
도입
•
LLM의 구조는 크게 전체 파라미터가 모두 연결되어 있는 dense 모델과 여러 개의 전문가 모델이 gate로 연결되어 있는 sparse 모델 2종류로 나눌 수 있음
•
GPT-3를 비롯하여 LLM의 발전은 그 동안 dense 모델이 주류를 이루었으나 GPU의 연산 속도 및 메모리 등 H/W의 물리적 한계로 인하여 모델 크기의 증가 속도가 둔화됨
•
대안으로 최근에는 모델 크기 대비 연산량이 적은 Mixture-of-Expert(MoE)에 대한 관심이 높아지고 있음
•
이 아티클에서는 이미 사전 학습한 LLM을 기반으로 MoE 구조의 모델로 튜닝하는 효율적이고 흥미로운 방법론 2가지에 대하여 소개함
•
리뷰 논문
◦
◦
Parameter Efficient MoE
개요
•
한줄 요약 : vector 혹은 low-rank matrix(LoRA)를 적용하여 비용 효율적으로 MoE 구조의 모델을 학습할 수 있는 방법론 제안
•
기존의 MoE 구조에서 expert들은 보통 고차원의 dense layer로 구성되어 있어 학습 파라미터가 크고 메모리가 많이 필요했음
•
이 논문에서는 LoRA, (IA)^3 등과 같은 parameter-efficient fine-tuning 기법을 MoE 구조에 적용시키는 방법론을 제안
•
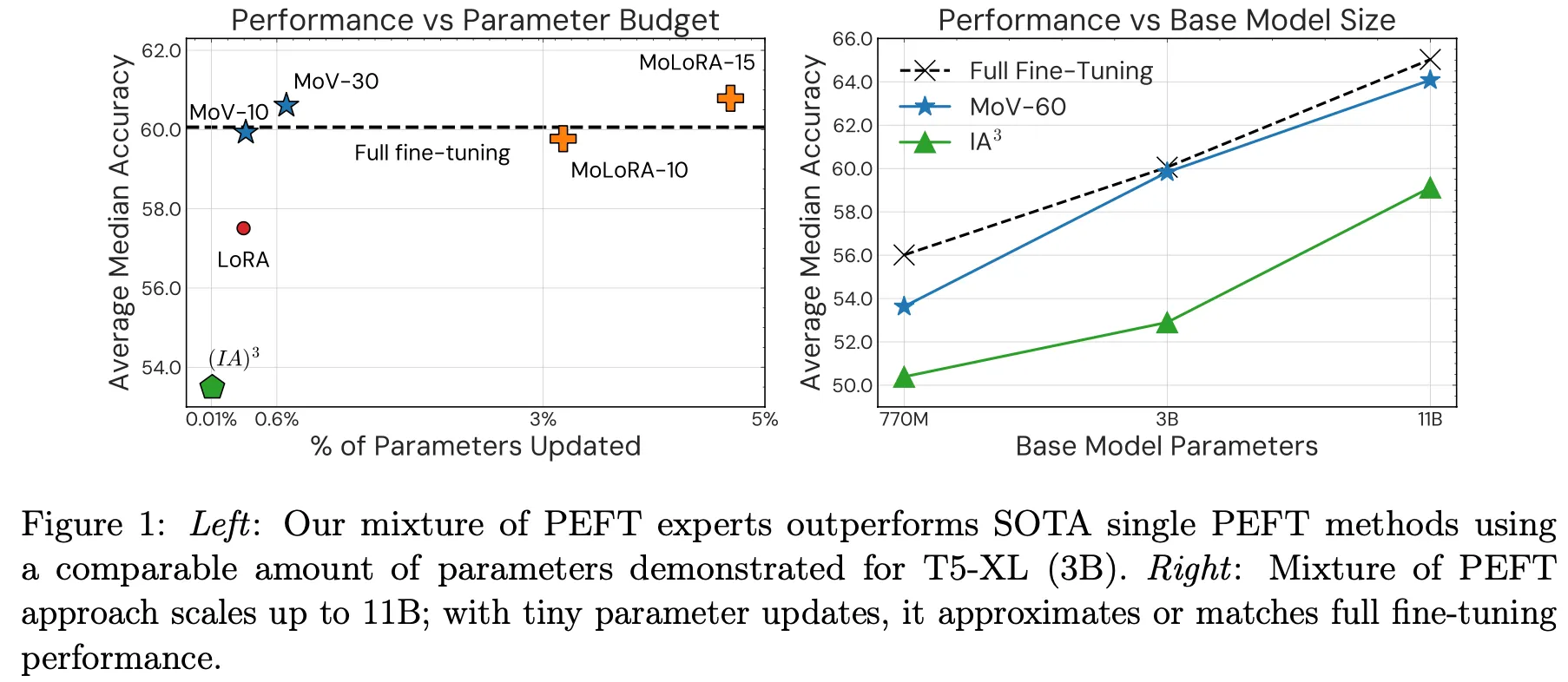
Seq2seq 구조인 T5 모델에 적용. LoRA, (IA)^3 대비 약 8~14% 성능 향상이 관찰되었고 3B, 11B 모델에서는 불과 1% 수준의 파라미터 update만으로 full fine-tuning과 거의 유사한 성능을 달성
Method
•
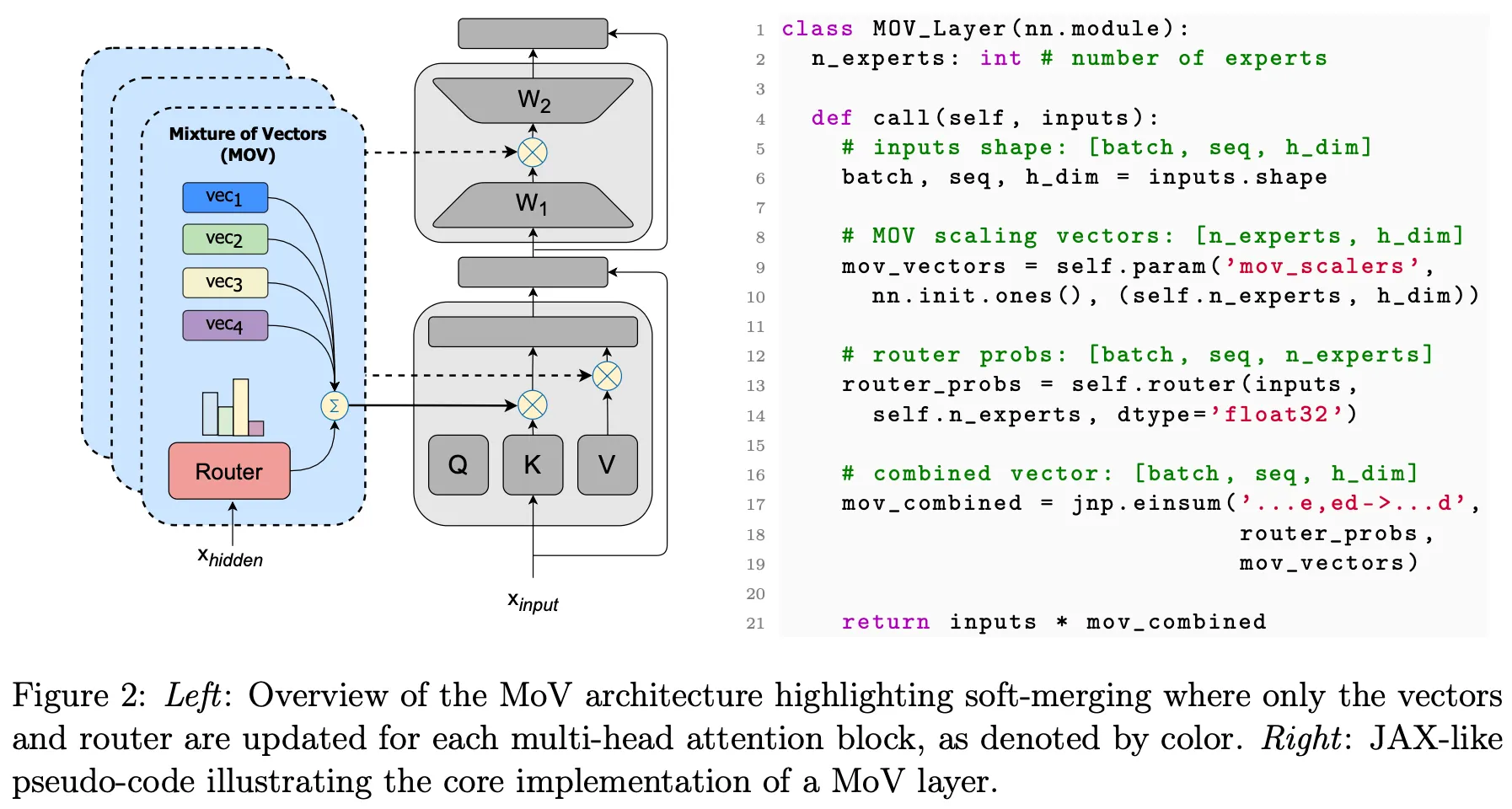
이미 pretraining한 dense model (T5)을 기반으로 fine-tuning하여 MoE 모델을 만드는 방식
•
일반적으로 transformer 기반의 MoE의 경우 full feed-forward network layer에 다수의 expert network를 넣음 (e.g., Switch Transformer; https://arxiv.org/abs/2101.03961). 이 때 FFN layer를 제외한 나머지 파라미터는 pretrained model로 initialize하고 expert layer는 from scratch로 학습을 수행
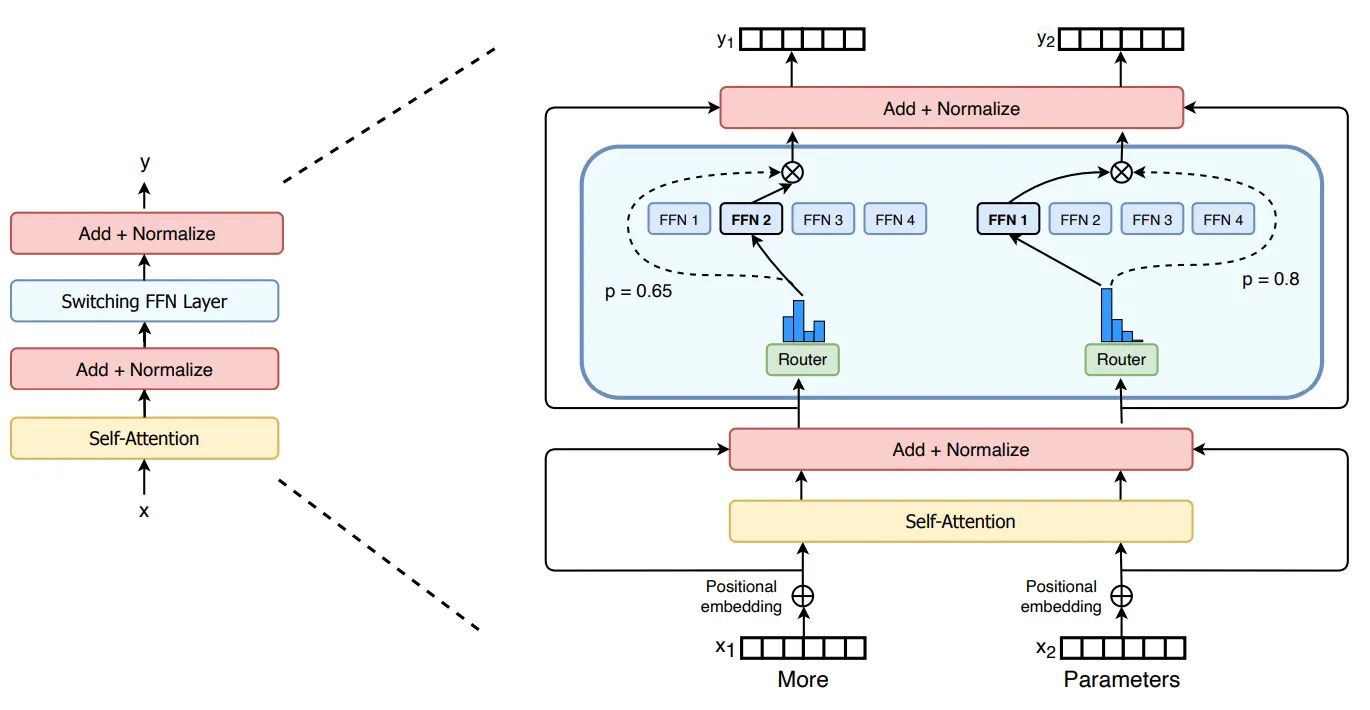
SwitchFormer 구조
•
MoV(Mixture of Vectors) 및 MoLORA(Mixture of LoRAs)의 경우 기존의 expert network 대신 PEFT adapter를 사용하는 방식. fine-tuning할 때 기존 pretrained model의 파라미터를 모두 사용하며, expert와 router layer만 from scratch로 학습을 수행함.
Results
•
Pretrained 모델로 T5 v1.1+LM 770M, 3B, 11B 모델을 사용하였으며 P3 dataset으로 tuning을 수행함
•
T0 모델을 fine-tuning baseline으로 사용하였고 기존 PEFT 방법론으로는 (IA)^3과 LoRA를 사용
•
총 8가지 dataset으로 zero-shot 성능 평가를 진행
•
3B 모델 기준으로 0.68%(MoV-30)~4.69%(MoLORA-15) 정도의 파라미터 학습만으로 fine-tuning 경우와 비슷한 성능을 달성
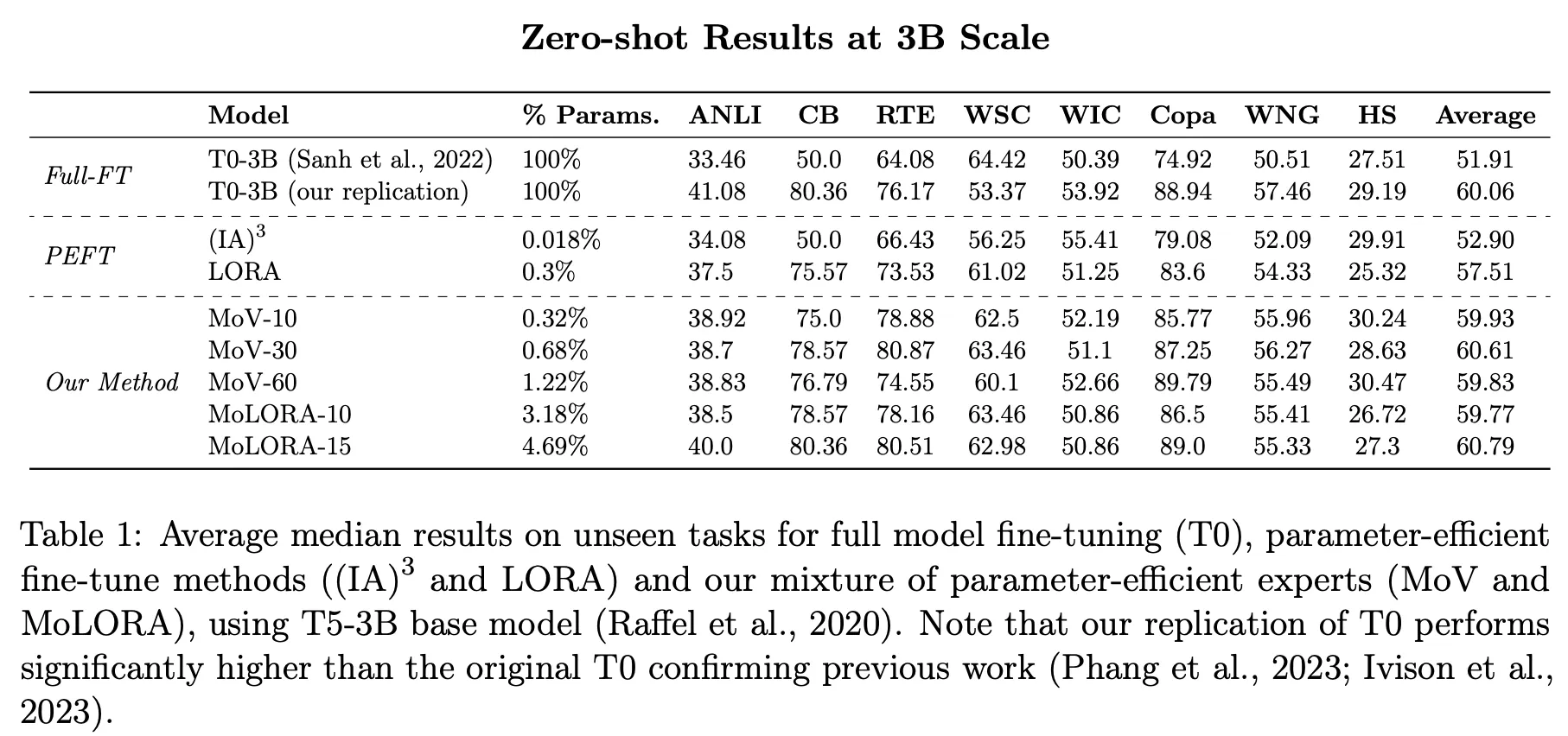
•
백본 모델(backbone mode 또 foundation model)이 큰 경우 PEFT로 인한 효과가 더 좋음
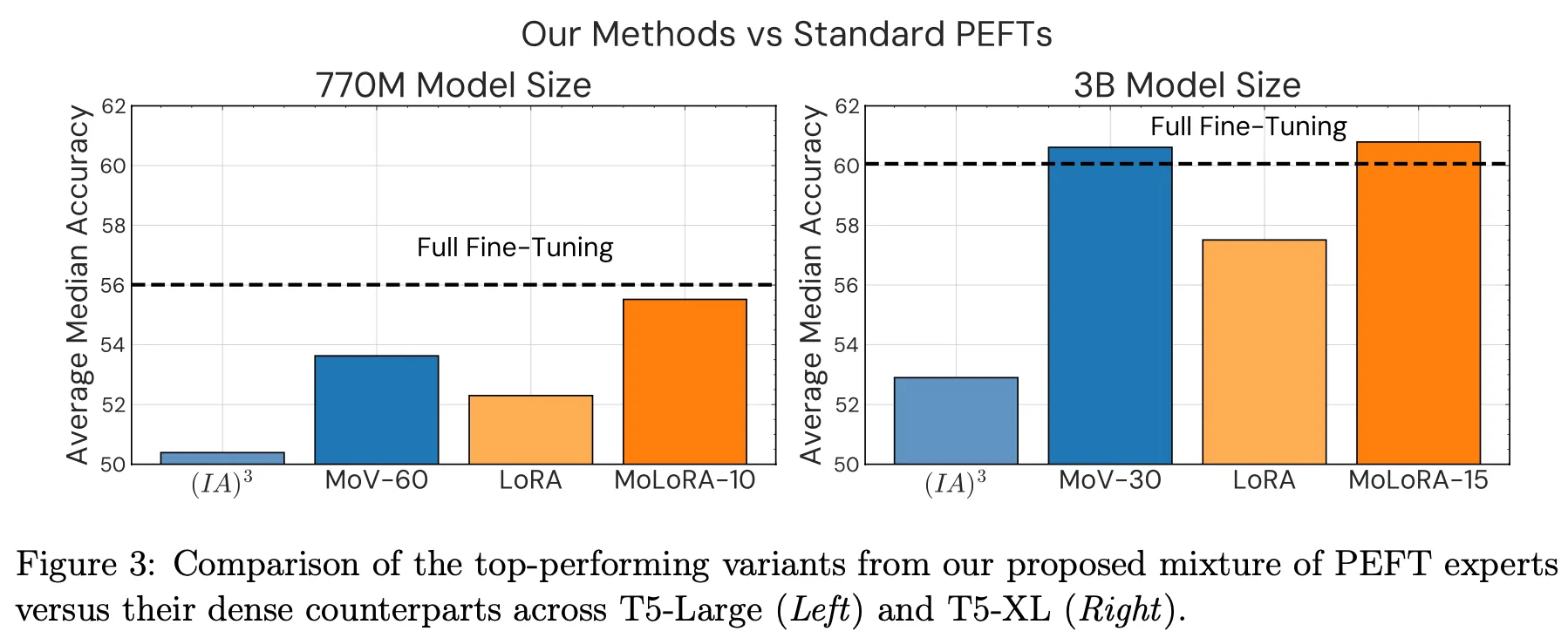
•
Router layer의 입력으로 token sequence를 넣은 경우가 sentence embedding을 넣은 것 대비 더 좋음
•
Expert 수가 증가할수록 성능이 좋아지는 경향성이 있으나 어느 정도 증가하면 saturation됨
•
Top-k에서 k를 늘릴 경우 추가 개선을 기대할 수 있음
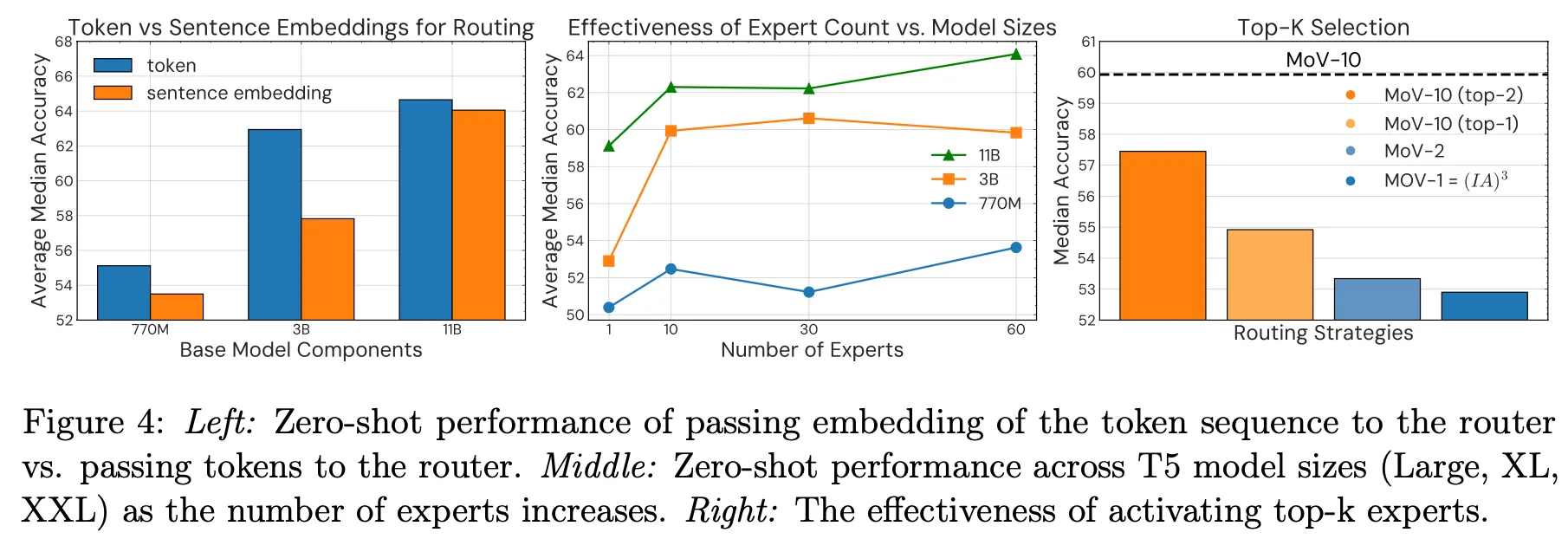
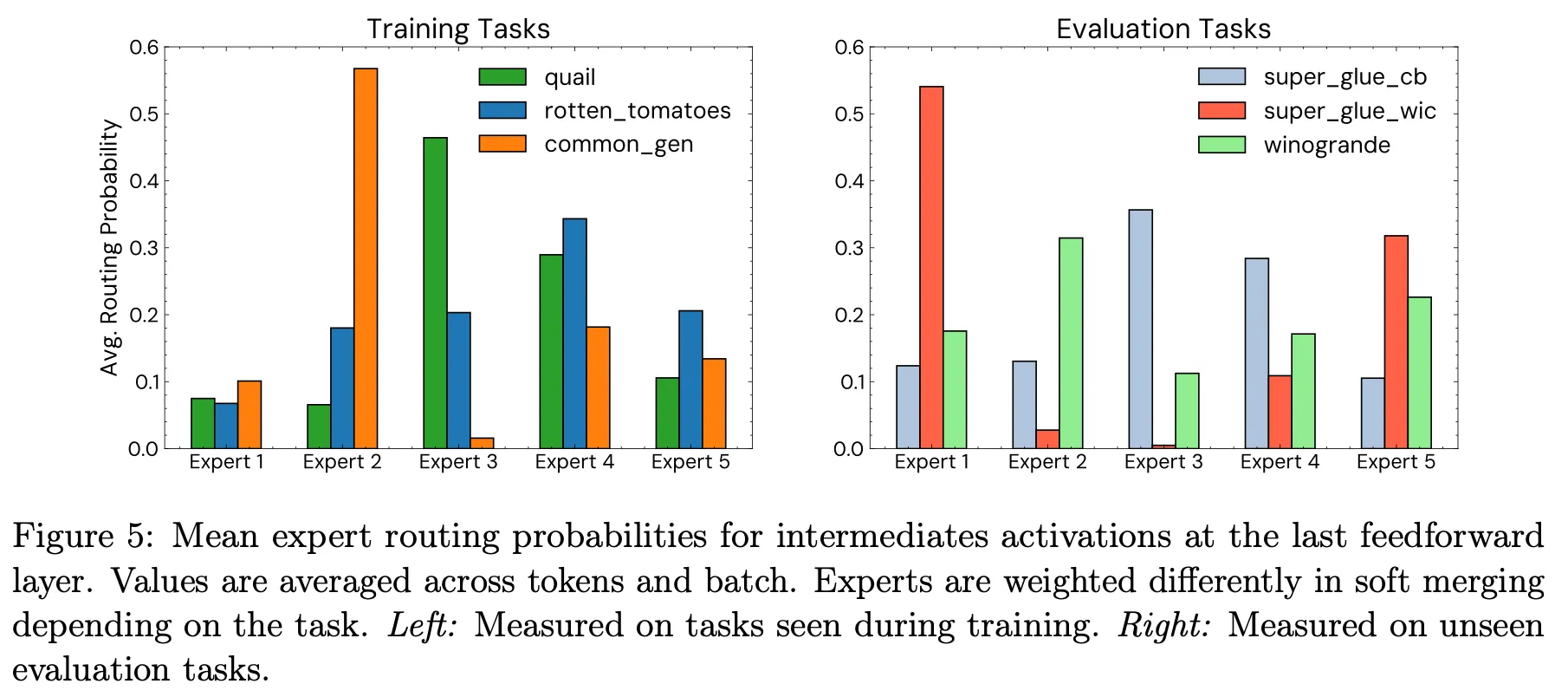
•
Task별로 활성화되는 expert를 분석하면 확실히 역할별로 잘 학습이 된 것을 알 수 있음
CALM
개요
•
Composition to Augment Language Model(CALM)
•
한줄 요약 : 서로 다른 expertise를 갖는 두 개의 LM의 능력을 모두 효율적으로 활용하면서 parameter efficient하게 학습할 수 있는 방법론 제안
•
각 LM의 pre-train된 parameter는 학습하지 않고 2개 이상의 LM을 서로 연결하는 composition layer만 학습을 하는 방식으로 실제 학습하는 파라미터가 적음
•
각 LM이 잘하는 능력도 유지한 채 이것을 조합하여 해결할 수 있는 문제(composition task)도 해결하는 모델을 효과적으로 만들 수 있음을 보임
Method
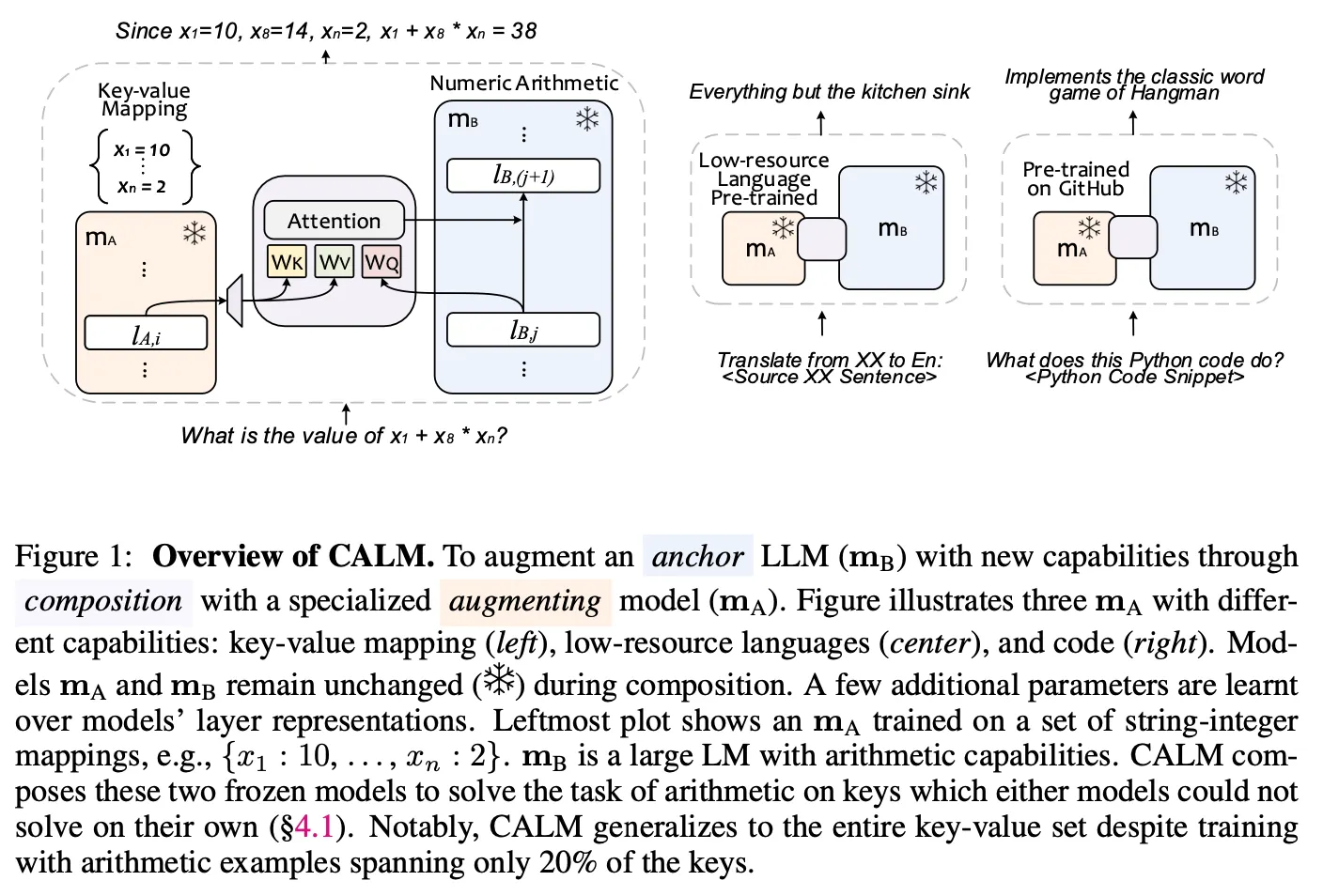
•
Anchor 모델()와 augmenting 모델()은 각각 독립적으로 pretrain된 LM (e.g., 계산을 잘하는 모델, low-resource 언어를 이해하는 모델, Code를 이해하는 모델 등)
•
두 모델을 composition layer를 통하여 '연결’함
◦
composition layer 수 : n
◦
composition layer는 와 의 layer output의 cross attention으로 구성
▪
query :
▪
key, value :
◦
각 composition layer는 every layer의 output 끼리 연결
◦
두 모델간 hidden dimension이 다르므로 의 output에 projection layer를 추가
결론
•
실험 세팅
◦
: PaLM2-XXS 모델을 domain-specific data로 파인튜닝한 모델
◦
: PaLM2-XS or PaLM2-S 모델을 사용
◦
•
Key-value arithmetic
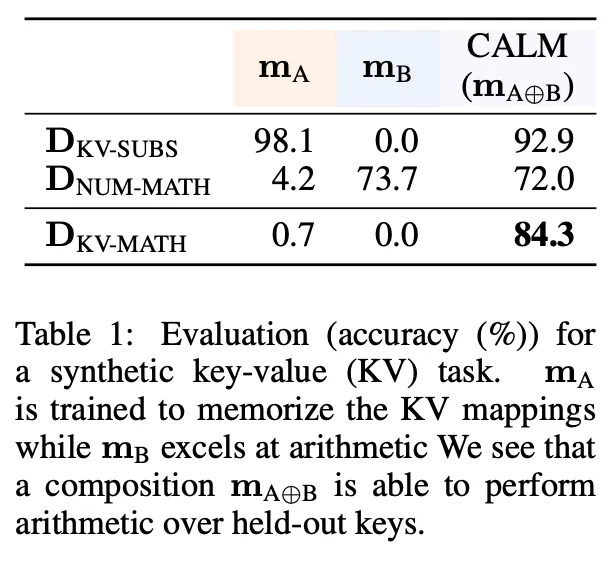
◦
: 문자에 대응되는 수를 기억하는 모델
◦
: 연산 능력을 보유한 모델
◦
KV-SUB : <K1>+<K2>-<K3> → 10+22-24 로 변환하는 task
◦
NUM-MATH : 10+22-24 → 8 수식 계산하는 task
◦
KV-MATH : <K1>+<K2>-<K3> → 8 문자를 숫자로 치환 후 계산하는 task
◦
CALM을 통하여 및 각각 존재하는 능력을 합쳐서 수행할 수 있음을 확인
•
Low-resource language
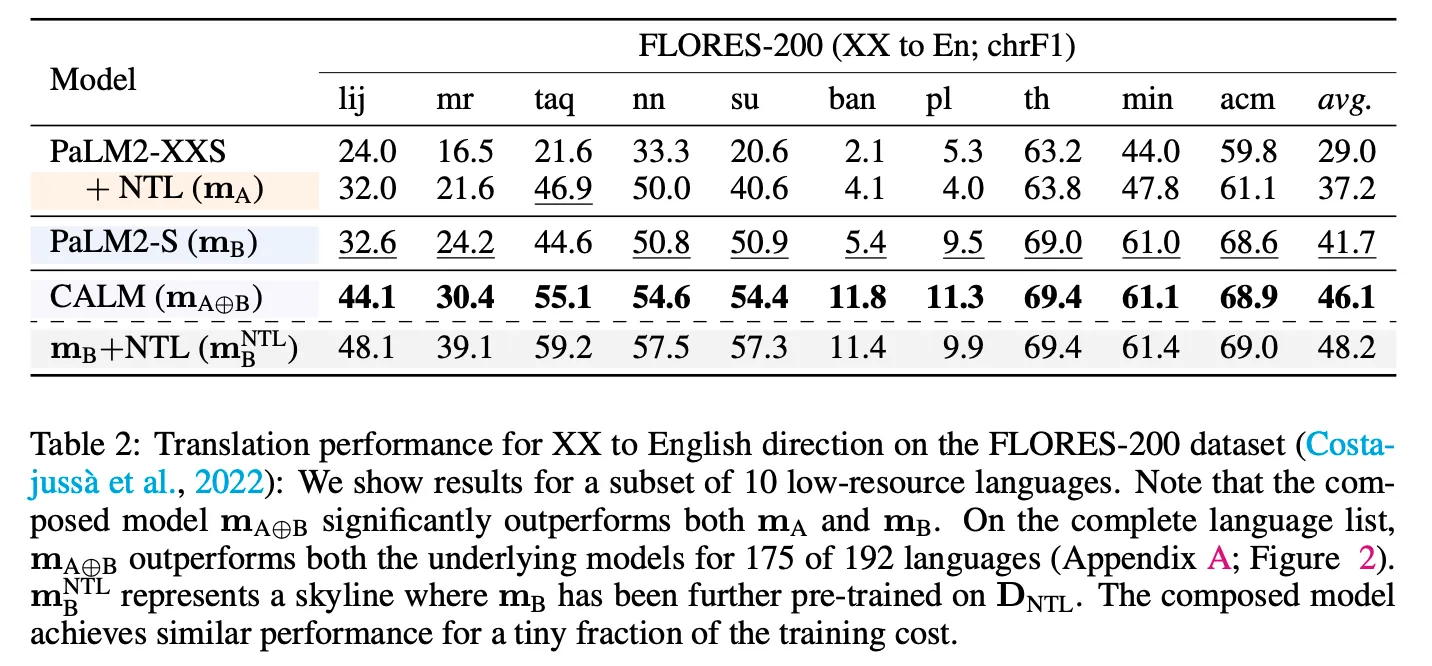
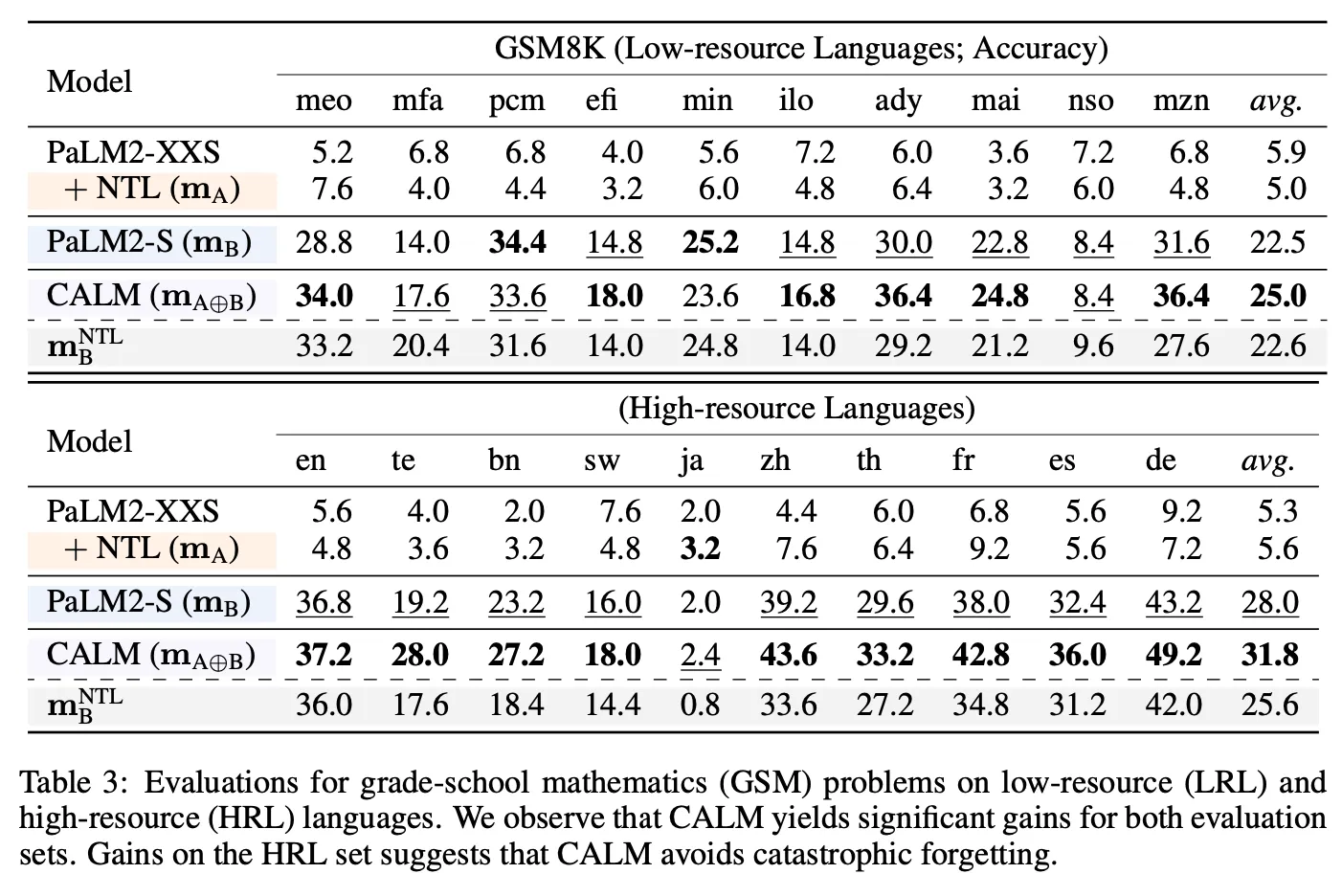
◦
번역, 다국어 GSM8K
◦
: low-resource language를 이해하는 모델
◦
: 일반 언어 모델
◦
: 를 low-resource language로 추가 튜닝
◦
CALM을 통하여 번역 task에서 reference 대비 훨씬 좋은 성능을 보여주며 GSM8K의 경우 low-resource 및 high-resource 언어 모두에서 가장 좋은 성능을 보임
•
Code
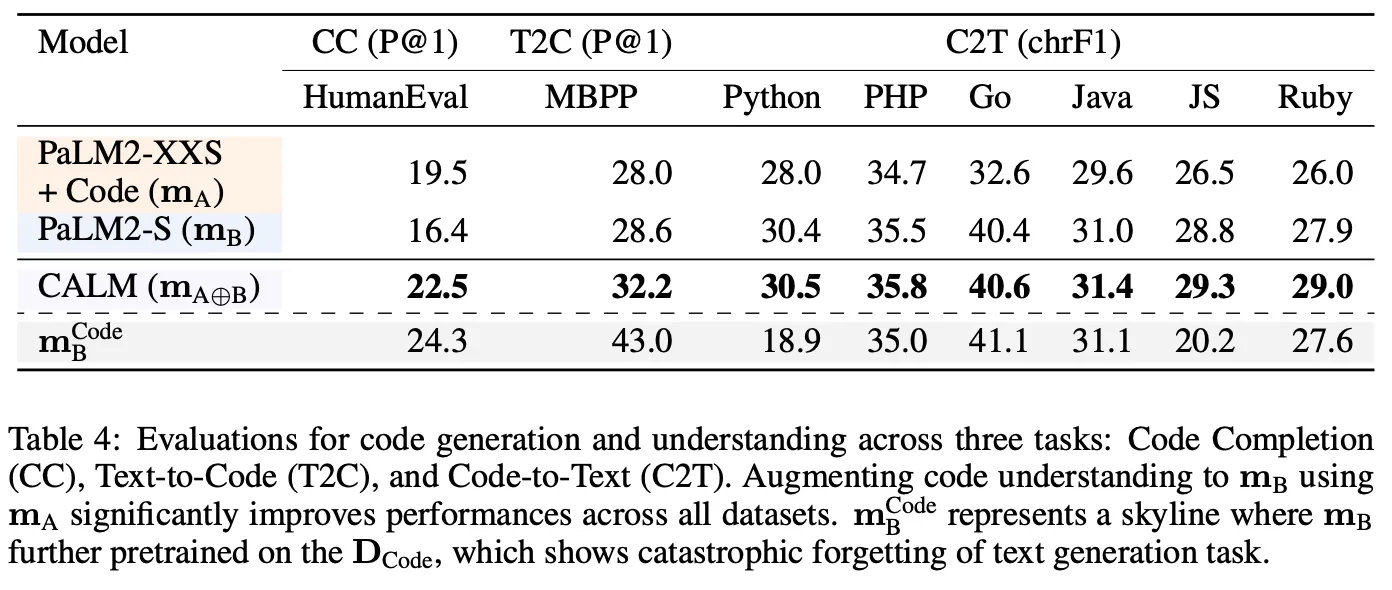
◦
Code-Completion, Text-to-Code, Code-to-Text
◦
: code-specific data 로 추가 튜닝
◦
: 일반 언어 모델
◦
Reference 모델 및 를 code로 튜닝한 모델 대비 더 좋은 성능을 보임
•
Ablation
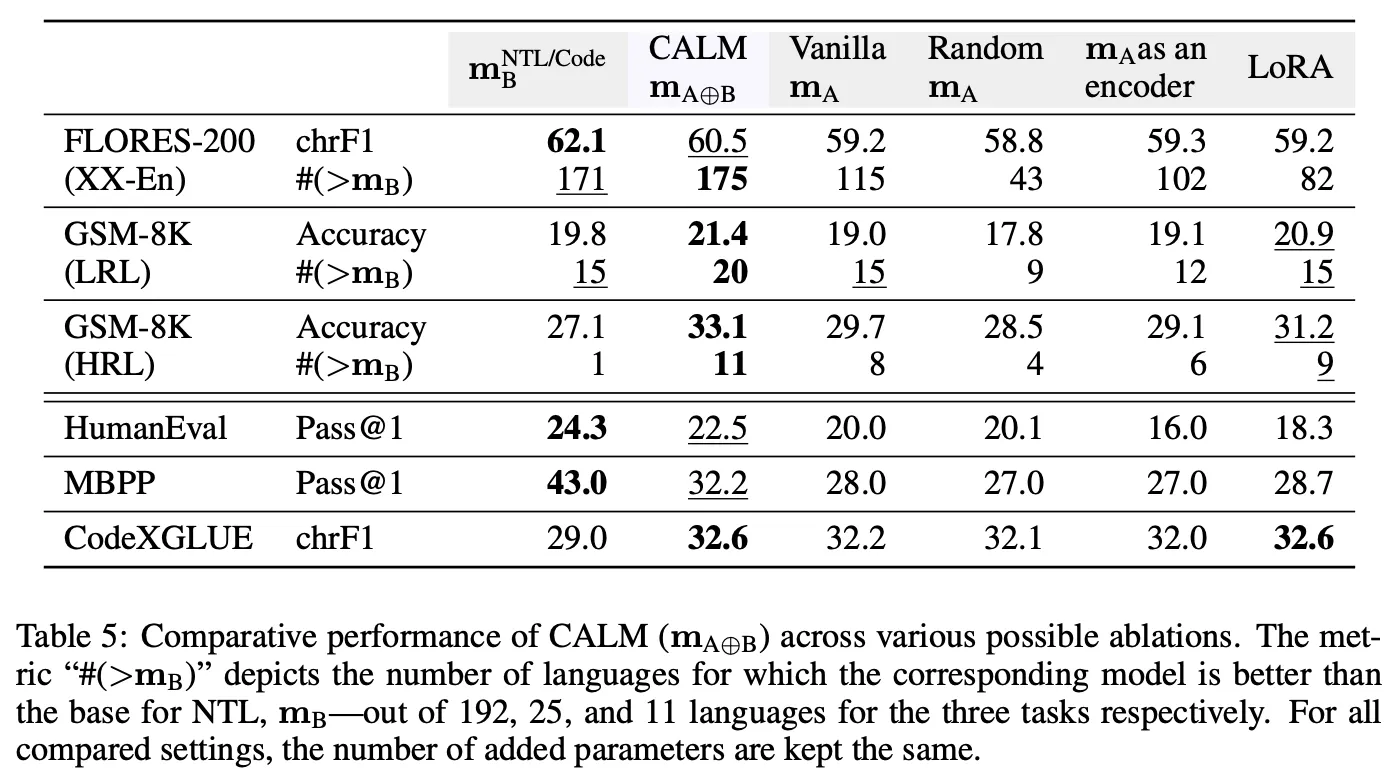
◦
Augmenting model의 능력을 활용하여 task 성능 향상에 기여하고 있음
◦
동일 데이터로 에 LoRA를 적용했을 때 대비 더 효과가 좋음
◦
물론 LoRA와는 달리 domain-specific augmenting model 가 추가로 필요하기 때문에 완전히 fair한 비교라 할 수는 없음
논의
•
두 논문에서 제안하는 방법론은 세부적인 목적은 다르나 하나 혹은 그 이상의 pretrained LM을 기반으로 일부 파라미터만 튜닝하여 MoE 구조의 모델을 개발한다는 측면에서 넓게 보면 pretrained LM을 활용하여 MoE를 효율적으로 만드는 방법이라 볼 수 있음
•
구체적으로 살펴보면 다음의 차이가 존재
◦
MoV, MoLORA : 하나의 pretrained LM을 사용. SwitchFormer 와 같이 input, output layer 및 중간 attention layer 등은 모두 하나이며 다수의 expert layer를 vector 혹은 low-rank matrix 등의 parameter efficient한 방식으로 구현
◦
CALM : 서로 다른 두 개 이상의 pretrained LM을 사용. 모델의 대부분 구성 요소가 독립적이며 중간에 간단한 composition layer로 연결하는 방식으로 각각의 능력도 살리면서 조합 능력을 발현시킴. MoE 구조와 여러 모델을 ensemble 하는 방법의 중간 형태의 느낌
•
앞으로의 모델 구조는 여러 가지 현실적인 이유로 인하여 MoE 구조 형태가 점점 더 주목을 받을 것으로 판단.
◦
LLM의 scaling law는 분명 유효한 현상이지만 GPU 등 하드웨어의 물리적인 제약으로 인하여 당분간 현재 수준 이상으로 dramatic하게 커지긴 쉽지 않은 상황
◦
실제로 GPT-4 발표 당시 100~200B 수준의 모델 10~20개가 모여 있는 MoE 형태라는 소문이 존재하였음
◦
Mistral AI에서 발표한 Mixtral 모델은 7B 모델 8개를 묶은 MoE 구조이며 크기 대비 경쟁력 높은 성능을 보유
•
이미 존재하는 다양한 pretrained 모델을 활용하여 입맛에 맞는 MoE구조를 효과적으로 만들 수 있는 유용한 방법론들이라 판단하며 이 분야의 연구가 앞으로 더 활발하게 진행되지 않을까 예상
•
단, 실전 문제 상황에서도 논문에서 주장하는 효과가 있을지에 대한 검증은 필요