

LLM은 방대한 양의 텍스트 데이터를 학습하여 인간의 언어를 이해하고 생성하는 능력을 갖춘 AI 모델입니다. 이러한 모델은 논리적 추론, 문제 해결, 창의적 사고까지 수행하며 기존의 특화된 인공지능(Narrow AI)과는 차별화된 능력을 보여줍니다.
이러한 특성 덕분에 많은 연구자들은 LLM을 일반 인공지능(AGI, Artificial General Intelligence)의 초기 형태 또는 그 전 단계로 바라보기 시작했습니다.
하지만 이러한 능력은 어떻게 얻어지는 걸까요? 마치 사람이 언어를 배우는 과정과 유사하게, LLM도 끊임없는 학습을 통해 언어를 익힙니다.
본 아티클에서는 다음과 같은 구성으로 되어 있습니다.
•
개략적으로 대형 언어 모델의 학습 과정을 설명합니다
•
이를 보다 직관적으로 이해할 수 있도록, LLM의 학습 과정을 아기의 언어 습득 과정에 비유해 설명하고자 합니다.
대형 언어 모델의 학습 과정
AGI는 인간처럼 언어를 이해하고 문제를 해결하기 위해 대규모 언어 모델(LLM)을 다음과 같은 방식으로 학습합니다.
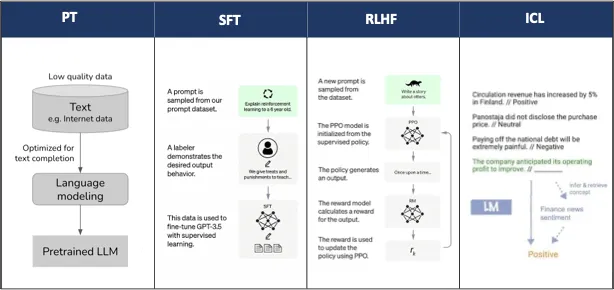
1. 사전 학습 (PT) – 방대한 데이터로 기본 언어 능력을 습득
2. 지도 학습 (SFT) – 특정 작업을 위한 미세 조정
3. 인간 피드백 강화 학습 (RLHF) – 인간 피드백을 반영해 모델 최적화
4. 맥락 학습 (ICL) – 예시를 통해 새로운 문제를 추론
이 과정을 통해 LLM은 점점 더 정교한 문제 해결 능력을 갖추게 됩니다. 이제 좀 더 자세하게 알아보겠습니다.
직관적인 설명

우리가 Chatgpt 등을 통해 사용하는 서비스는 AGI라고도 생각할 수도 있을 정도로 일반적인 작업들을 잘 수행할 수 있습니다. 왠만한 성인 수준에 맞먹을 정도가 되었죠.
하지만, 우리가 처음 모델을 만들땐 학습이 전혀 안된 아기 상태와 같습니다.
우리는 이제 AGI(한글 발음 : 아지) LLM을 이제 막 말을 배우기 시작한 어린아이(아기)라고 생각해봅시다.
그래서, 부모님의 마음으로 AGI LLM을 키워보도록 합니다.
1. PRE-TRAIN
AGI LLM 학습은 방대한 텍스트 데이터를 모델에게 학습하는 것(사전 학습)부터 시작합니다. 이는 어린 아이한테 책을 읽어 주면서 많은 언어를 주입시켜주는 것과 비슷합니다.
엄마는 아기 앞에서 많은 얘기를 하고 아기는 자연스럽게 언어를 따라하게 됐었죠. 대형언어모델도 사전 학습이라는 과정을 통해 어린 아이가 엄마한테 배우듯 방대한 텍스트를 학습하여 자연스럽게 엄아의 말 따라하게 됩니다.


1.1. Next Word Prediction
LLM이 학습하는 방식은 Next word prediction으로 주어진 문장에서 다음에 올 단어를 예측하는 방식입니다.
예를 들어, “곰 세마리가 한 집에 있어” 라는 문장이 있으면 이 문장을 가지고 다음과 같은 학습을 수행합니다. 문장의 앞부분이 주어졌을 때, 바로 다음에 어떤 단어가 나올지를 가르치는 것이죠.
1.2. Pretrain의 효과
Pretrain의 효과 우리가 모국어를 배우면 문법 같은 걸 따로 배우지 않아도 자연스럽게 모국어를 할 수 있듯이 LLM으로 하여금 문법적인 지식의 주입 없이도 자연스럽게 말할 수 있도록 하는 장점이 있습니다. (물론 대신 방대한 양의 학습이 필요합니다.)
또한, General한 task에 대한 간접적인 경험을 갖게 된다는 이점이 있습니다. 그래서 Specific task에 따로 학습을 하지 않더라도 수행할 능력을 가질 수 있습니다.

2. Supervised Fine Tuning

아이가 이제는 어느정도 말을 잘 따라하네요. 이제 괜찮을까요?
아니죠. 이대로면 아기는 아직 앵무새처럼 말을 따라하는 것만 가능합니다. 이젠 단순히 말을 따라하는 것이 아닌 원하는 대로 능동적으로 대화하는 방법을 가르쳐야 합니다.
따라서, 아이 앞에서 아빠와 엄마가 대화를 하면서 아이가 대화 방식을 따라하도록 유도해야 합니다.
그러기 위해선 어떻게 학습해야 할까요?
2.1. Chat Template
첫번째는 발화 주체와 발화 턴일겁니다. 대화를 하기 위해서는 user와 assistant와 같은 역할을 지정하여 발화의 주체에 대해서 습득하고, 대화의 순서에 대해서 학습해야 합니다. 그러기 위해서 다음과 같은 형태로 주어진 데이터를 사용합니다.
"""<|im_start|>user
달과 해 중에 뭐가 더 크나요? <|im_end|>
<|im_start|>assistant
해가 더 큽니다!<|im_end|>
"""
Plain Text
복사
chat data template
위의 데이터에서는 user가 “달과 해 중에 뭐가 더 크나요?”를 묻고 있고, 이에 대해서 assistant가 “해가 더 큽니다”라고 답하고 있습니다. 이런 데이터들을 통해서 LLM은 user가 질문하고 assistant가 답하고 이런 발화 구성에 대해서 학습할 것입니다.
2.2. SFT dataset
두번째는, 이제 대화에 대해서 학습을 시켜줘야 합니다. 질문에 대해서는 응답을 하고 요청에 대해선 수행을 해주는 것이 대화라는 것을 학습을 하는 것이죠.
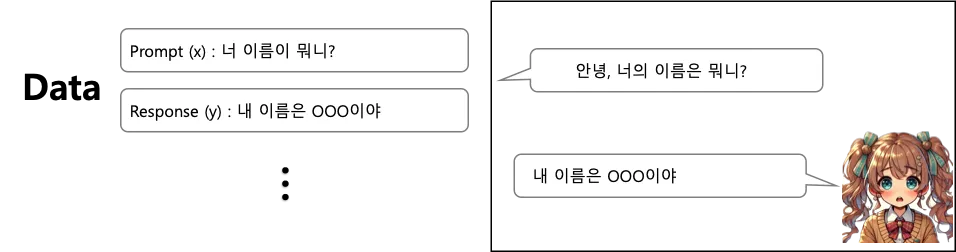
이처럼 대화 형식의 데이터를 다량 학습해주면 자연스럽게 대화 방식을 습득하여, 오른쪽과 같이 기존 데이터셋에 없던 대화여도 수행할 수 있게 됩니다.
3. Reinforcement Learning with Human Feedback (RLHF)
이제 아이는 어느 정도 성장해서 학교에 입학했습니다. 이제 다 키운 걸까요??
아닙니다. 아이는 성장하면서 당면한 과제에 적응하기 위해 체계적인 학습 및 피드백을 받게 됩니다.
예를 들어, 한국에서 살아왔다고 해서 국어를 100점을 받는게 아니듯이 더 잘하기 위한 학습이 필요합니다.
학창 시절에는 수많은 피드백을 통해 지속적으로 더 좋은 점수를 받을 수 있게 학습을 하죠

LLM도 강화 학습을 통해 보상을 최대화 하는 방향으로 지속적으로 학습하여 개선을 합니다.

예컨데 위의 그림과 같이 “한글이 언제 만들어졌어?”라는 질문이 주어졌을 때 이에 대한 답변으로 “세종대왕이 만들었습니다.”라는 답변은 적절하지 않습니다. 따라서, 이 경우 LLM 응답에 대해서는 낮은 점수 혹은 페널티가 주어집니다. 반대로, “1443년 겨울입니다”라는 응답은 옳은 응답입니다. 이 경우에는 높은 점수 혹은 보상이 주어집니다. 결과적으로 LLM은 이런 피드백을 기반으로 점수를 높이거나 보상을 많이 받을 수 있도록 자신의 응답을 조정하게 됩니다.
4. In-context Learning
이제 아이는 자라고 자라 면접을 준비하게 되었습니다. 우리 아이는 과연 면접을 잘 볼 수 있을까요.
면접에서는 어떤 돌발적인 질문이나 상황이 펼쳐질지 모릅니다.
그러나, 사람은 면접의 분위기 등 상황에 맞춰서 유동적으로 대처할 수 있습니다. 보통 이런 친구를 센스가 있다고 하죠.
그리고, 이젠 다 컸으니 아이를 믿어야죠.

LLM에서는 이런 문맥과 상황에 따라 대처하는 능력을 In-context learning이라고 합니다.
4.1. Few shot Learning
few-shot learning은 질문을 던지기 전에 몇가지 예시를 주는 방식입니다.
면접에서 앞에 분들의 질문에 대한 대답을 보고 미리 준비하듯이 llm도 예시가 주어졌을때 더 좋은 응답이 가능합니다.
예를 들어, 아래와 같이 질문을 던질 수 있습니다.
미국 -> 워싱턴
일본 -> 도쿄
중국 -> 베이징
한국 ->
Plain Text
복사
그럼 LLM은 높은 확률로 "서울"이라고 답을 합니다. 당연히 한국 → 만 주어졌을 때보다 더 높은 확신을 갖고 답할 수 있습니다.
4.2. Prompt Engineering
LLM은 아직은 사회 초년의 못 미더운 아이라고 생각하고 문제를 줄 때는 좀 더 명확하고 구체적으로 문제를 주는게 좋습니다. 이러한 과정을 LLM에서는 프롬프트 엔지니어링이라고 합니다.
x 앨런 튜링에 대해 무언가 써주세요
o 앨런 튜링의 과학적인 업적 및 역사적 역할에 대해 전문 과학 기자처럼 알려줘
x 가장 큰 나라를 알려줘
o 인구가 가장 많은 나라를 알려줘
Plain Text
복사
문제를 명확하고 구체적으로 주세요!
첫째, 세 개의 문단으로 구분된 텍스트를 한 문장으로 요약하세요.
둘째, 요약문을 프랑스어로 번역하세요.
셋째, 프랑스어 요약문에 있는 각 이름을 나열하세요.
Plain Text
복사
복잡한 작업이라면 단계별로 요청해주세요.
위와 같이, 사람에게 주어지듯 문제를 구체적으로 주고, 복잡한 문제는 단계적으로 분할해서 주는 등 똑같은 문제라도 문제 방식에 따라서 llm의 성능은 바뀔 수 있습니다. 
Ending
여기까지 한다면 llm은 이제 충분히 사회의 일원이 되어 험난한 세상을 헤쳐나갈 수 있을 것입니다.
