


LLM Merging의 세계
<정의>
인공지능 기술의 급속한 발전으로 대형 언어 모델(Large Language Model, LLM)은 자연어 처리 분야에 혁명을 일으켰습니다. 그러나 각 언어 모델은 어떻게 fine-tuning (미세조정) 하느냐에 따라서 고유한 강점과 약점을 가지고 있습니다. 근래에는 이 모델들을 효과적으로 결합하는 '모델 병합(Model Merging)' 기술이 주목받고 있습니다. LLM Merging은 마치 요리사가 여러 재료를 조합해 새로운 맛을 만들어내는 것처럼, 다양한 모델의 장점을 결합하여 더 강력하고 범용적인 인공지능을 만들어내는 기술입니다.
<대상>
이 기술은 단순히 더 큰 모델을 만드는 것이 아니라, 기존 모델들의 지식과 능력을 효과적으로 조합하는 데 초점을 맞춥니다. 이를 통해 개별 모델의 한계를 극복하고, 다양한 작업에서 향상된 성능을 제공하는 새로운 모델을 만들 수 있습니다. 하나의 예시로 수학을 잘 푸는 모델과 코딩을 잘 만드는 모델과 외국어 능력이 뛰어난 모델들을 병합하였을 때 세 가지 성능에서 모두 뛰어난 범용적인 LLM을 만들 수 있게 되는 결과가 나왔다는 것입니다. 이러한 LLM Merging 기술은 AI의 새로운 지평을 열고 있으며, 앞으로 더욱 발전된 형태의 인공지능 모델 개발에 중요한 역할을 할 것으로 기대됩니다.
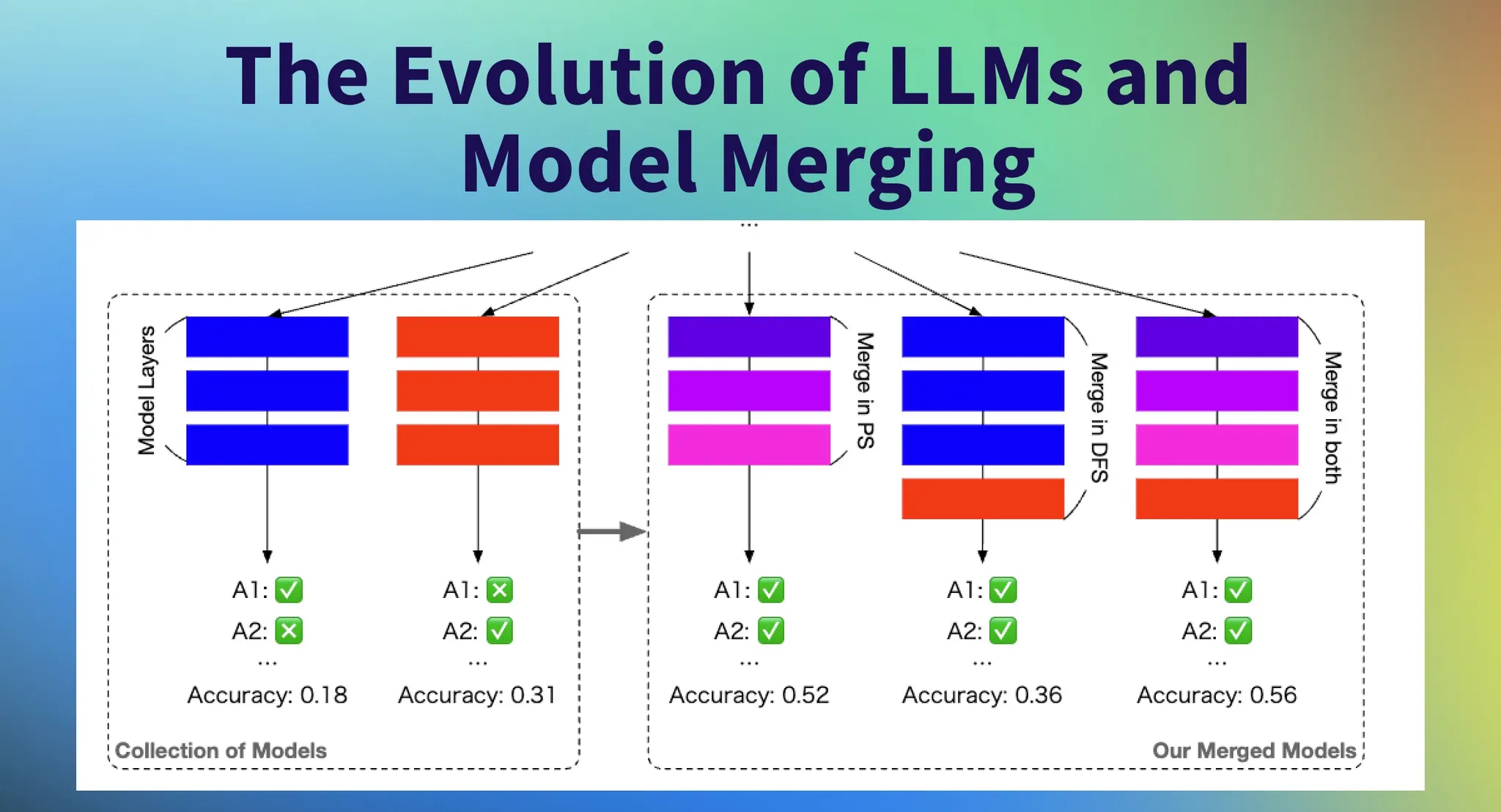
주요 모델 병합 기법

모델 병합 방법론 유형
1. SLERP (Spherical Linear Interpolation)
SLERP는 모델 병합에서 전통적인 가중치 평균화의 한계를 극복하기 위해 개발된 방법입니다. 이 기법은 고차원 공간에서 각 부모 모델의 고유한 특성과 곡률을 보존하면서 모델들을 섬세하게 혼합합니다.
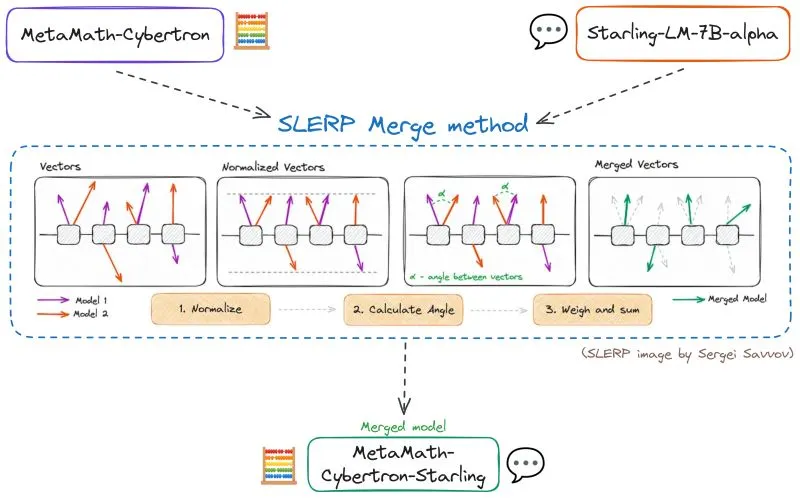
SLERP 기법 작동 원리에 대한 개념도
•
장점:
◦
부드러운 전환: 고차원 벡터 보간에서 매우 중요한 부드러운 파라미터 전환을 보장합니다.
◦
특성 보존: 두 부모 모델의 고유한 특징과 곡률을 유지합니다.
◦
정교한 블렌딩: 벡터 공간의 기하학적, 회전적 특성을 고려하여 두 모델의 특성을 정확히 반영하는 혼합을 생성합니다.
•
SLERP 구현 단계:
1.
정규화: 입력 벡터를 단위 길이로 정규화하여 방향에 초점을 맞춥니다.
2.
각도 계산: 벡터 간의 각도를 내적을 사용하여 결정하고, 보간 인자와 벡터 간 각도를 바탕으로 스케일 인자를 계산합니다.
3.
벡터 가중 및 합산: 원래 벡터에 이 인자들을 가중치로 부여하고 합산하여 보간된 벡터를 얻습니다.
SLERP는 파라미터 간 부드러운 전환과 각 모델의 고유한 특성 보존 능력으로 인해 복잡한 모델 병합 작업에 선호되는 방법입니다. 그러나 SLERP는 두 모델을 동시에 병합하는 데 효과적이지만, 쌍별 조합으로 제한된다는 한계가 있습니다.
코드:
2. Task Vector Arithmetic
Task Vector Arithmetic은 '작업 벡터'라는 혁신적인 개념을 도입하여 신경망의 행동을 수정하는 새로운 패러다임을 제시합니다.
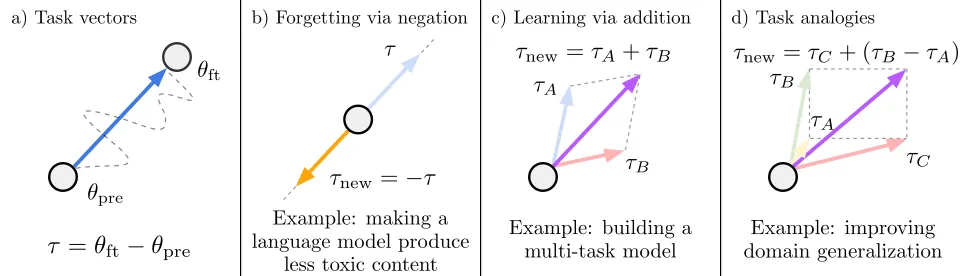
작업 벡터 산술 (Task Vector Arithmetic)에 대한 개념도
•
작동 원리:
◦
작업 벡터는 사전 학습된 모델의 가중치 공간에서 특정 작업에 대한 성능 향상 방향을 나타냅니다.
◦
이 벡터들은 부정, 덧셈 등의 산술 연산을 통해 조작될 수 있어 모델의 행동을 목표에 맞게 변경할 수 있습니다.
•
주요 기능:
◦
성능 감소를 위한 부정: 작업 벡터를 부정하면 해당 작업에 대한 모델의 성능은 감소시키면서 다른 제어 작업에 대한 행동은 유지합니다.
◦
다중 작업 개선을 위한 덧셈: 여러 작업 벡터를 더하면 여러 작업에 대한 성능을 동시에 향상시킬 수 있습니다.
◦
유추적 작업 개선: 관련된 작업의 벡터들을 결합하여 심지어 해당 작업의 데이터를 사용하지 않고도 새로운 작업에 대한 성능을 향상시킬 수 있습니다.
•
장점:
◦
효율적인 모델 편집: 성능 향상, 편향 완화, 새로운 정보로 모델 업데이트 등을 간단하고 효과적으로 수행할 수 있습니다.
◦
다양한 모델과 작업 적용성: 여러 종류의 모델과 다양한 작업에 효과적으로 적용될 수 있습니다.
Task Vector Arithmetic은 다양한 작업에서 신경망 모델의 성능을 제어하고 개선하기 위한 새롭고 다재다능한 접근 방식을 제공합니다.
코드:
3. TIES (Targeted Interpolation with Error-driven Scaling)
TIES는 여러 모델을 병합할 때 발생하는 파라미터 간 간섭 문제를 해결하기 위해 개발된 혁신적인 방법입니다. 전통적인 모델 병합 방법들이 직면하는 주요 과제, 특히 여러 모델을 병합할 때 성능이 크게 저하되는 문제를 해결합니다.
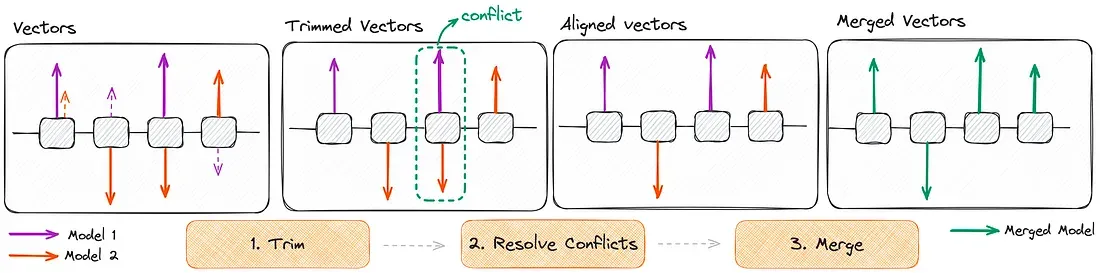
TIES 기법 작동 원리에 대한 개념도
•
TIES의 주요 단계:
1.
파라미터 리셋: 파인튜닝 중 미미하게 변경된 파라미터를 원래 값으로 되돌립니다. 이 단계는 중복성을 줄이는 데 도움이 됩니다.
2.
부호 충돌 해결: 모델 간 파라미터 값의 부호가 다를 경우 이를 해결합니다.
3.
선택적 병합: 최종적으로 합의된 부호와 일치하는 파라미터만 병합합니다.
•
장점:
◦
간섭 문제 해결: 특히 부호 간섭 문제를 효과적으로 해결합니다.
◦
성능 향상: 다양한 설정에서 기존 병합 방법들보다 우수한 성능을 보여줍니다.
TIES-Merging 접근 방식은 여러 실험 설정에서 기존의 여러 병합 방법들을 능가하는 성능을 보여주었습니다. 특히 간섭 문제, 그중에서도 부호 간섭 문제를 효과적으로 해결하여 병합된 모델의 전반적인 성능을 향상시킵니다.

4. DARE (Domain Adaptive Risk Exploration)
DARE는 재학습이나 GPU 없이도 모델을 병합할 수 있는 혁신적인 접근 방식입니다. 이 방법은 주로 유사한(동종의) 모델의 매개변수를 학습하여 새로운 능력을 얻는 데 초점을 맞춥니다. TIES와 유사한 접근 방식을 사용하지만 두 가지 주요 차이점이 있습니다:
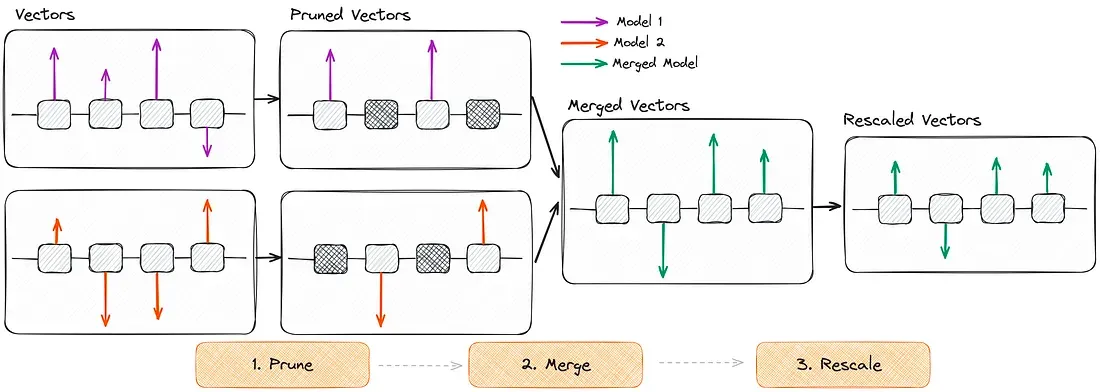
DARE 기법 작동 원리에 대한 개념도
•
주요 특징:
1.
델타 파라미터 가지치기: 대부분의 델타 파라미터(파인튜닝된 파라미터와 사전 학습된 파라미터의 차이)를 식별하고 제거합니다. 이 과정은 모델의 능력에 크게 영향을 미치지 않으며, 큰 모델일수록 이러한 파라미터를 더 많이 제거할 수 있습니다.
2.
가중치 재조정: 모델의 출력 기대값을 대략적으로 변경되지 않도록 유지하기 위해 가중치를 조정하는 단계를 포함합니다. 이는 스케일 인자를 사용하여 모델의 재조정된 가중치를 기본 모델의 가중치에 더하는 과정을 포함합니다.
•
DARE의 작동 단계:
1.
가지치기: 파인튜닝된 가중치를 원래의 사전 학습된 값으로 재설정하여 불필요한 파라미터 변경을 줄입니다.
2.
병합: 여러 모델의 파라미터를 평균화하여 단일의 통합된 모델을 생성합니다.
3.
재조정: 병합된 모델의 가중치를 조정하여 예상된 성능을 유지합니다.
DARE는 파라미터를 전략적으로 가지치기하고 재조정함으로써 언어 모델을 병합하는 독특하고 효율적인 방법을 제공합니다. 이 방법을 통해 광범위한 재학습 없이도 향상되고 다양한 능력을 갖춘 모델을 만들 수 있습니다.
코드:  MergeLM
MergeLM
LLM 모델 병합 코드 예시: SLERP 기법을 사용하여 Llama2 모델 융합
위에 소개드린 LLM(Large Language Model) 병합 기법들 중 하나인 SLERP(Spherical Linear Interpolation)를 이용해 Llama2 기반 모델들을 병합하는 방법에 대해 알아보겠습니다.
LLM 병합 대회 스타터 키트 소개
본 예시는 현재 진행하고 있는 NeurIPS 2024 LLM-Merging 대회의 스타터 키트를 기반으로 하여 작성하였습니다. 이 스타터 키트는 LLM 병합 실험을 위한 기본 코드와 환경을 제공합니다.
스타터 키트 GitHub 링크: LLM-Merging
SLERP를 이용한 Llama2 모델 병합 예제
다음은 Llama2 기반 모델을 SLERP 기법을 통해 병합하는 예제 코드입니다:
import os
from llm_merging.merging.Merges import Merges
from llm_merging.utils import merge_slerp, load_merged_model, load_config
class SlerpLlama2(Merges):
def __init__(self, name):
super().__init__(name)
# 설정 파일 경로 지정 및 로드
current_file = os.path.abspath(__file__)
root_dir = os.path.dirname(os.path.dirname(current_file))
self.config_yaml_path = os.path.join(root_dir, 'configs', 'llama2_SLERP_V1.yaml')
if not os.path.exists(self.config_yaml_path):
raise FileNotFoundError(f"설정 파일을 찾을 수 없습니다: {self.config_yaml_path}")
self.config = load_config(self.config_yaml_path)
for key, value in self.config.items():
setattr(self, key, value)
def merge(self):
# 모델 로드 및 병합
self._load_huggingface_models_and_configs()
all_models = list(self.loaded_models.values())
if len(all_models) != 2:
raise ValueError("SLERP 병합은 정확히 두 개의 모델이 필요합니다.")
t = self.parameter_lambdas[0]
self.merged_model = merge_slerp(all_models, t)
# 기본 모델 및 토크나이저 로드
self._load_base_model()
self._load_tokenizer()
# 병합된 모델을 기본 모델에 적용
huggingface_config = list(self.loaded_configs.values())[0] if self.loaded_configs else None
self.base_model = load_merged_model(self.base_model, self.merged_model, huggingface_config)
self.base_model.eval()
return self.base_model
Python
복사
설정 파일 (YAML)
병합 과정에 필요한 설정은 YAML 파일에 정의합니다. 다음은 예시 설정 파일입니다:
list_models:
- ["abcdabcd987/gsm8k-llama2-7b-lora-16", "636b5eb8da724edae406ba69ef90fd06478e6df7"]
- ["FinGPT/fingpt-forecaster_dow30_llama2-7b_lora", "69f77190315afdb03a889d89bf2a0f932b311617"]
base_model_name: "meta-llama/Llama-2-7b-hf"
base_model_revision_id: "01c7f73d771dfac7d292323805ebc428287df4f9"
max_seq_len: 1024
max_gen_len: 64
architecture: "decoder"
parameter_lambdas: [0.5, 0.5]
YAML
복사
모델 등록 파일 (Setup.py)
이 setup.py 파일에는 다양한 모델 병합 방법들을 등록할 수 있습니다. 여기에는 SLERP, TIES, DARE 등 다양한 병합 알고리즘이 포함되어 있으며, Flan-T5, Llama2, Llama3, Mistral 등 여러 모델에 대한 병합 방법을 아래와 같이 등록가능합니다:
from setuptools import setup
setup(
name="llm_merging",
version=1.0,
description="starter code for llm_merging",
install_requires=[
"torch", "ipdb", "pyyaml"
],
packages=["llm_merging"],
entry_points={
"llm_merging.merging.Merges": [
"avg_flan_t5 = llm_merging.merging.FlanT5Avg:FlanT5Avg",
"slerp_flan_t5 = llm_merging.merging.SlerpFlanT5:SlerpFlanT5",
"ta_flan_t5 = llm_merging.merging.TAFlanT5:TAFlanT5",
"ties_flan_t5 = llm_merging.merging.TIESFlanT5:TIESFlanT5",
"dare_flan_t5 = llm_merging.merging.DAREFlanT5:DAREFlanT5",
"dare_ties_flan_t5 = llm_merging.merging.DARETIESFlanT5:DARETIESFlanT5",
"ms_flan_t5 = llm_merging.merging.ModelStockFlanT5:ModelStockFlanT5",
"avg_llama = llm_merging.merging.LlamaAvg:LlamaAvg",
"avg_llama2 = llm_merging.merging.AvgLlama2:AvgLlama2",
"slerp_llama2 = llm_merging.merging.SlerpLlama2:SlerpLlama2",
"ta_llama2 = llm_merging.merging.TALlama2:TALlama2",
"ties_llama2 = llm_merging.merging.TIESLlama2:TIESLlama2",
"dare_llama2 = llm_merging.merging.DARELlama2:DARELlama2",
"dare_ties_llama2 = llm_merging.merging.DARETIESLlama2:DARETIESLlama2",
"ms_llama2 = llm_merging.merging.ModelStockLlama2:ModelStockLlama2",
"slerp_llama3 = llm_merging.merging.SlerpLlama3:SlerpLlama3",
"slerp_mistral = llm_merging.merging.SlerpMistral:SlerpMistral",
]
},
)
Python
복사
실행 방법
스타터 키트를 사용한 모델 병합은 다음 단계에 따릅니다.
1.
환경 설정:
먼저, Hugging Face 토큰이 필요합니다. https://huggingface.co/settings/tokens 에서 Authentication Token을 발급합니다.
그 다음, 터미널에서 다음 명령어를 실행합니다:
bash
Copy
export CUDA_VISIBLE_DEVICES=0
export HUGGINGFACE_HUB_CACHE=/tmp/
conda env create -f environment.yml --name llm-merging
conda activate llm-merging
export PYTHONPATH=`pwd`
export HF_AUTH_TOKEN="여기에_본인의_토큰을_입력하세요"
Shell
복사
2.
설치:
그 후 아래의 명령어를 실행하여 등록된 모델들을 설치합니다:
python llm_merging/setup.py install
Shell
복사
3.
병합 실행:
원하는 병합 방법을 선택하여 다음과 같이 실행합니다:
python llm_merging/main.py -m {병합_방법_이름}
# SLERP를 사용하여 LLaMA2 모델을 병합하려면 다음과 같이 실행합니다:
python llm_merging/main.py -m slerp_llama2
Shell
복사
이 과정을 통해 다양한 LLM 병합 방법을 쉽게 실험해볼 수 있습니다. setup.py 파일에 정의된 여러 병합 방법 중 원하는 것을 선택하여 실행할 수 있으며, 각 방법은 해당하는 Python 모듈에 구현되어 있습니다.
import torch
def match_tensor_shapes(tensor_a, tensor_b):
"""
Match the shapes of two tensors by padding the smaller one.
Args:
tensor_a (torch.Tensor): First input tensor.
tensor_b (torch.Tensor): Second input tensor.
Returns:
tuple: A tuple containing the two tensors with matched shapes.
"""
size_a, size_b = tensor_a.shape, tensor_b.shape
if size_a == size_b:
return tensor_a, tensor_b
max_size = torch.maximum(torch.tensor(size_a), torch.tensor(size_b))
def pad_to_size(tensor, target_size):
padding = [(0, max_dim - tensor_dim) for tensor_dim, max_dim in zip(tensor.shape, target_size)]
padding = sum((p for p in reversed(padding)), ())
return torch.nn.functional.pad(tensor, padding)
tensor_a = pad_to_size(tensor_a, max_size)
tensor_b = pad_to_size(tensor_b, max_size)
return tensor_a, tensor_b
Python
복사
이 함수는 두 텐서의 크기를 동일하게 맞추는 역할을 합니다. 크기가 다른 경우 작은 텐서를 0으로 패딩하여 큰 텐서의 크기에 맞춥니다.
def slerp(t, tensor_a, tensor_b, dot_threshold=0.9995, eps=1e-8):
"""
Perform Spherical Linear Interpolation (SLERP) between two tensors.
Args:
t (float): Interpolation parameter, between 0 and 1.
tensor_a (torch.Tensor): First input tensor.
tensor_b (torch.Tensor): Second input tensor.
dot_threshold (float): Threshold for dot product to switch to linear interpolation.
eps (float): Small value to avoid division by zero.
Returns:
torch.Tensor: Interpolated tensor.
"""
def normalize(tensor):
norm = torch.norm(tensor)
return tensor / norm if norm > eps else tensor
tensor_a = normalize(tensor_a)
tensor_b = normalize(tensor_b)
dot = torch.sum(tensor_a * tensor_b)
if torch.abs(dot) > dot_threshold:
return (1 - t) * tensor_a + t * tensor_b
theta_0 = torch.acos(dot)
sin_theta_0 = torch.sin(theta_0)
theta_t = theta_0 * t
sin_theta_t = torch.sin(theta_t)
s0 = torch.sin(theta_0 - theta_t) / sin_theta_0
s1 = sin_theta_t / sin_theta_0
return s0 * tensor_a + s1 * tensor_b
Python
복사
이 함수는 두 텐서 사이에서 구면 선형 보간(SLERP)을 수행합니다. 이는 두 텐서를 구면 상에서 부드럽게 interpolate하는 방법입니다.
def merge_slerp(models, t):
"""
Merge two models using Spherical Linear Interpolation (SLERP).
Args:
models (list): List of two model state dictionaries to be merged.
t (float): Interpolation parameter, between 0 and 1.
Returns:
dict: Merged model state dictionary.
"""
merged_model = {}
all_parameter_names = models[0].keys()
for parameter_name in all_parameter_names:
tensor_a = models[0][parameter_name]
tensor_b = models[1][parameter_name]
tensor_a, tensor_b = match_tensor_shapes(tensor_a, tensor_b)
merged_model[parameter_name] = slerp(t, tensor_a, tensor_b)
return merged_model
Python
복사
이 함수는 SLERP 방법을 사용하여 두 모델의 상태 사전을 병합합니다. 각 파라미터에 대해 SLERP를 적용하여 새로운 모델을 생성합니다.
SLERP를 이용한 LLM 모델 병합 실행 결과
코드 실행과정:

SLERP LLAMA2 결과물:
{"cosmos_qa": {"accuracy": 0.22}, "xsum": {"rouge1": 0.097, "rouge2": 0.017, "rougeL": 0.075, "rougeLsum": 0.081}}
LaTeX
복사
mergekit: 간편한 모델 병합 도구
더 간단한 모델 병합을 원하신다면, mergekit을 사용해 보세요. mergekit은 사전 학습된 언어 모델을 병합하기 위한 툴킷으로, 위에서 언급한 알고리즘들을 모두 지원하며 설정이 매우 간단합니다.
mergekit 설치 및 사용 방법
1.
설치:
python3 -m pip install --upgrade pip
git clone https://github.com/cg123/mergekit.git
cd mergekit && pip install -q -e .
Plain Text
복사
2.
YAML 설정 파일 작성:
models:
- model: mistralai/Mistral-7B-v0.1
- model: WizardLM/WizardMath-7B-V1.0
parameters:
density: 0.5
weight:
- filter: mlp
value: 0.5
- value: 0
- model: codellama/CodeLlama-7b-Instruct-hf
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
normalize: true
int8_mask: true
dtype: float16
YAML
복사
3.
병합 실행:
mergekit-yaml ultra_llm_merged.yaml output_folder \
--allow-crimes \
--copy-tokenizer \
--out-shard-size 1B \
--low-cpu-memory \
--write-model-card \
--lazy-unpickle
Plain Text
복사
참고 사항으로 merge를 할때에는 CPU만으로도 모델 병합이 가능하지만, 8GB 이상의 VRAM이 있으면 속도를 높일 수 있습니다.
결론 및 전망
이 글은 LLM Merging 기술을 통해 기존 모델들의 장점을 효과적으로 결합하여 더 똑똑하고 유연한 AI를 만들 수 있는 것을 목표로 작성되었습니다. 앞으로 이 기술은 사용자의 필요에 맞는 맞춤형 AI 어시스턴트 제작이나 특정 도메인에 특화된 모델을 빠르게 생성하는 데 활용될 것으로 보입니다.
앞에서 알아본 기법들에 보면, 전체적인 모델 병합은 결국 모델을 병합할 때 파라미터 값들을 어떻게 효율적으로 합치는지에 대한 고찰입니다. 이러한 다양한 모델 병합 기법들은 각각의 장단점을 가지고 있으며, 특정 상황과 요구사항에 따라 적절한 방법을 선택하여 사용할 수 있습니다. 이 기법들의 발전은 LLM의 성능과 효율성을 더욱 향상시키는 데 크게 기여할 것으로 기대됩니다.
더불어, 모델 병합 기술의 발전은 AI 모델의 지속 가능성과 효율성 측면에서도 큰 의미를 갖습니다. 새로운 모델을 처음부터 학습시키는 대신, 기존 모델들의 지식을 재활용하고 조합함으로써 계산 자원과 에너지 소비를 크게 줄일 수도 있습니다. 또한, 모델 병합 기술은 AI의 민주화에도 기여할 수 있습니다. 대규모 컴퓨팅 자원을 보유한 기관이나 기업이 아니더라도, 기존의 공개된 모델들을 효과적으로 조합하여 새로운 능력을 가진 AI를 만들 수 있게 되기 때문입니다. 이는 더 많은 연구자와 개발자들이 AI 기술 발전에 참여할 수 있는 기회를 제공할 것입니다.
마지막으로, 모델 병합 기술의 발전은 AI의 설명 가능성(Explainability)과 통제 가능성(Controllability) 향상에도 기여할 수 있습니다. 각 모델의 특성을 이해하고 이를 선택적으로 결합함으로써, 우리는 AI의 동작 원리를 더 잘 이해하고 원하는 방향으로 조절할 수 있게 될 것입니다.
앞으로 LLM Merging 기술이 어떻게 발전하고, 어떤 새로운 가능성을 열어갈지 지켜보는 것은 매우 흥미로울 것입니다. 우리는 이 기술을 통해 더 효율적이고, 더 강력하며, 더 유연한 AI 시스템을 만들어 나가면 좋을 것 같습니다!
긴글 읽어주셔서 감사드립니다.
