwiGLU
◦
MosaicBERT는 Low Precision LayerNorm(bfloat16)을 쓰고 Attention dropout을 없앴으나, ModernBERT는 여기서 더 나아가 Linear bias 제거, RMSNorm vs LayerNorm 실험 등 다수 시도. 최종적으로 LayerNorm (Bias=False) 선택.
◦
MosaicBERT는 AdamW(bfloat16) 등 표준 방식을 썼으나, ModernBERT는 StableAdamW, Trapezoidal LR 등 여러 최신 기법(Adafactor-style clipping, 1 - sqrt decay 등)을 도입해 더 긴 학습에서 안정성을 확보.
◦
MosaicBERT가 “vocab 64배수” 정도 최적화였다면, ModernBERT는 모델 차원 수(히든 사이즈, FFN 확장 등)를 GPU 텐서코어/SM 개수에 잘 매핑하도록 설계해 GPU 효율(throughput) 극대화하기 위해서 MosaicBERT의 개량했다.
Models
Modern Transformer
•
Bias Terms
◦
대부분의 Linear 레이어와 LayerNorm에서 bias(편향) 파라미터를 없애 버림 → 대부분 레이어의 Bias를 빼도 성능이 거의 떨어지지 않는다고 보고
◦
파라미터 예산(=모델 크기)을 더 “유용한” 부분(Linear weight)으로 몰아주어 효율을 높이고자 함 → Linear 레이어와 LayerNorm마다 존재하는 작은 Bias 항도, 전체 레이어 수가 많아지면 누적되어 상당한 파라미터가 될 수 있다.
◦
예컨데, BERT에서 모든 Linear와 Norm에 편향이 있었다면, 여기서는 최종 decoder Linear 하나만 예외적으로 bias를 두고, 나머지는 전부 bias를 제거.
•
Positional Embeddings
◦
RoPE(Rotary Positional Embeddings) 사용!
•
Normalization
◦
Pre-normalization: Attention, MLP 전에 LayerNorm을 적용해 학습 안정성을 높이는 구조 → llama family 에서 사용되는 전략.
◦
임베딩 레이어 뒤에 LayerNorm을 한 번 더 넣고, 첫 Attention 블록의 Norm을 제거(중복 방지).
◦
전반적으로 Post-Norm(전통 BERT)보다 Pre-Norm이 deep transformer 에서 안정적인 경향.
•
Activation
◦
GeGLU(Gated Linear Units) 기반 활성함수. (BERT 원본에선 GELU)
◦
GLU 변형(GeGLU)은 MLP 과정에서 게이트를 통해 “어떤 정보를 통과/차단할지”를 학습 → 표현력 개선 효과.
Efficiency Improvements
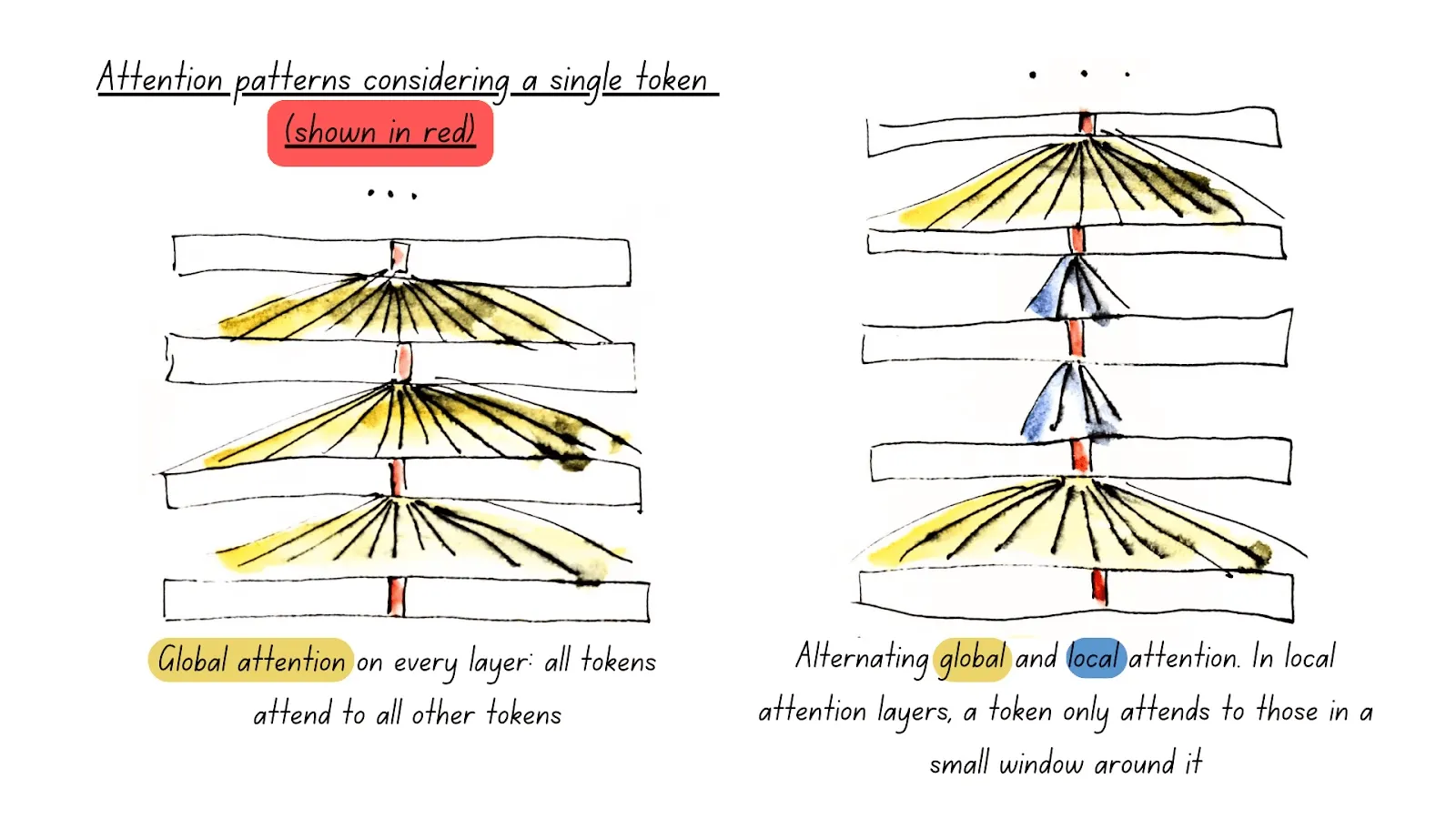
•
Alternating Attention
◦
Transformer의 “풀 어텐션(Global Attention)”은 모든 토큰이 다른 모든 토큰과 상호작용하므로, 시퀀스 길이가 길어질 때(=Long Context) 계산량이 O(n^2) 이 되는 문제가 있음.
◦
따라서 ModernBERT 에서는 3번째 레이어마다 full (global) attention 을 수행하고 나머지 레이어는 local attention 으로 교차 적용한다.
◦
global attention layer는 RoPE의 ceta 가 160K 이고 local attention layer 는 ceta 가 10K 이므로 스케일의 차이를 두는데, 길이별 rotary base 를 달리 해서 긴 범위 문맥과 짧은 범위 문맥 사이 각각을 최적화하도록 한다. 따라서 long sequence processing 할 때 전체 레이어를 full attention 으로 하면 비효율적이므로 특정 레이어만 global 로 문맥을 attend 하고 나머지는 local 만 보게 해서 계산량을 대폭 줄이며 문맥 성능을 일정하게 attain 한다.
•
Unpadding & Sequence Packing
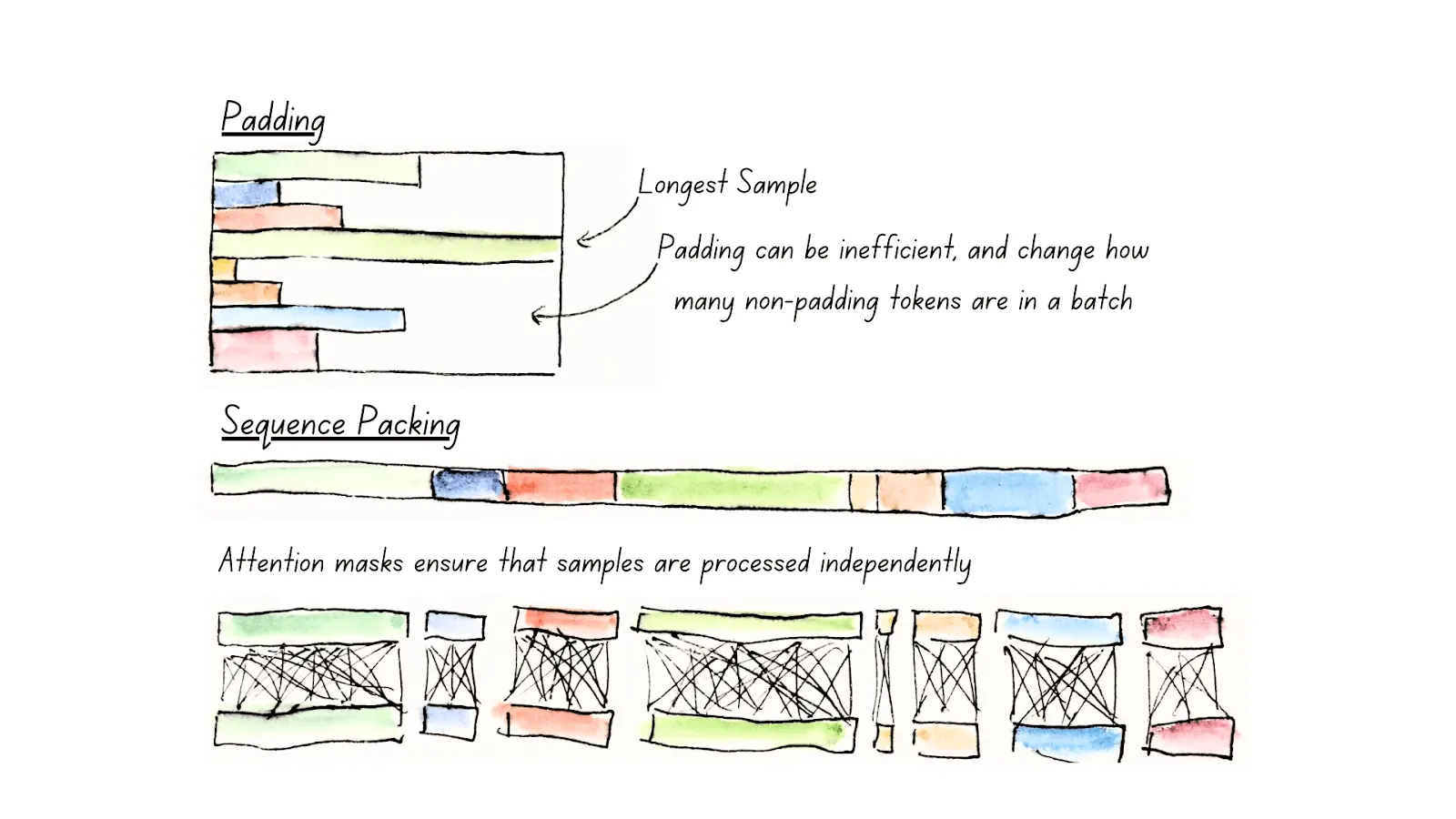
◦
“실제 유효 토큰만” 뽑아 (nnz, dim) 형태로 펼쳐서 연산, 패딩 토큰(마스크=0) 부분은 계산에서 제외.
◦
ModernBERT:
▪
(a) “토큰 임베딩 전(before the token embedding layer)” 단계부터 unpad
▪
(b) 필요시 마지막 출력에서만 repad → 레이어마다 unpad→repad 반복이 아니라 처음부터 끝까지 unpadded 상태로 처리 → 메모리 대역폭·연산 낭비가 훨씬 줄어듦. 결과적으로 10–20% 성능 개선.
▪
FlashAttention는 “가변 길이 시퀀스(cu_seqlens, 등) 지원”을 제공 → unpadded 텐서로도 쉽게 Attention 계산 가능.
▪
RoPE도 “자유롭게” 적용 가능(“jagged attention masks” 가능).
◦
하지만, ModernBERT 시점에서 FA3(Shah et al., 2024)는 H100 GPU 최적화이지만, 슬라이딩 윈도우 어텐션(local) 을 지원하지 않음. 따라서 “글로벌 어텐션 레이어 → FA3”, “로컬(슬라이딩 윈도우) 레이어 → FA2” 식으로 혼합 사용.
◦
GTE 계열은 xformers를 사용하므로 under the hood 에서 pad 토큰이 들어간 부분을 연산에서 제외하거나 block-sparse 로 취급할 텐데, 아래 evaluation 에서 GTE 보다 memory efficient 하다는 것을 보여줌.
▪
아마 모델별 세부 요구사항(예: local attn, custom LN, embedding-before vs after unpad, 등)까지 최적화는 한계. 즉, “모델 전처리/후처리”를 어떻게 통합하느냐에 따라 효율이 달라질 수 있지 않을까?
▪
특히, ModernBERT는 encoder-only 구조 + local attention(또는 sliding window) + 8192 context에 최적화되었고, embedding 단계 전부터 unpad를 수행하므로 embedding + MLP 전체에 걸쳐 pad 토큰을 보지도 않고 연산량을 줄이므로 절약될 수도 있겠다.
•
torch.compile
◦
PyTorch 2.x의 컴파일 기능(Ansel et al., 2024)은 JIT(Just-in-time) 컴파일을 통해 GPU 코드를 최적화.
◦
ModernBERT는 호환되는 모듈들을 torch.compile로 감싸 10% 정도 추가 성능 상승 달성. 컴파일 오버헤드는 무시할 수준.
Model Design
1.
동일 파라미터 수, 다른 구조
•
모델의 총 파라미터 수가 같아도 학습 특성이나 성능, 추론 지연 시간 측면에서 차이가 있음.
◦
“Deep & Narrow”: 레이어 수를 늘리고, 각 레이어의 hidden 크기를 줄이는 형태
◦
“Shallow & Wide”: 레이어 수가 적고, 각 레이어 크기를 크게 잡는 형태
2.
Deep & Narrow 장점/단점
•
여러 연구(Tay et al. 2022, Liu et al. 2024 등)에 따르면, Deep & Narrow 모델이 다운스트림 성능(fine-tuning 결과 등)이 더 뛰어난 경향이 있다.
•
단, 레이어가 많아지면 순차적 처리(시퀀셜)가 늘어나서 추론(inference) 속도가 느려질 수 있음.
3.
하드웨어-aware 설계 필요성
•
(Anthony et al. 2024)에서, 하드웨어에 맞게 모델 크기/형상을 최적화하면, 런타임(추론 시간 등)이 크게 단축된다고 지적.
•
실제로 기존에도, “배수를 맞추면 GPU 텐서 코어가 효율적으로 동작한다”는 것이 많은 엔지니어들에게 경험칙으로 알려져 왔음(Shoeybi et al. 2019, Karpathy 2023, Black et al. 2022).
4.
ModernBERT는 22레이어와 28레이어를 선택했다.
•
목표
◦
Deep & Narrow가 주는 좋은 다운스트림 성능을 활용
◦
GPU 효율(tensor core tiling 등)도 극대화
◦
추론 속도도 지나치게 느려지지 않도록 레이어 수를 적당히 조절
•
레이어 개수의 결정
◦
ModernBERT-base: 22레이어, 약 149M 파라미터
◦
ModernBERT-large: 28레이어, 약 395M 파라미터
◦
Deep & Narrow 기조를 지키면서도, 실제 하드웨어상 크게 느려지지 않는 지점을 찾았다고 설명.
5.
Hidden size & GLU expansion
•
Base: hidden=768, GLU expansion=2,304
•
Large: hidden=1,024, GLU expansion=5,248
•
“레이어 내부 매트릭스가 64 배수”나 전력 효율을 높일 수 있는 배수를 맞추어, 다양한 GPU에서 tensor core를 최적으로 활용하게끔 한다.
◦
Nvidia의 텐서 코어 연산은 “행렬 크기가 64의 배수”일 때 가장 효율적으로 동작함. (행, 열)이 64로 나누어떨어지면 발휘되는 특화된 빠른 연산.
◦
(Tile Quantization) Weight matrix가 128×256 블록 단위로 잘 나뉘어야, 즉 정렬/정규화되어 있어야 연산이 최적화된다. 행·열 크기가 128, 256 등 특정 타일(block)로 나누어질수록 GPU에서 한 번에 병렬화가 잘 됨.
◦
(Wave Quantization) 블록 수가 GPU 스트리밍 멀티프로세서(SM) 수로 나누어떨어져야만 SM마다 동일/균등하게 workload를 분배할 수 있어, 병목을 줄일 수 있다고 함. 하지만, 서로 다른 GPU(예: T4는 SM 40개, A100은 SM 108개, RTX 3090은 SM 82개 등)마다 SM 개수가 다른 것은 감안.
◦
ModernBERT는 T4, A10, L4, RTX 3090, RTX 4090, A100, H100 등 다양한 GPU에서 테스트. SM 개수도 제각각이니, 완벽히 일치할 순 없지만, 여러 인퍼런스용 GPU에 걸쳐 대체로 높은 SM utilization을 목표로.
→ 결국 model hidden size / intermediate size 등을 고를 때, “64배수” 또는 “전원(전력)·성능” 면에서 좋은 배수·인덱스 등을 찾아 타협점을 만든 셈.
Training
Data
•
Mixture
◦
2조(2 trillion) 토큰 규모의 다국면(주로 영어) 데이터로 학습.
◦
소스: 웹 문서, 코드, 과학 논문 등, 최근 BERT류가 일반적으로 사용하는 복합 데이터 믹스.
◦
최종 믹스 비율은 여러 ablations 결과를 보고 결정.
•
Tokenizer
◦
최근의 인코더들(예: Nussbaum et al. 2024)은 대부분 과거 BERT 토크나이저를 재사용하지만…
◦
ModernBERT는 modern BPE, OLMo 토크나이저(Groeneveld et al., 2024) 기반 사용 → 코드 토큰 효율 및 성능 향상.
◦
단, special tokens([CLS], [SEP])과 템플릿은 기존 BERT와 동일 → 호환성 유지.
◦
Dictionary 크기=50,368: 64 배수 맞춤, 약 83개 사용 안 되는 토큰(unused) 남겨둠 → 향후 확장성 (ex. 태스크별 special token 등).
•
Sequence Packing
◦
Unpadding을 사용할 경우, (batch 내 문장 길이가 제각각이라) 미니배치 크기가 들쭉날쭉할 수 있음.
◦
이를 방지하려고, sequence packing 기법 사용 → 작은 시퀀스들을 최대 길이 블록 안에 ‘꽉꽉’ 채우는 방식 (Raffel et al., 2020 등).
◦
Greedy packing으로 99% 이상 packing 효율 달성 → batch 사이즈 균일.
Training Settings
1.
Masked Language Modeling (MLM)
•
Objective
◦
MosaicBERT(Portes et al., 2023)처럼, Next-Sentence Prediction 없이 MLM만 사용.
◦
NSP(Next-Sentence Prediction)는 최근 연구에서 추가 이득이 미미하거나 없는 것으로 알려짐(Liu et al., 2019a; Izsak et al., 2021).
•
Masking Rate
◦
30%로 설정 (기존 BERT: 15%).
◦
Wettig et al. (2023)에서 15%보다 높은 masking이 더 효과적이라고 보고.
2.
Optimizer: StableAdamW
•
StableAdamW = AdamW + Adafactor-style update clipping
◦
Adafactor(Shazeer and Stern, 2018) 방식으로 **“per-parameter learning rate adjustment”**를 수행해,
◦
더 안정적인 학습과 일관된 다운스트림 성능을 제공.
•
기존 gradient clipping 대신, learning rate clipping을 사용.
◦
학습 안정성 개선, “standard gradient clipping”보다 여러 다운스트림 결과가 좋았다고 함.
▪
gradient clipping 은 모든 파라미터에 대해 동일한 비율로 gradient를 축소하므로, “매우 큰 gradient가 특정 subset 파라미터에만 집중”되는 경우엔, 그 부분만 클리핑되고 나머지 부분도 동시에 줄여버린다.
▪
lr clipping 은 adamw + adafactor updating clipping = stableadamw. 각 파라미터별로 update가 특정 범위를 넘지 않도록, lr 을 동적으로 조정 한다.
3.
Learning Rate Schedule: Warmup-Stable-Decay (Trapezoidal)
•
Trapezoidal(“WSD”) 스케줄
◦
전통적 Cosine 등 대신, (Xing et al., 2018; Zhai et al., 2022; Hu et al., 2024)에서 제안된 Warmup-Stable-Decay
1.
Warmup: 초기에 LR을 천천히 키움
2.
Stable: 대부분의 학습 단계에서 LR을 일정하게 유지
3.
Decay: 마지막에 짧게 LR을 감소.
◦
이 방식은 “언제든 체크포인트를 이어서 학습(continual training)할 때도 문제를 일으키지 않는다”는 장점이 있으며, 성능도 Cosine과 대등하다고 알려짐(Hägele et al., 2024).
•
ModernBERT-base
◦
학습 토큰 = 1.7조 tokens.
◦
LR = 8e-4를 대부분 유지.
◦
초기에 3억(=3×10^8) tokens warmup (LR 천천히 상승) → 그 뒤에는 LR=8e-4 고정 → 마지막 짧은 구간에서 decay.
•
ModernBERT-large
◦
총 학습 토큰 = 900억 + 800억 = 1,700억 tokens (중간에 LR 변경).
◦
초반 2억(=2×10^8) tokens warmup 후 LR=5e-4로 학습 → 학습이 plateau 하자, LR=5e-5로 다시 시작해 800억 토큰 추가 훈련.
4.
Batch Size Schedule
•
Batch size warmup
◦
처음엔 작은 batch로 시작 → 점진적으로 batch 크기를 늘리는 기법.
◦
직관적으로, 초기에는 모델이 “아직 충분히 좋은 파라미터 상태가 아니므로, 굳이 큰 batch로 업데이트를 합치는 건 비효율”이라는 아이디어.
◦
일정한 “update step 횟수”를 보장하며 batch를 늘리면, 학습 속도/효율이 좋아진다는 관찰 결과.
•
ModernBERT-base
◦
batch size를 768 → 4,608까지 50억(=5×10^9) tokens에 걸쳐 점진적 증가.
•
ModernBERT-large
◦
448 → 4,928까지 10억(=1×10^9) tokens에 걸쳐 증가.
5.
Context Length Extension
•
Base training: 1.7조 tokens, seq_len=1024, RoPE theta=10,000
•
추가 학습(3000억 tokens)
◦
seq_len=8192 확장 (특히, 글로벌 attention 레이어의 RoPE theta=160,000로 증가)
◦
LR=3e-4로 2500억 tokens, 이후 상위 품질 데이터샘플로 500억 tokens를 1−sqrt decay로 학습.
◦
이 과정을 통해, 8k 길이 문맥에서도 잘 동작(특히 IR/rerank-like retrieval)에 성능 손실 없이 확장.
6.
Weight Initialization
•
ModernBERT-base: Megatron Initalization
◦
fan_in, fan_out 은 레이어 가중치의 행과 열의 크기를 나타내고 파라미터 스케일링에 사용한다. 전형적인 초기화로 매우 작은 범위에서 무작위로 가중치를 시작한다. 138M parameter 이므로 랜덤으로 시작해도 안정적이었다.
•
ModernBERT-large: Phi “Center Tilling” + Gopher Scaling
◦
Phi Model 계열에서 기존 작은 모델에서 큰 모델로 확장할 때, 작은 모델의 파라미터 일부를 가져와서 큰 모델 파라미터의 center 에 tilling 한다. 나머지 왼 오른쪽 부분도 wrap-around 해서 큰 모델의 가중치 구조를 “자연스럽게” 형성한다.
◦
ModernBERT-base weight 행렬 768 * 768 을 가운데에 배치하고 그 보다 더 큰 부분, 예를 들어 1024 - 768 = 256 부분은 wraparound 부분으로 base 가중치의 일부를 복사해서 메꾼다.
◦
또한 레이어 수가 늘어난 경우 (22 → 28) 에는 중간 레이어의 파라미터를 특정 간격으로 interpolation 해서 확장한다.
7.
Appendix
•
Weight Decay
◦
LayerNorm·bias엔 적용 X
◦
AdamW-style decoupled weight decay만 (fully decoupled).
•
Final Checkpoints
◦
일정 구간에서 체크포인트들을 평균(checkpoint averaging)하면 성능이 좋아지는 경우가 있음(Dubey et al., 2024; Clavié, 2024).
◦
ModernBERT-base: 최종 단계 중 “best performing annealing checkpoint 3개 + 최종 1개” 평균.
◦
ModernBERT-large: 평균해봤지만 별 효과 없어서 “단일 best checkpoint” 사용.
•
Live Evaluation
◦
MNLI나 내부 valid loss/토큰 정확도 등으로 모니터링.
Evaluation
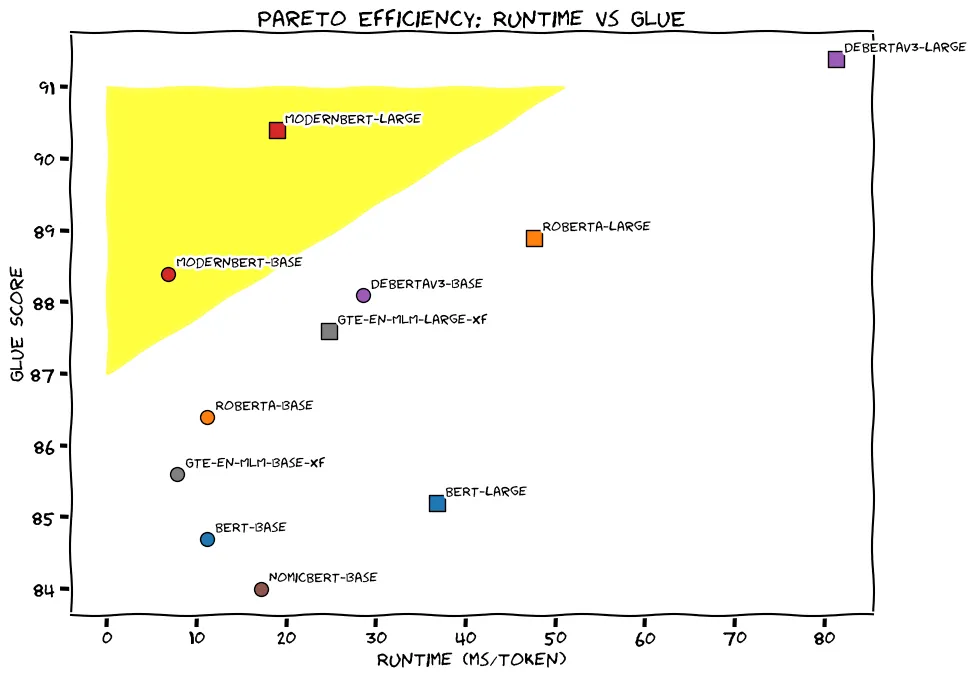
•
GLUE 를 전면에 내세웠지만 이미 exploited 된 벤치마크라 적합한 hooking 은 아닌듯 하다.
◦
ModernBERT-base가 기존 base encoders(DeBERTa-v3-base 포함)보다 높은 결과 → 최초로 “MLM 방식”이 RTD(Replaced-Token-Detection; ELECTRA 나 DeBERTAv3 처럼 입력 문장 안의 각 토큰이 원래 올바른지, 가짜 대체된 토큰인지 분류 판별) 기반보다 NLU 점수 뛰어넘음.
◦
ModernBERT-large도 DeBERTaV3-large(435M) 수준(거의 비슷)이며, 파라미터는 약 395M으로 더 적고, 추론 속도도 2배 이상 빠름(섹션 4에서 언급).
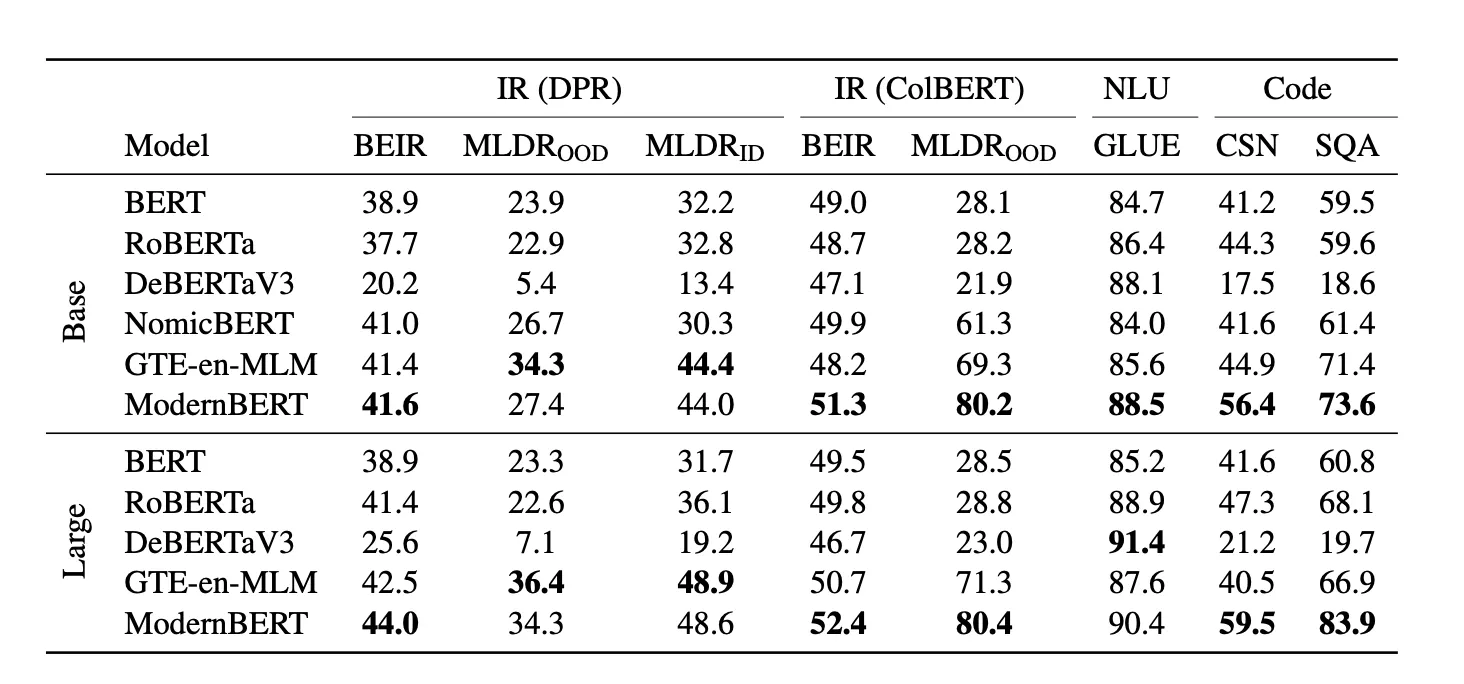
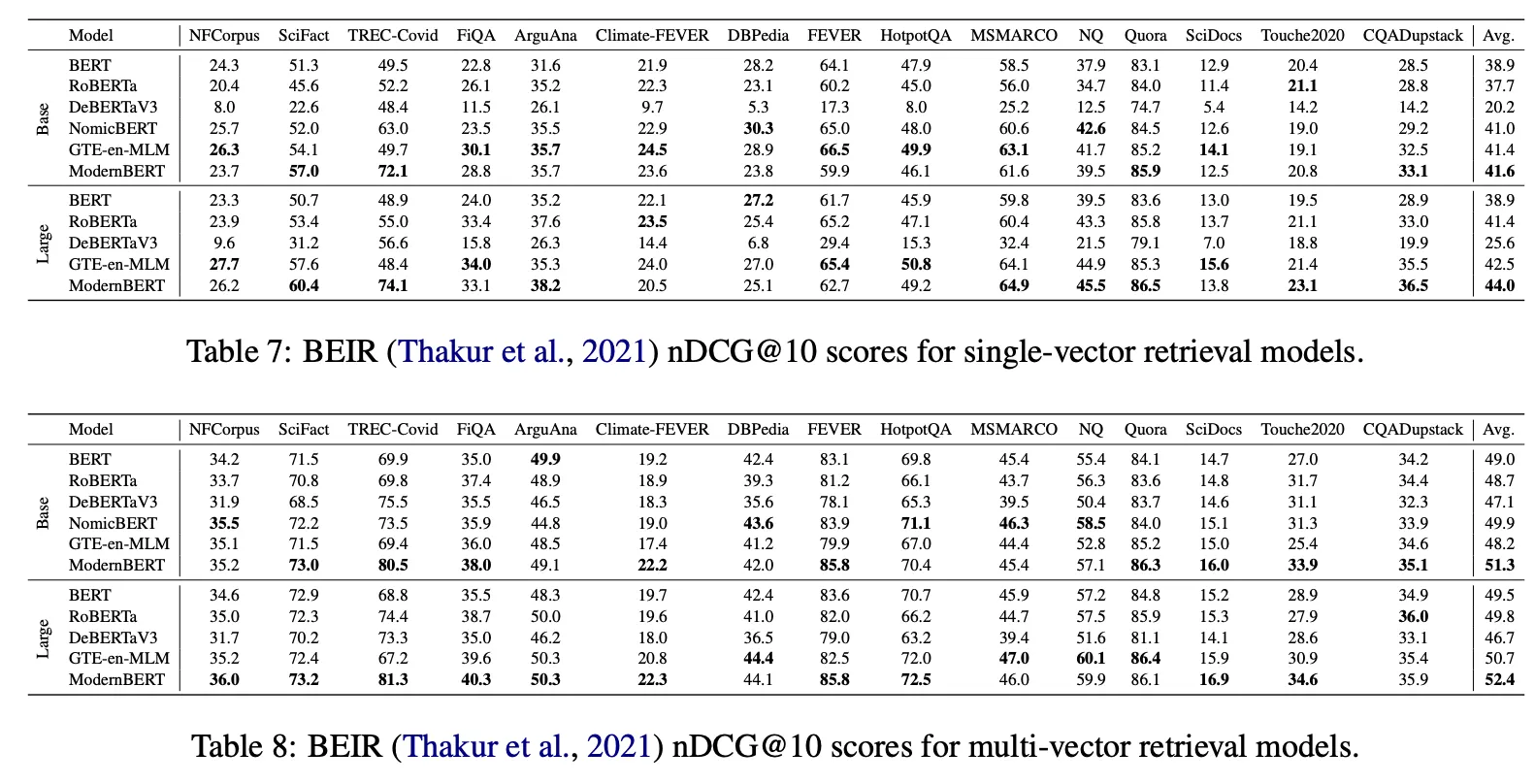
Information Retrieval (BEIR)
1.
배경
•
IR은 encoder-only 모델의 가장 대표적 활용처 중 하나.
•
DPR(Karpukhin et al., 2020) 등의 single-vector 방식, ColBERT(멀티벡터) 등이 자주 쓰임.
•
LLM 시대에도, “Retrieval-Augmented Generation(RAG)” 파이프라인에서 search 모델은 대부분 encoder (또는 small dual encoder) 기반.
2.
평가 suite: BEIR(Thakur et al., 2021)
•
다양한 도메인/과제(질의-문서 매칭 등)를 포함한 retrieval 벤치마크.
•
nDCG@10 성능을 측정.
•
각 설정(단일벡터 vs. 멀티벡터)마다 LR 스윕 → best model로 BEIR 테스트. (Appendix E.2 참조)
3.
Single Vector (DPR)
•
DPR(Dense Passage Retrieval): 문서를 하나의 벡터로만 표현. 모델은 query & document를 같은 차원 벡터로 임베딩 → 코사인 유사도 등으로 랭킹.
•
학습 세팅:
◦
MS MARCO(Bajaj et al., 2016) + 하드 네거티브(Xuan et al., 2020),
◦
약 1.25M 쌍, batch size=16, warmup=5% of training.
◦
sentencetransformers(Reimers and Gurevych, 2019) 활용.
4.
Multi Vector (ColBERT)
•
ColBERT(Khattab and Zaharia, 2020): 문서 내 각 토큰 벡터를 유지. Query와 Document 사이의 유사도는 MaxSim(쿼리 토큰별로 최대 코사인 등)으로 계산.
•
훈련 세팅:
◦
JaColBERTv2.5(Clavié, 2024) 레시피, batch=16, 5% LR warmup.
◦
MS MARCO 81만 샘플, KL-divergence distillation(teacher BGE-M3(Chen et al., 2024)) → student로 학습.
◦
ColBERT 학습용 PyLate 라이브러리(Chaffin and Sourty, 2024).
5.
결과
•
DPR/ColBERT 세팅에서 ModernBERT가 다른 encoders(BERT, RoBERTa, DeBERTa, GTE-en-MLM, NomicBERT 등)보다 성능이 좋다고 주장하지만…
•
TREC-Covid 에서 20 점 오른 것 ⇒ 왜 그러지? GTE backbone 과 무슨 차이이길래? 모델의 차이는 아닌 것 같고 외부 요인이지 않을까.
•
HotpotQA, MSMARCO 에서의 성능 차이가 없거나 떨어진다.
Long-Context Text Retrieval (3.1.3)
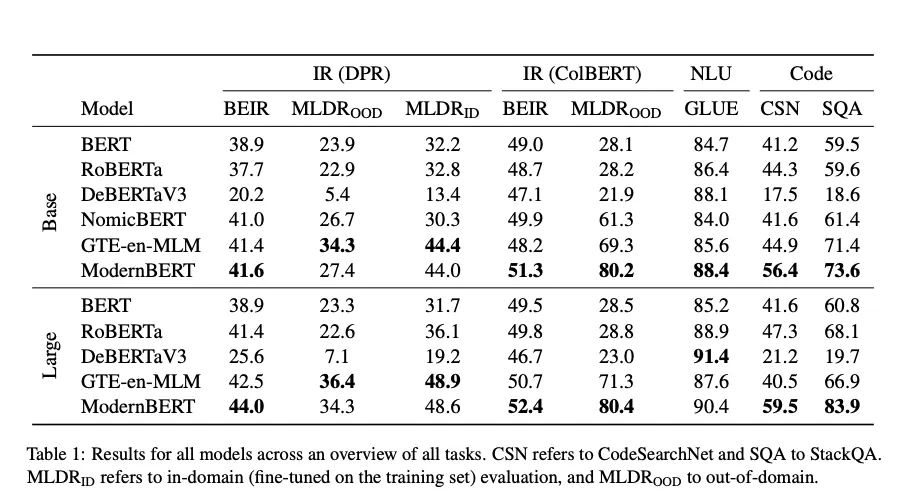
1.
배경 및 평가 벤치마크: MLDR
•
대부분의 encoder-only 평가세트가 짧은 문맥에 초점(BEIR 등),
•
긴 문맥용 평가로는 Needle-in-a-haystack (Kamradt, 2023), RULER (Hsieh et al., 2024) 등이 있지만 생성(generative) 위주.
•
MLDR (Chen et al., 2024): 수십만 개의 long documents가 포함된 영어 대상 retrieval 벤치마크.
◦
문서 길이가 길어(8k 토큰까지 가능) 긴 문맥에 대한 retrieval 성능을 테스트하기 좋음
2.
실험 설정 (3가지)
•
Single Vector – Out-Of-Domain
◦
MS-MARCO(짧은 문맥)로만 학습한 DPR 모델을 별도 롱-컨텍스트 파인튜닝 없이 MLDR에서 평가.
◦
즉, 짧은 문맥에서만 훈련 → 장문 시나리오로 OOD(e.g. domain shift).
•
Single Vector – In-Domain
◦
MS-MARCO로 학습한 DPR 모델을 추가로 MLDR 학습(long-context 데이터)하여 In-Domain에 맞게 파인튜닝.
◦
그 후 MLDR 평가.
•
Multi-Vector – Out-Of-Domain
◦
ColBERT(멀티벡터) 특성상 “토큰별” 임베딩이라, 문서가 길어져도 single-vector 모델보다 일반화가 쉽다고 알려짐(Bergum, 2024).
◦
따라서 MLDR용 파인튜닝 없이, 기존 ColBERT 체크포인트(Section 3.1.2에서 만든 모델)로 바로 MLDR 테스트.
•
결과
◦
DPR
▪
Out-of-domain: ModernBERT가 NomicBERT, RoBERTa, DeBERTa, BERT 등보단 높지만, GTE-en-MLM이 (의외로) 더 높음.
▪
In-domain(MLDR 데이터로 추가 파인튜닝) 시 ModernBERT vs. GTE-en-MLM은 유사해짐.
▪
결론: ModernBERT는 8192 native context이지만, 완벽히 장문에 최적화되려면 추가 파인튜닝이 필요할 수도 있겠다. 위 내용만 봐서는 우월하다고 주장하기에는 애매 하다.
◦
ColBERT
▪
토큰 레벨 MaxSim이라 문맥 길이가 길어져도 성능 손실이 적다(Bergum, 2024 https://blog.vespa.ai/announcing-long-context-colbert-in-vespa/).
•
GTE-en-MLM, NomicBERT, ModernBERT 모두 “long-context 특화” 모델들이 short-context encoders보다 40+ 점 높음.
•
ModernBERT가 다른 long-context 모델(NomicBERT, GTE-en-MLM) 대비 최소 +9점 nDCG@10 리드.
•
추측: 긴 pretraining + local attention 시너지 → 토큰 단위 ColBERT와 궁합이 좋을 수도 있지 않을까?
Code
•
데이터: CodeSearchNet, StackOverflow-QA
◦
ModernBERT가 모든 비교 모델보다 뛰어남.
◦
이유: 유일하게 코드 데이터를 프리트레이닝에 넣었고, 토크나이저도 code-friendly. 그래서 큰 의미 X.
Efficiency
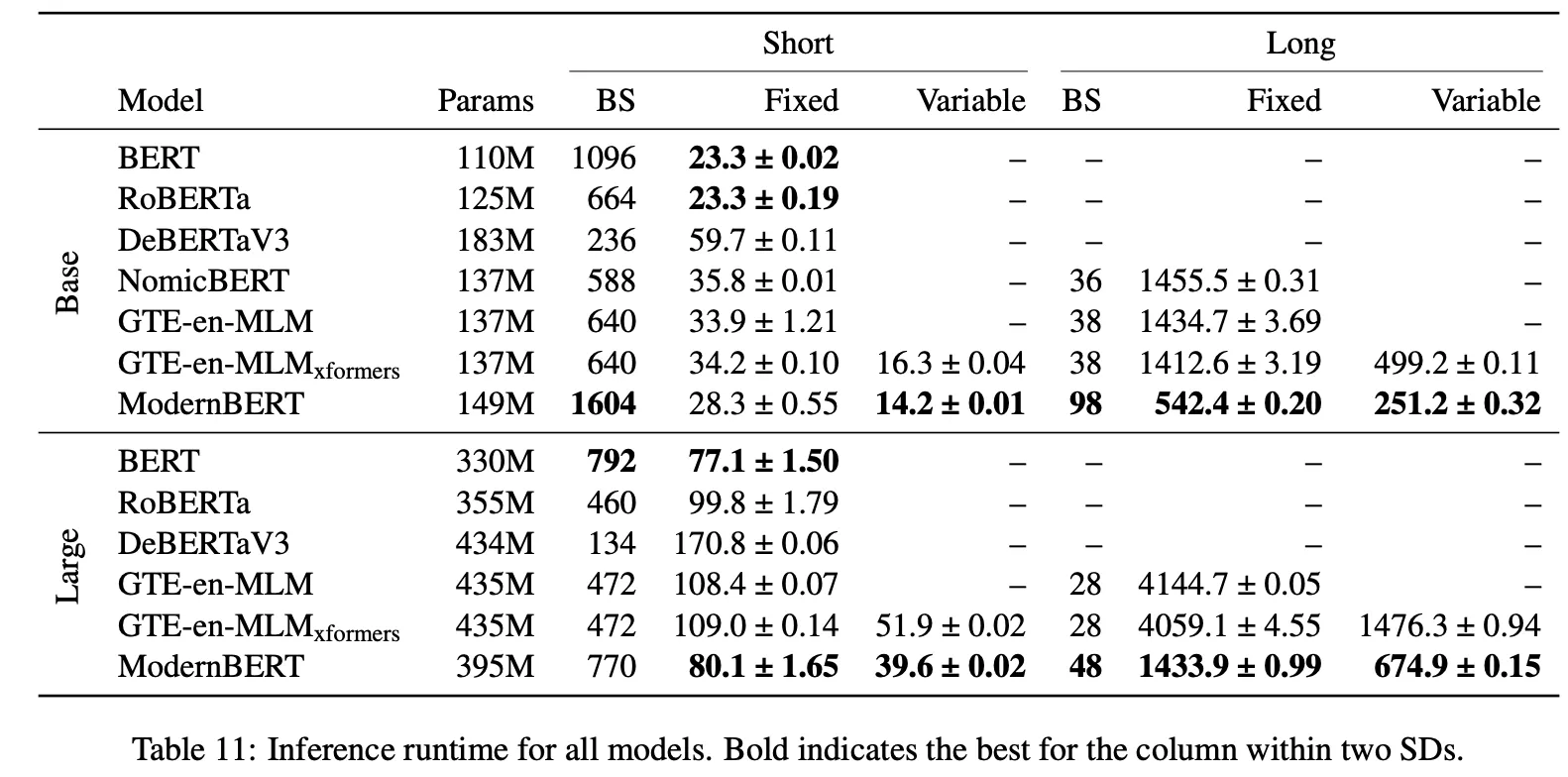
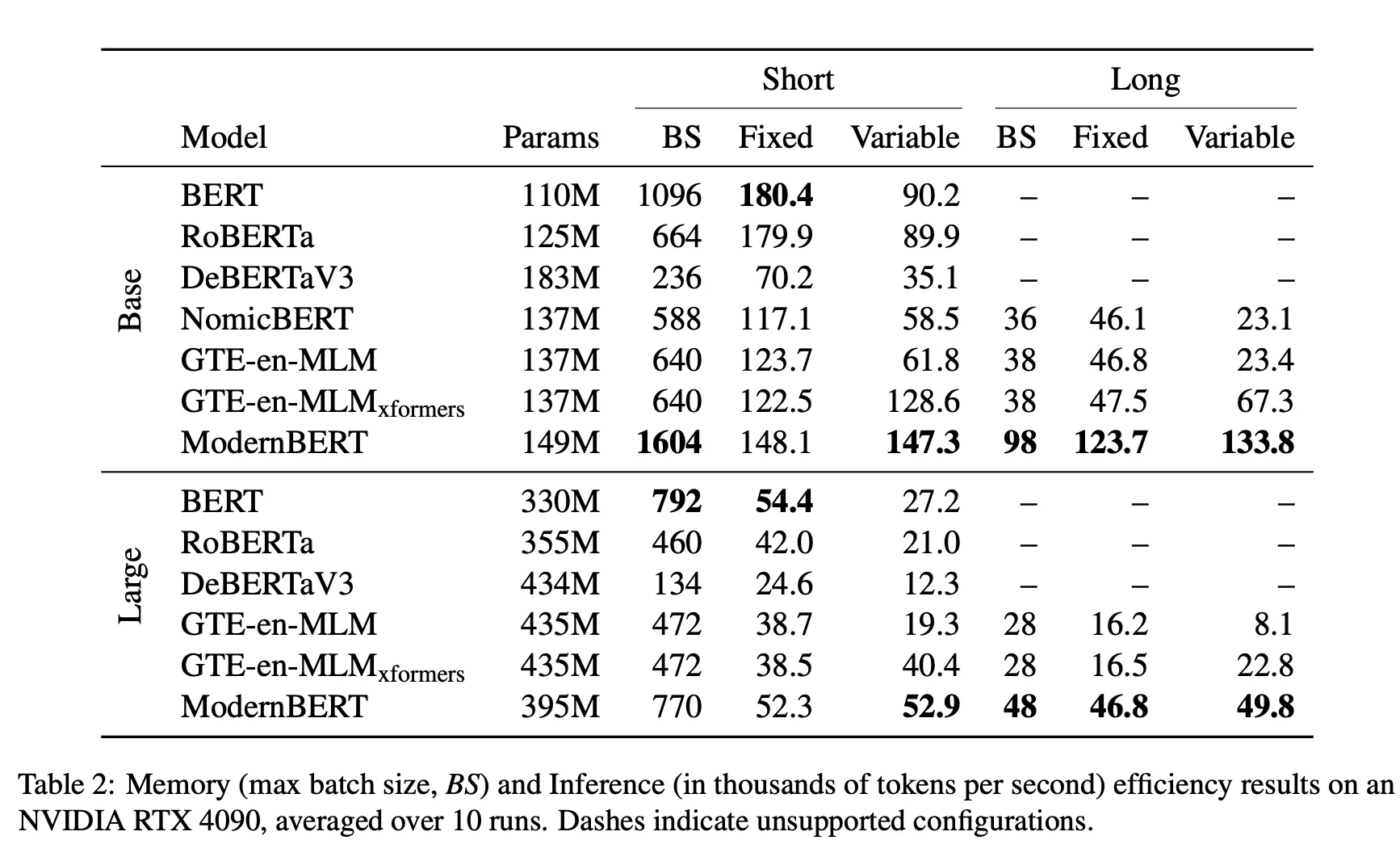
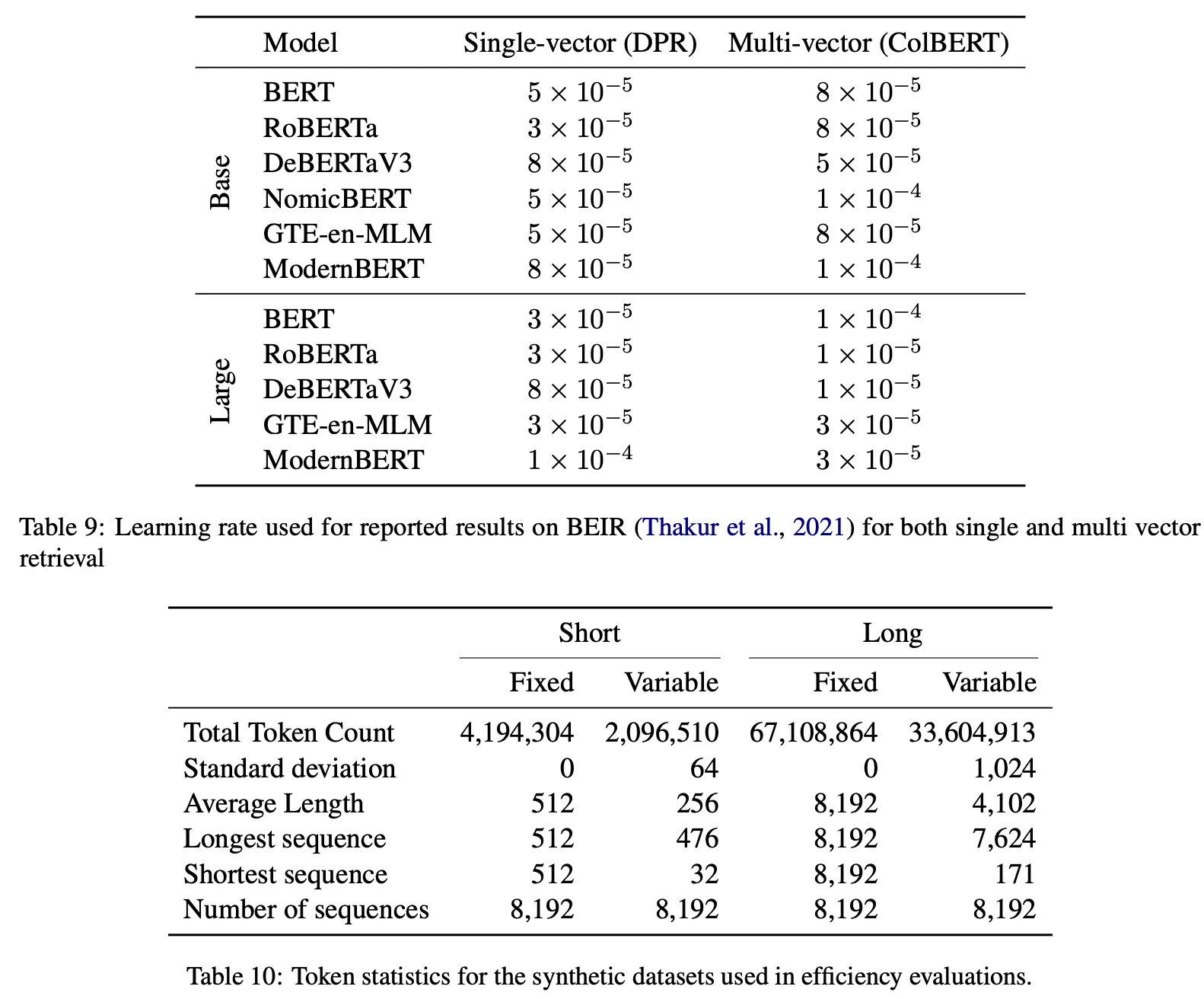
실험 세팅
1.
평가하려는 대상:
•
여러 encoder-only 모델(BERT, RoBERTa, DeBERTaV3, GTE-en-MLM, NomicBERT 등) + ModernBERT.
•
BASE와 LARGE 각각.
2.
입력 문서 4가지 synthetic data:
•
Fixed Short: 모두 512토큰.
•
Fixed Long: 모두 8192토큰(긴 문맥).
•
Variable Short: 평균 256토큰의 정규분포로 길이 다양 (≈ half of 512).
•
Variable Long: 평균 4096토큰의 정규분포 (≈ half of 8192).
이렇게 4개 시나리오에서 토큰 처리 속도(tokens/sec) 와 메모리 사용량(batch size)를 측정.
3.
환경:
•
GPU: NVIDIA RTX 4090
•
모든 모델은 10회 측정 후 평균.
•
GTE-en-MLM은 2가지 모드로 테스트:
◦
(1) out-of-the-box (별도 최적화 없음)
◦
(2) xformers 사용 (unpadding 등 최적화 활성화).
4.
지표:
•
TPS(Tokens Per Second): 초당 처리 토큰 수.
•
Maximum batch size: 같은 GPU에서 한 번에 처리 가능한 최대 배치 크기 (즉, 모델의 메모리 효율).
5.
결과
•
Short Context
◦
속도:
▪
ModernBERT는 원조 BERT, RoBERTa보다는 약간 느림 (이 둘은 파라미터가 훨씬 적기도 함).
▪
그러나 “다른 최신 encoders(DeBERTaV3, GTE-en-MLM, NomicBERT)”보다는 더 빠름.
◦
메모리 사용:
▪
ModernBERT-base는 모든 모델 중 메모리 사용이 가장 효율적 → 배치 크기를 2배 크게 잡을 수 있음.
▪
ModernBERT-large는 BERT-large보다 조금 더 메모리를 쓰지만, 그 외 큰 모델(RoBERTa-large, DeBERTaV3-large, GTE-en-MLM-large)보다 훨씬 적게 씀.
•
Long Context
◦
속도:
▪
ModernBERT는 “다른 롱 컨텍스트 모델” 대비 2.65~3배 빠름(BASE/LARGE 기준).
▪
ModernBERT-large는 46.8k TPS, 반면 GTE-en-MLM-large는 16.5k TPS 정도로 큰 격차. 실제로 ModernBERT-large의 속도가 GTE-en-MLM-base랑 비슷할 정도로 효율적.
◦
메모리 사용:
▪
마찬가지로 ModernBERT가 가장 효율적 배치 크기.
▪
Large 사이즈에서도, 다른 장문 모델들보다 60% 이상 큰 batch를 처리 가능.
▪
Attention 구조에서 나온 결과인 것으로 생각이 된다. ModernBERT는 로컬/슬라이딩 window 기반 attention을 일부 레이어에서 사용 → 시퀀스 길이가 길어도 전역(dense) 연산이 아닌 block-sparse 식이므로 연산량이 더 줄어듦. 이때 unpad + local attn 시나리오가 궁합이 좋아, 매우 긴 문맥(8k)에서 2~3배 이상 다른 모델 대비 빨라졌다는 결과이지 않을까.
•
Variable Length
◦
Unpadding 효과:
▪
GTE-en-MLM과 ModernBERT 둘 다 unpadded attention을 지원 → 문서 길이가 제각각일 때 이득.
▪
그럼에도 ModernBERT가 GTE-en-MLM보다 14.5~30.9% 더 빠름(단문 구간) / 98.8~118.8% 더 빠름(장문 구간).
▪
이유: ModernBERT는 local attention + 효율적인 아키텍처, 반면 GTE-en-MLM은 global dense attention → 길어질수록 overhead가 큼.
논문의 주장
1.
ModernBERT가 장문에서 특히 빠른 이유
•
(1) Local attention: 길이가 매우 커질수록, 전역(dense) attention에 비해 연산이 적게 든다.
•
(2) Unpadding: 실제 유효 토큰만 처리.
•
(3) 하드웨어 최적화 디자인: hidden dimension·배수 설계 등으로 텐서 코어 효율.
2.
짧은 문맥(512 이하)에서도 준수한 성능
•
원조 BERT/RoBERTa는 파라미터가 더 적어서 어느 정도 이점을 갖지만, ModernBERT는 그 외 최신 대형 encoders보다 빠름.
3.
메모리 효율
•
ModernBERT-base: 다른 모든 base 모델 대비 2배 이상 큰 배치 처리가 가능.
•
ModernBERT-large: BERT-base 수준 또는 그보다 더 나은 편. 나머지 모델들(DeBERTaV3, RoBERTa-large, GTE 등)보다 훨씬 여유로움.
4.
DeBERTaV3의 극단적 비효율
•
논문에서 언급하기를, DeBERTaV3는 GLUE 성능은 좋으나 메모리 5~7배 더 사용 & 속도도 2배 느림.
•
“attention 구조”나 “disentangled matrix” 등 복잡한 부분이 원인으로 추정.
간단한 재현 시도 (메모리만 비교)
파이썬 코드
Model | mem_before_load (GB) | mem_after_load (GB) | mem_after_infer (GB) | avg_infer_time (s) |
Alibaba-NLP/gte-en-mlm-large | 0.00 | 1.62 | 1.63 | 0.0208 |
answerdotai/ModernBERT-large | 0.01 | 1.48 | 1.48 | 1.2629 |
•
엄청나게 두드러지는 장점이 보이지는 않는다 ? → A100 이라서 그럴 듯.
코드 읽기
model.py
# https://github.com/AnswerDotAI/ModernBERT/blob/main/src/bert_layers/model.py
def forward(
self,
input_ids: Optional[torch.Tensor],
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
return_dict: Optional[bool] = None,
indices: Optional[torch.Tensor] = None,
cu_seqlens: Optional[torch.Tensor] = None,
max_seqlen: Optional[int] = None,
batch_size: Optional[int] = None,
seq_len: Optional[int] = None,
**kwargs,
) -> Union[Tuple[torch.Tensor], MaskedLMOutput]:
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# (B) unpad_embeddings가 활성화되어 있고, (indices, cu_seqlens, max_seqlen)이 없다면,
# unpad_inputs()를 통해 실제로 유효 토큰만 모아 인코더에 넘긴다.
if self.unpad_embeddings and (indices is None and cu_seqlens is None and max_seqlen is None):
batch_size, seq_len = input_ids.shape[:2]
input_ids, indices, cu_seqlens, max_seqlen, position_ids, labels = self.unpad_inputs(
input_ids, attention_mask, position_ids, labels
)
# (C) FlexBertModel 인코더 호출
# => Embeddings + Transformer Layers(FlashAttention2, GLU 등) + (option) final_norm
output = self.bert(
input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
indices=indices,
cu_seqlens=cu_seqlens,
max_seqlen=max_seqlen,
)
# (D) masked_prediction=True인 경우, labels와 output을 마스킹된 위치만 골라서 연산
if self.masked_prediction and labels is not None:
# flatten labels and output first
labels = labels.view(-1)
output = output.view(labels.shape[0], -1)
# ignore_index=-100이 아닌 위치(실제 마스킹된 위치)만 추출
mask_tokens = labels != self.loss_fn.ignore_index
output = output[mask_tokens]
labels = labels[mask_tokens]
# (E) MLM Head 호출: PredictionHead + Vocab Projection(Decoder)
# => 컴파일 모드인지에 따라 self.compiled_head() vs self.decoder(self.head(...))
if self.compile_model:
logits = self.compiled_head(output)
else:
logits = self.decoder(self.head(output))
# (F) Loss 계산
loss = None
if labels is not None:
# (마스킹된 위치만 사용하지 않는다면) 전체 시퀀스 형태로 reshape
if not self.masked_prediction:
labels = labels.view(-1)
logits = logits.view(labels.shape[0], -1)
if self.return_z_loss:
loss, z_loss = self.loss_fn(logits, labels)
if self.pad_logits:
return MaskedLMOutputZLoss(
loss=loss,
ce_loss=loss.detach().clone() - z_loss,
z_loss=z_loss,
logits=self.pad_inputs(logits, indices, batch_size, seq_len)[0],
hidden_states=None,
attentions=None,
)
else:
return MaskedLMOutputZLoss(
loss=loss,
ce_loss=loss.detach().clone() - z_loss,
z_loss=z_loss,
logits=logits,
hidden_states=None,
attentions=None,
indices=indices,
cu_seqlens=cu_seqlens,
max_seqlen=max_seqlen,
batch_size=batch_size,
seq_len=seq_len,
labels=labels,
)
else:
loss = self.loss_fn(logits, labels)
# (G) 최종 출력: MaskedLMOutput (또는 MaskedLMOutputZLoss)
# pad_logits=True 면 pad_inputs() 통해 (batch_size, seq_len, vocab_size) 형태로 복원
if self.pad_logits:
return MaskedLMOutput(
loss=loss,
logits=self.pad_inputs(logits, indices, batch_size, seq_len)[0],
hidden_states=None,
attentions=None,
)
else:
return MaskedLMOutput(
loss=loss,
logits=logits,
hidden_states=None,
attentions=None,
indices=indices,
cu_seqlens=cu_seqlens,
max_seqlen=max_seqlen,
batch_size=batch_size,
seq_len=seq_len,
labels=labels,
)
Python
복사
•
unpad_embeddings
◦
if self.unpad_embeddings and (indices is None ...): 부분은 ModernBERT(FlexBert)의 가장 큰 특징 중 하나
▪
일반적으로 BERT는 batch 내 모든 시퀀스를 동일 길이로 맞추기 위해, 짧은 문장에는 ‘[PAD]’ 토큰을 추가
▪
Unpadding 시,
•
attention_mask를 보고, **“유효 토큰 위치”**만 골라 (nnz, d) 텐서로 만듦.
•
“인덱스(indices)”와 “시퀀스 누적 길이(cu_seqlens)”를 저장해, “이 토큰이 어느 시퀀스(batch)에서 몇 번째인가”를 추적.
▪
모델 계산
•
(nnz, d) 형태로만 연산해서 패딩 토큰을 연산 절약.
▪
Repadding 시,
•
indices를 다시 활용해, (nnz, d) 결과를 (batch*seq_len, d) 로 돌아가게 채움 → (batch, seq_len, d).
def unpad_input(
inputs: Tensor,
attention_mask: Tensor,
position_ids: Optional[Tensor] = None,
labels: Optional[Tensor] = None,
) -> Tuple[Tensor, Tensor, Tensor, int, Optional[Tensor], Optional[Tensor]]:
"""
attention_mask: (batch, seq_len) 형태
1이면 “해당 토큰이 유효", 0이면 “패딩 토큰”
함수는 다음 튜플을 반환:
unpadded_inputs: (nnz, d) — 실제로 유효 토큰만 모아둔 텐서
indices: (nnz,) — “원래 (batch*seq_len) 중 어느 위치가 유효했는지”
cu_seqlens: (batch+1,) — 각 배치별로 누적된 valid 토큰 수 (FlashAttention 등에서 “어느 토큰이 어느 시퀀스에 속하는지” 구분하기 위해)
max_seqlen_in_batch: int — 이 batch에서 가장 긴 유효 토큰 시퀀스 길이
unpadded_position_ids, unpadded_labels(옵션)
"""
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
# -> 각 배치별 유효 토큰 수
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
# -> 전체 (batch*seq_len) 중 유효 토큰의 위치만 가져옴.
# 플래튼(flat)된 텐서에서 mask=1인 위치의 인덱스”를 전부 추출해 1D로 갖고 있음.
# 이를 이용해 실제 값들을 “unpadding”된 텐서로 추출.
max_seqlen_in_batch = int(seqlens_in_batch.max().item())
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0))
# -> batch마다 누적된 길이 (Cumulative Sequence Lengths), ex) [0, 5, 8, ...]
# unpadded_inputs는 shape = (total_nnz, *...)
# 여기서 total_nnz = 전체 유효 토큰 수(batch 내 모든 시퀀스의 유효 토큰 합).
unpadded_inputs = inputs.view(batch * seqlen, *rest)[indices]
# 이렇게 하여 각 토큰에 해당하는 Position ID, Label만 남길 수 있음.
unpadded_position_ids = position_ids.flatten()[indices]
unpadded_labels = labels.flatten()[indices]
# 모델의 경우 (nnz, d) 형식으로 불필요한 pad 토큰 없이 계산.
# 당연히, attention, mlp 후에는 (nnz, d) 로 출력하게 된다.
return unpadded_inputs, indices, cu_seqlens, max_seqlen_in_batch, unpadded_position_ids, unpadded_labels
Python
복사
def pad_input(
inputs: Tensor,
indices: Tensor,
batch: int,
seqlen: int,
labels: Optional[Tensor] = None,
ignore_index: int = -100,
) -> Tuple[Tensor, Optional[Tensor]]:
"""
모델의 최종 출력 등( shape=(nnz, d) )을, “어느 (batch, seq) 위치”였는지 알아야 최종적으로 (batch, seqlen, d) 형태로 복원할 수 있음.
indices로 가리키는 위치에 inputs의 값들을 채워 넣음.
만약 1D(dim=1), 그저 output[indices]에 넣는 식.
Labels가 있다면, padded_labels[indices] = labels.
PAD 위치에는 ignore_index(ex: -100)로 채워서 “무시”되도록 처리.
반환: (padded_inputs, padded_labels) — 다시 (batch, seqlen, ...) 모양이 되어,
모델의 결과를 “원본 문장/토큰” 위치에 매핑.
"""
output = torch.zeros(batch*seqlen, *rest, dtype=..., device=...)
output[indices] = inputs
padded_inputs = output.view(batch, seqlen, *rest)
Python
복사
•
FlexBertModel (Unpadding) Encoder
◦
get_encoder_layer에서 분기:  layers.py#L687
layers.py#L687
class FlexBertUnpadEncoder(FlexBertEncoderBase):
"""
self.layers
num_hidden_layers만큼의 Transformer 레이어(get_bert_layer(config, layer_id=i))를 모듈리스트로 구성.
각각의 레이어에는 "unpadded_rope" 설정에 맞는 “RoPE + unpadded”가 적용된 Attention + MLP 조합이 들어 있음.
self.num_attention_heads
Attention 헤드 수 저장(로터리 계산, QKV 분할 등에 활용).
"""
def __init__(self, config: FlexBertConfig):
super().__init__()
self.layers = nn.ModuleList([get_bert_layer(config, layer_id=i) for i in range(config.num_hidden_layers)])
self.num_attention_heads = config.num_attention_heads
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
indices: Optional[torch.Tensor] = None,
cu_seqlens: Optional[torch.Tensor] = None,
max_seqlen: Optional[int] = None,
) -> torch.Tensor:
if indices is None and cu_seqlens is None and max_seqlen is None:
# (A) unpadded 로직이 아직 안 되어 있으면, 여기서 unpad 수행
...
else:
# (B) 이미 unpad 정보가 넘어왔다면, 그대로 레이어 수행
for layer_module in self.layers:
# “RoPE”라는 것은 “Q, K 벡터에 회전 변환(Rotary Embedding)”을 적용하여 위치 정보를 인코딩하는 방식. 코드는 보통 FlexBertUnpadRopeAttention 안에서 (nnz, 3 * hidden_dim)을 분리(QKV)한 뒤, RoPE 각도(cos/sin 기반)를 곱해 주거나(회전).그 후, FlashAttention2 등을 통해 Self-Attention을 수행.이때 “unpadded”이므로, “indices, cu_seqlens, max_seqlen”을 써서 FlashAttention2가 “실토큰만” 효율적으로 처리.
hidden_states = layer_module(
hidden_states,
cu_seqlens,
max_seqlen,
indices,
attn_mask=attention_mask,
)
return hidden_states
Python
복사
◦
레이어 모듈 가져오는 부분에 대한 결정 (LAYER2CLS)
# configuration: https://github.com/AnswerDotAI/ModernBERT/blob/9e997569ea015b7710db413db01eb217cb2ab201/src/bert_layers/configuration_bert.py#L50
LAYER2CLS = {
"unpadded_prenorm": FlexBertUnpadPreNormLayer,
"unpadded_compile_prenorm": FlexBertCompileUnpadPreNormLayer,
"unpadded_parallel_prenorm": FlexBertUnpadParallelPreNormLayer,
"unpadded_postnorm": FlexBertUnpadPostNormLayer,
"padded_prenorm": FlexBertPaddedPreNormLayer,
"padded_parallel_prenorm": FlexBertPaddedParallelPreNormLayer,
"padded_postnorm": FlexBertPaddedPostNormLayer,
}
def get_bert_layer(config, layer_id):
"""
인코더 레벨:
encoder_layer="base" → "unpadded_base" → FlexBertUnpadEncoder.
레이어 레벨:
bert_layer="prenorm" → "unpadded_prenorm" → FlexBertUnpadPreNormLayer.
"""
# 1) layer 명칭 결정. initial_bert_layer가 default None. 즉, initial_bert_layer(+ num_initial_layers) 옵션을 두면, “처음 N개의 레이어는 특별한 레이어 타입”, 그 뒤 레이어는 일반 타입(bert_layer)을 적용하는 식으로 세분화된 아키텍처 실험을 하거나 특수 규칙을 구현할 수 있습니다.
bert_layer = (
config.initial_bert_layer
if layer_id < config.num_initial_layers and config.initial_bert_layer is not None
else config.bert_layer
)
# 2) maybe_add_padding() -> "unpadded_" 붙일 수도
bert_layer = maybe_add_padding(config, bert_layer)
# 3) compile_model (default는 False) 이고 unpadded_prenorm이면 -> unpadded_compile_prenorm
if config.compile_model and bert_layer == "unpadded_prenorm":
bert_layer = "unpadded_compile_prenorm"
# 4) LAYER2CLS[bert_layer]로부터 실제 레이어 클래스
return LAYER2CLS[bert_layer](config, layer_id=layer_id)
Python
복사
◦
FlexBertUnpadPreNormLayer (default) 사용한다고 가정
▪
Transformer Layer에서 LayerNorm 을 적용하는 순서가 post-norm 이 아니라 pre-norm 으로 적용. 즉 pre-norm → MLP Attention → Residual Add 의 순서 이다.
class FlexBertUnpadPreNormLayer(FlexBertLayerBase):
"""
모든 단계가 전형적인 PreNorm(= Norm → Attn/MLP → Residual) 흐름.
"""
def __init__(self, config: FlexBertConfig, layer_id: Optional[int] = None):
super().__init__(config=config, layer_id=layer_id)
if config.skip_first_prenorm and config.embed_norm and layer_id == 0:
self.attn_norm = nn.Identity()
else:
self.attn_norm = get_norm_layer(config)
# unpadded_rope, unpadded_base, unpadded_alibi 등 → “어떤 Attention(FlashAttention2 + RoPE/ALiBi/…)” 인스턴스를 반환.
self.attn = get_attention_layer(config, layer_id=layer_id)
# MLP 쪽도 PreNorm으로 들어가기 전에 mlp_norm이 적용.
# norm layer는 여기에서 결정. https://github.com/AnswerDotAI/ModernBERT/blob/main/src/bert_layers/normalization.py#L99
self.mlp_norm = get_norm_layer(config)
self.mlp = get_mlp_layer(config, layer_id=layer_id)
def _init_weights(self, reset_params: bool = False):
super()._init_weights(reset_params)
if reset_params:
self.attn_norm.reset_parameters()
self.mlp_norm.reset_parameters()
def forward(
self,
hidden_states: torch.Tensor,
cu_seqlens: torch.Tensor,
max_seqlen: int,
indices: Optional[torch.Tensor] = None,
attn_mask: Optional[torch.Tensor] = None,
) -> torch.Tensor:
# 1) Attention 부분 (PreNorm) -> LayerNorm 적용
# 예를 들ㅇ... FlexBertUnpadRopeAttention(hidden_states_normed, cu_seqlens, max_seqlen, indices, attn_mask)
# Residual Add: hidden_states + [Attention 결과] = attn_out
attn_out = hidden_states + self.attn(self.attn_norm(hidden_states), cu_seqlens, max_seqlen, indices, attn_mask)
# 2) 토큰 단위의 MLP 부분 (BertResidualGLU). FlexBertGLU(attn_out_normed) or FlexBertMLP(...) → FFN(또는 GLU) 수행
# Residual Add: attn_out + [MLP 결과] -> 최종 shape = (nnz, hidden_dim) (unpadded 상태).
# 상위(Encoder) 레벨에서 마지막에 pad_input을 통해 (batch, seq_len, hidden_dim)으로 복원될 수 있음.
# https://github.com/AnswerDotAI/ModernBERT/blob/main/src/bert_layers/mlp.py#L200
return attn_out + self.mlp(self.mlp_norm(attn_out))
Python
복사
•
BertAlibiEncoder/Pooler
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
output_all_encoded_layers: Optional[bool] = True,
subset_mask: Optional[torch.Tensor] = None,
) -> List[torch.Tensor]:
"""
전통적으로 BERT는 CLS 토큰([CLS])의 위치(= 첫 번째 토큰 벡터)를 통해 문장 레벨 임베딩을 얻는다.
Pooler는 그 CLS 벡터를 Linear → Tanh로 한 번 더 가공하여 최종 문장 임베딩(pooled_output)을 만든다.
"""
...
# 1) attention_mask 전처리
# 일반적인 BERT 방식: (batch, seq_len)을 (batch, 1, 1, seq_len)로 확장해,
# 1인 곳에는 0 점수를, 0인 곳에는 -10000.0 점수를 부여(“사용하지 않겠다”는 의미).
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
# 2) unpad_input => 패딩된 토큰 제거
# BERT는 보통 배치 내 모든 문장을 같은 seq_len으로 맞추기 위해 [PAD]를 붙이지만,
# 실제 연산에서 [PAD] 토큰은 의미가 없으므로, “non-pad 토큰”만 모아서 연산하면 연산량을 줄일 수 있다.
# “unpadded” 상태가 되면 hidden_states shape가 (합계_실토큰수, hidden_dim) 등으로 압축.
attention_mask_bool = attention_mask.bool()
hidden_states, indices, cu_seqlens, _ = bert_padding.unpad_input(hidden_states, attention_mask_bool)
# 3) alibi_attn_mask 구성
alibi_attn_mask = attn_bias + alibi_bias
# 4) layer 스택 돌기
if subset_mask is None:
# 1) 모든 레이어를 순서대로 실행
for layer_module in self.layer:
hidden_states = layer_module(
hidden_states, # unpadded 상태에서 batch 정보를 관리하기 위함.
cu_seqlens,
seqlen,
subset_idx=None,
...
bias=alibi_attn_mask,
)
if output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
# 마지막 hidden_states shape = (unpadded_token_count, hidden_dim)
else:
# 예: 마스킹된 토큰(MLM)이나 CLS 토큰만 별도로 처리하려 할 때, 마지막 레이어에서 “partial indexing”을 수행.
# subset_mask != None → 마지막 레이어에서만 부분 토큰(subset_idx) 처리를 수행
...
# 5) re-pad_input
# 6) 결과 반환
Python
복사
•
FlexBertUnpadAttention
◦
Q/K/V 계산: self.Wqkv(hidden_states)
◦
로컬 vs. 글로벌? → self.sliding_window=(-1,-1)면 글로벌, 아니면 local=(win,win).
◦
FlashAttn2(varlen) 글로벌 어텐션에서 사용 시 → “(nnz,3,H,hdim)” → flash_attn_varlen_qkvpacked_func(...)
▪
O(nnz∗hdim) 로 효율적
◦
PyTorch SDPA 로컬 어텐션에서 사용 시 → pad back to (batch,seqlen) → attention → unpad. 따라서 패딩해서 넣어주고 계산하는 비효율 있음.
◦
Wo + dropout → 최종 (nnz,dim).
class FlexBertUnpadAttention(FlexBertAttentionBase):
"""Performs multi-headed self attention on a batch of unpadded sequences.
...
"""
def __init__(self, config: FlexBertConfig, layer_id: Optional[int] = None):
"""
헤드 계산: hidden_size를 num_attention_heads로 나누어, 헤드당 차원(attn_head_size)을 구함
여기서 Wqkv 는 Linear 로서 한 번에 Q, K, V를 concat 해서 계산하는 구조이고 출력 크기가 3 * all_head_size.
Wo 는 최종 출력하는 projection.
"""
super().__init__(config=config, layer_id=layer_id)
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(...)
self.num_attention_heads = config.num_attention_heads
self.attn_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attn_head_size
...
self.Wqkv = nn.Linear(config.hidden_size, 3 * self.all_head_size, bias=config.attn_qkv_bias)
self.Wo = nn.Linear(config.hidden_size, config.hidden_size, bias=config.attn_out_bias)
...
"""
config.global_attn_every_n_layers > 0:
매 n번째 레이어마다 글로벌 어텐션을 쓰고, 나머지는 로컬(슬라이딩 윈도우).
layer_id % config.global_attn_every_n_layers == 0 → 글로벌 레이어(sliding_window=(-1,-1)),
아니면 → “(sliding_window // 2, sliding_window // 2)”로 로컬 어텐션 크기 설정.
슬라이딩 윈도우 = (left, right) 문맥 범위를 정함.
예: (64,64)이면 한 토큰이 좌우 64개씩만 참조.
"""
if config.global_attn_every_n_layers > 0:
if config.sliding_window == -1:
raise ValueError("global_attn_every_n_layers` requires `sliding_window` to be set")
if layer_id % config.global_attn_every_n_layers != 0:
self.sliding_window = (config.sliding_window // 2, config.sliding_window // 2)
else:
self.sliding_window = (-1, -1)
else:
self.sliding_window = (config.sliding_window // 2, config.sliding_window // 2)
"""
self.use_fa2: config.use_fa2에 따라 FlashAttn2 사용 여부.
만약 import 실패(IMPL_USE_FLASH2=False)면, fallback → PyTorch의 scaled_dot_product_attention (SDPA).
로컬 슬라이딩 윈도우는 FlashAttn2에서만 지원됨 → PyTorch SDPA 사용 시에는 sliding_window>0이면 에러.
"""
if not IMPL_USE_FLASH2 and self.use_fa2:
logger.warn_once(...)
self.use_fa2 = False
if not self.use_fa2:
...
if self.sliding_window[0] > 0:
raise ValueError("Sliding window is not implemented for the PyTorch SDPA path. Use the FA2 backend.")
def forward(
self,
hidden_states: torch.Tensor,
cu_seqlens: torch.Tensor,
max_seqlen: int,
indices: torch.Tensor,
attn_mask: torch.Tensor,
) -> torch.Tensor:
"""
hidden_states: (total_nnz, dim)
이미 unpadded된 토큰 벡터 (PAD 토큰 제거).
nnz = non-zero tokens(=유효 토큰 수).
cu_seqlens: (batch+1,)
cumulative sequence lengths (FlashAttn varlen).
어떤 구간이 어떤 시퀀스인지 구분.
max_seqlen: int
이 배치에서 실제 시퀀스의 최대 길이.
indices: (total_nnz,)
“원래 (batch*seq_len)에서 유효 토큰 위치”를 나타내는 인덱스.
PyTorch SDPA 사용 시 pad/unpad을 다시 수행할 때 필요.
attn_mask: (batch, max_seqlen)
언패딩된 상황에서도, 어떤 토큰은 비활성화해야 하는지.
FlashAttn2가 mask를 직접 쓰진 않지만, PyTorch SDPA 경로에서는 필요.
"""
bs, dim = hidden_states.shape
# 한 번의 Linear로 Q/K/V concat.
# shape=(nnz, 3 * hidden_dim_per_head * num_heads).
qkv = self.Wqkv(hidden_states) # (nnz, 3 * all_head_size)
if self.use_fa2:
qkv = qkv.view(-1, 3, self.num_attention_heads, self.attn_head_size)
# shape => (nnz=6, 3, num_heads=2, head_dim=4)
# ex) (6,3,2,4)
convert_dtype = qkv.dtype not in (torch.float16, torch.bfloat16)
if convert_dtype:
orig_dtype = qkv.dtype
qkv = qkv.to(torch.bfloat16)
attn = flash_attn_varlen_qkvpacked_func(
qkv, # (6,3,2,4)
cu_seqlens=cu_seqlens, # [0,4,6]
max_seqlen=4,
dropout_p=self.p_dropout,
deterministic=self.deterministic_fa2,
window_size=self.sliding_window, # if (-1,-1) => global, else local
)
# 여기서 flash_attn_varlen_qkvpacked_func의 결과 shape는 (nnz, num_heads * head_dim) 즉, (nnz, dim).
attn = attn.to(orig_dtype) # type: ignore
else:
attn = flash_attn_varlen_qkvpacked_func(
qkv,
cu_seqlens=cu_seqlens,
max_seqlen=max_seqlen,
dropout_p=self.p_dropout,
deterministic=self.deterministic_fa2,
window_size=self.sliding_window,
)
attn = attn.view(bs, dim) # shape=(6,8)
# => bs=nnz, dim= (num_heads * head_dim)
else:
# unpadded 텐서를 바로 SDPA에 넣기는 어렵고, 한 번 (batch, seq_len)로 되돌려준 뒤(=pad), SDPA를 수행하고, 다시 unpad해서 “유효 토큰만” 쓸 수 있도록 하는 식으로 “pad → attention → unpad” 순서를 가지게 됩니다.
# FlashAttn 미설치 or other reason.
# bert_padding.pad_input(...) 로 다시 (batch, max_seqlen, 3*headDim)로 패딩한 뒤,
# q,k,v 분리 → F.scaled_dot_product_attention(...) 호출.
# 마지막에 unpad_input_only(...) 해서 다시 (nnz, dim) 복원.
qkv = bert_padding.pad_input(qkv, indices, cu_seqlens.shape[0] - 1, max_seqlen) # batch, max_seqlen, thd
# => (batch, max_seqlen, 3*dim)
unpad_bs, seqlen, _ = qkv.shape
qkv = qkv.view(unpad_bs, -1, 3, self.num_attention_heads, self.attn_head_size)
q, k, v = qkv.transpose(3, 1).unbind(dim=2) # b h s d
attn = F.scaled_dot_product_attention(
q,
k,
v,
dropout_p=self.p_dropout,
attn_mask=attn_mask[:, None, None, :seqlen].to(torch.bool).expand(unpad_bs, 1, seqlen, seqlen)
if self.use_sdpa_attn_mask
else None,
)
# => shape=(batch, heads, seqlen, head_dim)
attn = attn.transpose(1, 2).view(unpad_bs, -1, dim) # b s h d
# => transpose + reshape → (batch,seqlen,dim). shape=(batch, seqlen, dim)
attn = bert_padding.unpad_input_only(attn, torch.squeeze(attn_mask) == 1)
# unpad_input_only(...): (nnz, dim) 복귀.
# self.out_drop(...)로 attention output dropout (=attn_out_dropout_prob).
# 마지막으로 Wo + dropout 후, shape=(nnz,dim)로 리턴.
return self.out_drop(self.Wo(attn)) # Wo(=W_o)에 한 번 더 linear projection.
Python
복사
Conclusion
•
long context retrieval을 하기 위한 encoder 모델이 필요하다면 하면 좋은 베이스가 될 수 있을 것 같다.
◦
그런데 GTE 계열도 “충분히” 좋은 encoder backbone 이라서 ModernBERT 라고 엄청 특별한게 있는지는 잘 모르겠다. 심지어 GTE 계열은 multilingual backbone 도 있다.
◦
XLM-ModernBERT + (bge-styled) RetroMAE 하면 의미있을 것 같다.
•
Training Examples → 요즘 허깅페이스 팀이 엄청 많이 밀어주는 듯
◦
ColBERT 학습. Teacher Model 의 logits 값을 배우는 형태 (pylate)
◦
GLUE 분류 태스크로 만들어보기
◦
▪
“ModernBERT를 ‘문서-질의’ 임베딩으로 학습시켜, IR(Information Retrieval) 모델을 만들겠다.”
◦
▪
한국어 쿼리–문서 임베딩을 수행하는 DPR 스타일 모델. MultipleNegativesRankingLoss 사용.
▪
ModernBERT가 영어만으로 사전학습되었음에도 불구하고, 짧은 파인튜닝(예: 1M 한국어 triplet, 5epoch)만으로도 어느 정도(멀티링귤 모델보다 조금 낮은 수준) 한국어 성능을 끌어올렸다는 의미.
관련 영상
