

RAG와 파인튜닝
초거대언어모델은 일반적인 과제를 잘 처리하는 장점이 있다. 우리가 ChatGPT에 열광하는 이유 역시 일반적인 지식 질문이나 추론에 대해 필요한 답변을 훌륭하게 생성하기 때문이라고 생각한다. 하지만 실생활에서 대규모 언어모델이 유의미하게 사용되려면 개인 또는 조직 단위로 특수한 데이터를 학습해야 할 필요가 있다. 이번 아티클에서는 RAG와 파인튜닝의 두 가지 방법론을 다룬다. 두 접근 방식은 모두 초거대 언어 모델을 기반으로 개인화하는 방법이지만, 비용과 성능 대비 차이가 있다.
먼저, 언어 모델을 커스텀하게 사용하는 방법으로 파인튜닝이 있다. 사전 학습된 초거대 언어 모델(Large language model, LLM)에 작은 데이터 세트에 대해 추가로 학습시켜 특정한 작업에 맞게 미세하게 조정하고 성능을 개선하는 방법이다. 전통적으로 파인튜닝은 거대한 단위의 웹 데이터를 사전 학습하고 작은 분야의 과제에 따라 튜닝을 진행하는 방법이었다. 그런데 모델의 파라미터 수가 점점 커지면서 기업이나 연구자가 모델 전체를 파인튜닝하는 것이 힘들어졌고 파인튜닝한 모델의 저장과 사용 비용 또한 매우 커졌다. 이 외에도 새로운 정보를 학습할 때 이전에 학습한 정보를 갑자기 급격하게 잊어버리는 현상, 즉, 파괴적 망각(Catastrophic forgetting)으로 불리는 현상 역시 해결에 어려움이 있었다.
ChatGPT등의 LLM 모델이 산업적으로 대두되기 시작한지 이제 막 1년이 지나면서, 각 기업들이 찾은 비용 효율적인 대안이 RAG라고 할 수 있다. RAG 기법은 LLM의 강력한 텍스트 생성력을 기반으로, 사용자 쿼리에 맞는 필요한 문서 스니펫을 적절하게 가져와서 모델에 프롬프트를 통해 제공하여 응답하는 방법이다. LlamaIndex와 Langchain과 같은 개발자 도구나 unstructured.io와 같은 전처리 SDK, 그리고 Milvus와 같은 여러 상업용의 벡터 서치 DB가 최근 1년 동안 유치한 투자 금액과 밸류에이션을 보면 산업계에서의 RAG 기법에 대한 관심도는 쉽게 유추할 수 있을 것이다.
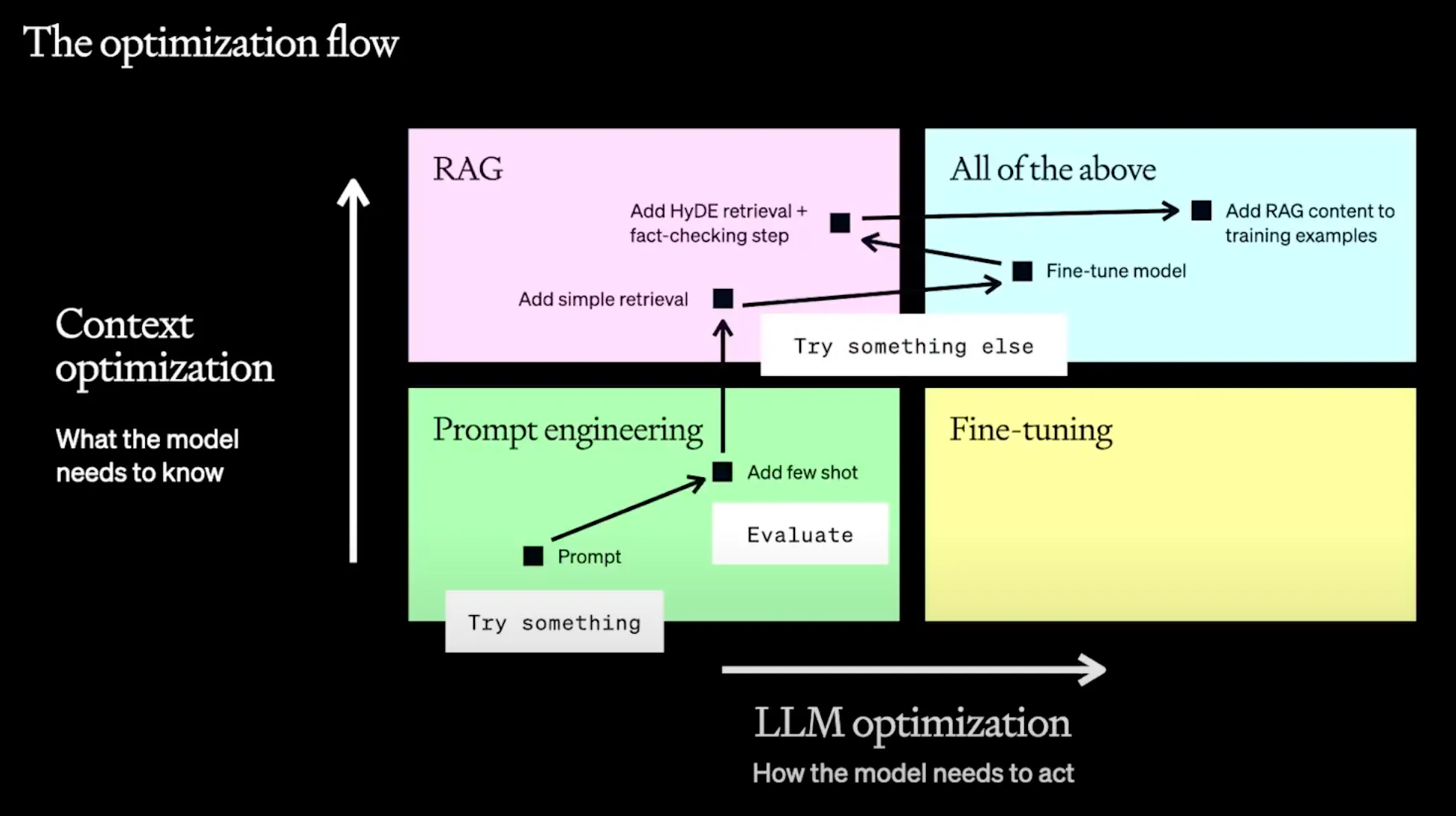
사진 출처: OpenAI - A Survey of Techniques for Maximizing LLM Performance https://youtu.be/ahnGLM-RC1Y
하지만 모델의 목적 자체를 더욱 자유롭게 바꾸어낼 수 있다는 점에서 파인튜닝이 가지는 매력도 무시하기 어렵다. 모델이 응답하는 스타일이나 톤앤매너, 포맷과 같이 어떤 질적인 면모를 바꾸거나, 원하는 형태의 아웃풋이 잘 나올 것이라는 어떤 신빙성을 더욱 보장하거나, Text를 SQL로 바꾼다는 등의 프롬프트만으로는 설명하기 어려운 특정한 작업에 특화되어야 할 때에는 파인튜닝이 유리한 경우도 있겠다.
OpenAI는 지난 DevDay에서 파인튜닝과 RAG가 필요한 경우를 2개의 축으로 정리해서 소개했다. 모델의 지식적인 측면을 수정하고자 하는 경우에는 RAG를, 모델이 어떻게 답변하고 추론하는 지를 수정하고자 하는 경우에는 파인튜닝이 적합하다고 소개했다.
과거에는 쉽지만은 않았던 베이스 모델의 파인튜닝이 두 가지 측면에서 점점 일반 개발자들에게 접근 가능한 형태로 다가오고 있다고 생각한다. 하나는 상용화된 모델의 클라우드 서비스로서의 파인튜닝 API를 제공하는 것과, 또 하나는 파인튜닝 과정 전반에서의 난이도가 낮아짐으로서 약간의 지식만 갖춘다면 공개 모델을 이용하여 나만의 데이터셋을 가지고 Private한 환경에서 파인튜닝을 진행할 수 있게 된 것이다. 이번 아티클 시리즈를 통해서는 이와 같이 나만의 데이터셋으로 파인튜닝하는 과정을 실습할 것이다.
1.
오픈소스 기반의 거대 언어 모델을 바탕으로, 나만의 Private한 데이터셋을 통해 모델을 파인튜닝한다.
2.
해당 모델의 인퍼런스를 WebGPU를 활용하여 로컬에서 수행함으로써 민감한 나의 정보를 외부로 노출시키지 않고도 로컬에서 나만의 LLM을 구동할 수 있다.
이번 아티클을 통해서는 Meta AI에서 공개한 LLaMA 7B Chat 모델을 바탕으로 QLoRA 기법을 활용하여 나만의 데이터셋을 파인튜닝하여 허깅페이스 (Hugging Face) 에 배포해보도록 하겠다.
경제적인 파인튜닝을 위한 PEFT와 QLoRA 기법
개인이나 회사의 비공개 데이터셋을 사용하는데 민감한 데이터를 외부로 반출하지 않고도 나만의 모델을 지속적으로 튜닝하고 업데이트할 수 있다면, AI를 “최고로 길들이고 키울 수 있는” 방법이 될 것이다. 파인튜닝을 사용하는 방법 역시 다소 쉬워졌는데 먼저, GPU에 접근할 수 있는 하드웨어적인 보급도가 올라가면서 동시다발적으로 웹에서 GPU를 직접 접근할 수 있게 되어 일반 개발자들이 CUDA 프로그래밍에 대한 높은 이해가 없이도 웹에서 인퍼런스를 수행할 수 있게 되었다. 또한 파인튜닝을 진행할 때 모델 전체의 파라미터를 수정하지 않고도 일부 파라미터만 업데이트를 하더라도 전체 파라미터를 수정했을 때에 준하는 수준의 성능을 기대할 수 있을 정도로 간소화된 기법이 대중화되고 있다.
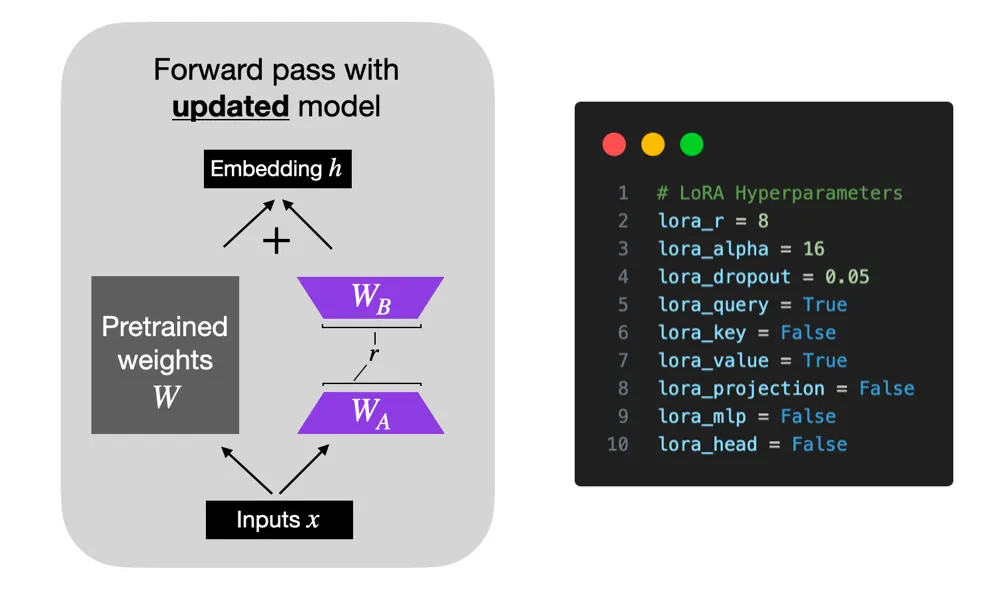
최근 들어 등장하고 있는 여러 파인튜닝 기법으로 체크포인트 기법이나 PEFT (Parameter Efficient Fine-tuning) 등이 대두되고 있다. PEFT는 모델 전체의 파라미터를 튜닝할 필요가 없이, 일부 파라미터를 튜닝하더라도 모델의 성능을 적은 자원으로 튜닝할 수 있도록 하는 방법을 의미한다. PEFT에는 LoRA (Low Rank Adapation) 기법이 주로 사용되고 있고, 최근에는 QLoRA 기법이 제시되고 있다. LoRA는 고정 가중치를 가지고 있는 Pretrained된 모델을 기반으로 추가 학습이 가능한 Rank Decomposition 행렬을 트랜스포머 아키텍처의 각 레이어에 붙인 것이다. 다시 말해 훈련 가능한 레이어를 추가해서 별도의 훈련을 통해 학습시킨 것이다.
LoRA는 Low Data Regime처럼 데이터가 적은 상황에서도 파인튜닝하기 용이하다는 장점이 있으며 도메인 외부의 데이터를 일반화할 때 좋은 성능을 보이는 것으로 알려져 있다. 우리가 LoRA를 통해 학습한 가중치는 작은 양이지만 사전 학습된 LLM 모델 레이어의 맨 윗 부분을 차지하게 되며, 다른 파라미터에 얼마나 영향을 줄 지 hyper parameter를 적절히 설정함으로서 모델의 성능을 결정할 수 있다.
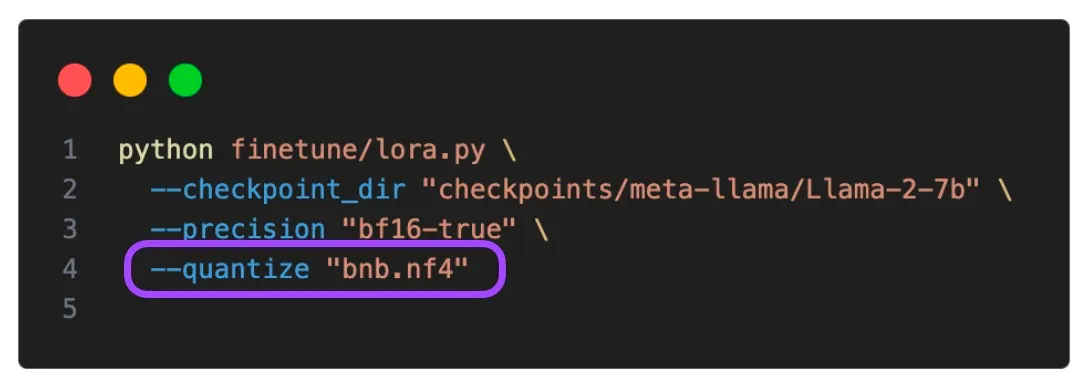
특히 최근에는 QLoRA라는 4비트 양자화 기법이 주목을 받으면서 LLM 모델을 적은 비트의 포맷으로 설정하여 큰 메모리의 GPU 없이도 파인튜닝이 가능하게 되었다. 거대 언어모델의 파라미터 사이즈가 커져가는 와중에서도 적절한 양자화와 distillation을 통해 모델에 저장되고 메모리에 로드되는 부담을 줄인다. QLoRA는 LoRA의 가중치를 NormalFloat 이라는 FP4를 변형한 자료형을 사용하여 4비트 양자화한다.
해당 자료형은 비선형적인 간격과 비대칭 분포를 바탕으로 -1부터 1까지의 범위를 나타내서 저장한다. 양자화를 통해 사이즈를 줄이면서도 트레이닝이나 역전파 과정에서는 역양자화 과정을 수행하여 저수준의 비트를 32비트로 근사하여 일정한 성능을 유지할 수 있다.
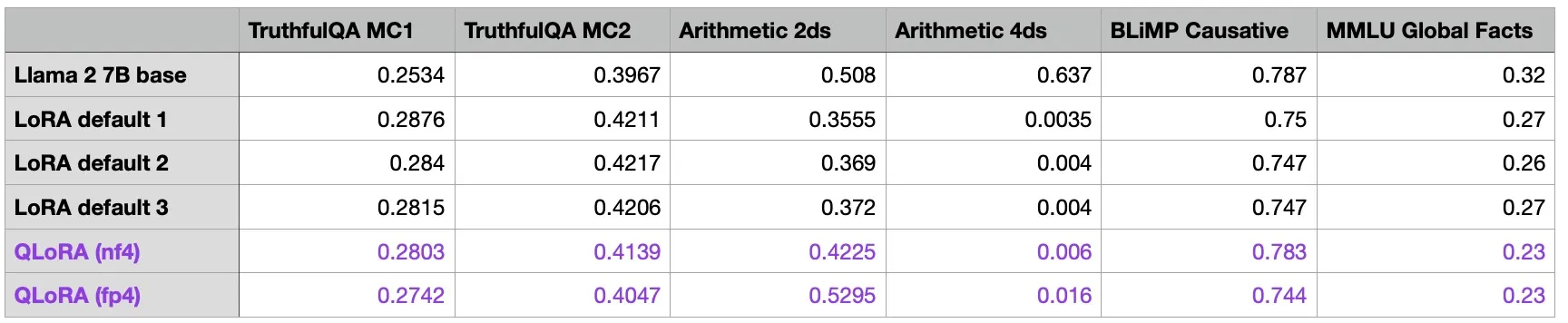
위의 테이블을 보면 QLoRA 기법을 활용하였을 때 일반적인 LoRA의 파인튜닝 기법보다 모델에 미치는 영향이 적은 것을 확인할 수 있다. 양자화가 인메모리 로드 부담을 절감시키는 데 상당한 효과가 있음을 고려한다면 가성비 대비 효과적이라고 할 수 있다.
따라서 이 아티클에서는 LLaMA2 7B의 베이스 모델을 바탕으로 QLoRA 기법을 활용한 파인튜닝을 간단히 실습한다. 실습에 사용된 Jupyter Notebook 파일은 이 링크에서 다운로드 받을 수 있다.
Step 1. 필요한 라이브러리를 설치하고 Import 한다.
!pip install -q accelerate==0.21.0 scipy tensorboardX peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7 tensorboardX
JavaScript
복사
import os # os 모듈 운영체제와 상호 작용할 수 있는 기능을 제공
import torch # PyTorch 라이브러리로, 주로 딥러닝과 머신러닝 모델을 구축, 학습, 테스트하는 데 사용
from datasets import load_dataset # 데이터셋을 쉽게 불러오고 처리할 수 있는 기능을 제공
from transformers import (
AutoModelForCausalLM, # 인과적 언어 추론(예: GPT)을 위한 모델을 자동으로 불러오는 클래스
AutoTokenizer, # 입력 문장을 토큰 단위로 자동으로 잘라주는 역할
BitsAndBytesConfig, # 모델 구성
HfArgumentParser, # 파라미터 파싱
TrainingArguments, # 훈련 설정
pipeline, # 파이프라인 설정
logging, #로깅을 위한 클래스
)
# 모델 튜닝을 위한 라이브러리
from peft import LoraConfig, PeftModel
from trl import SFTTrainer
JavaScript
복사
•
우리가 가장 주목해야 할 라이브러리는 바로 BitsAndBytes이다. 앞서 살펴보았던 벡터의 INT8 최대 절대값 양자화 기법을 사용할 수 있도록 도와주는 Meta AI의 라이브러리이다.
Step 2. Llama 2 모델과 데이터 가져오기 
# Hugging Face 허브에서 훈련하고자 하는 모델을 가져와서 이름 지정
model_name = "NousResearch/Llama-2-7b-chat-hf"
# instruction 데이터 세트 설정
dataset_name = "mlabonne/guanaco-llama2-1k"
# fine-tuning(미세 조정)을 거친 후의 모델에 부여될 새로운 이름을 지정하는 변수
new_model = "sionic-llama-2-7b-miniguanaco"
JavaScript
복사
우리는 이번 실습에서 Pretrained된 베이스 모델로서 Llama 2의 7B Chat 모델을 선택할 것이다. Meta AI의 허깅페이스 레포지토리에 LLaMA 2 공식 모델이 있지만, 해당 모델은 Gated된 버전이므로 NousResearch에서 추가 공개한 LLaMA 2 7B Chat HF 모델을 사용할 것이다.
한편, Instruction 파인튜닝을 위한 데이터셋으로는 OpenAssistant Converation Dataset (OASST 1)을 LLaMA 2의 프롬프트 포맷에 맞추어 1000개로 줄인 버전을 사용하였다. 마지막으로 새롭게 만들어질 모델의 이름을 자유롭게 지정하면 된다.
Step 3. LoRA (Low-Rank Adaptation) 파라미터 설정
# LoRA에서 사용하는 low-rank matrices 어텐션 차원을 정의. 여기서는 64로 설정
# 값이 크면 클수록 더 많은 수정이 이루어지며, 모델이 더 복잡해질 수 있음
lora_r = 64
# LoRA 적용 시 가중치에 곱해지는 스케일링 요소. 여기서는 16으로 설정
# LoRA가 적용될 때 원래 모델의 가중치에 얼마나 영향을 미칠지 결정. 높은 값은 가중치 조정의 강도를 증가시킴
lora_alpha = 16
# Dropout probability for LoRA layers # LoRA 층에 적용되는 드롭아웃 확률. 여기서는 0.1 (10%)로 설정
lora_dropout = 0.1 # 일부 네트워크 연결을 무작위로 비활성화하여 모델의 강건함에 기여
JavaScript
복사
•
가중치를 조정하여 더 좋은 성능을 내어 추가적인 작업에 더 잘 맞도록 하는 기법이다. 이는 모델의 전체 구조를 변경하지 않으면서도 효율적으로 모델을 조정할 수 있다는 장점이 있다.
•
위에서 peft 라이브러리에서 Import한 LoraConfig 에 할당할 파라미터에 대해 하나씩 살펴보자.
•
먼저 lora_r 은 정보의 손실과 효율성 사이에 균형을 맞추기 위해 여러 시도를 통해 결정할 수 있는 파라미터이다. 모델의 가중치 행렬을 두 개의 low-rank 행렬의 곱으로 근사하기 때문에, lora_r 의 값이 커질 수록 더 많은 정보를 유지하면서 모델이 훈련 데이터에 과도하게 적응하게 하여 오버피팅의 가능성을 높인다. 한 편으로 lora_r 의 값이 낮을 수록 정보가 손실되며 모델이 데이터의 복잡한 특성을 포착할 가능성을 낮춘다.
•
또한 lora_alpha 는 LoRA 기업을 적용할 때 가중치에 곱해지는 scaling factor로서 원래의 모델에 대비하여 LoRA 가중치에 얼마나 영향을 미칠 지를 결정한다.
•
마지막으로 lora_dropout 파라미터는 전통적인 머신러닝에서 과적합을 방지하기 위하여 훈련 과정에서 네트워크의 일부 가중치를 0으로 설정하는 방법을 적용하기 위하여 쓰인다. 가중치 행렬을 조정할 때 low-rank matrices로 가중치 행렬을 근사하는 데 이 때 LoRA 변화량을 모델에 적용하기 전에 일부 원소를 임의로 0으로 만드는 방법이다.
Step 4. bitsandbytes 파라미터 설정
앞서 언급했듯이 bitsandbytes 는 QLoRA 기법을 적용하기 위하여 사용되는 8비트 양자화 라이브러리이다. 해당 라이브러리를 통해 양자화 관련 설정값을 지정할 수 있다. 예를 들어 4비트 베이스 모델을 로딩한다던지, 4비트 모델의 연산 과정에서 사용할 데이터 타입을 지정한다던지, 양자화의 유형을 명시한다던지의 세부적인 설정을 진행할 수 있다.
# 4-bit precision 기반의 모델 로드
use_4bit = True
# 4비트 기반 모델에 대한 dtype 계산
bnb_4bit_compute_dtype = "float16"
# 양자화 유형(fp4 또는 nf4)
bnb_4bit_quant_type = "nf4"
# 4비트 기 모델에 대해 중첩 양자화 활성화(이중 양자화)
use_nested_quant = False
JavaScript
복사
Step 5. TrainingArguments 파라미터 설정
•
Trainer는 허깅페이스에서 제공하는 라이브러리로 모델의 학습부터 평가까지 한 번에 해결할 수 있는 API를 제공한다. 아래는 Train에 필요한 파라미터를 정의한 것으로, Optimizer의 종류와 Learing Rate, Epoch 수, Scheduler와 Half Precision의 사용 여부 등에 대해 지정할 수 있다.
•
num_train_epochs 파라미터를 통해 모델이 전체 데이터셋을 몇 번 반복하여 학습할 지를 지정할 수 있고, per_device_train_batch_size 를 통해 각 GPU에서 한 번에 처리할 데이터의 양을 나타낼 수도 있다. 여기에서는 모두 1로 지정하여 한 번에 하나의 데이터만 처리하도록 하였다. gradient_accumulation_steps 파라미터를 통해 기울기를 갱신하기 전에 몇 번의 기울기 업데이트를 축적할 지를 결정하는데, 여기에서는 1로 설정되어 있어 매 스텝마다 기울기를 갱신한다. 마지막으로 gradient_checkpointing 파라미터를 통해 메모리 사용을 최적화할 수 있다. 대규모 모델을 사용할 때 특히 유용한 파라미터로서 필요할 때만 특정 계층의 기울기를 저장하고 나머지는 버려 메모리의 부담을 줄인다.
•
max_grad_norm 파라미터를 통해 모델이 데이터로부터 학습하는 속도를 조절할 것이다. 기울기가 과도하게 커져서 발생할 수 있는 gradient exploding 문제 등을 방지할 수 있도록 기울기의 최대 크기를 설정한다. 그리고 이번 실습에서 Adam 옵티마이저를 사용할 것인데 이 때 learning_rate 를 보수적으로 잡아 모델이 데이터로부터 학습하는 속도를 적절히 늦추도록 할 것이다. 마지막으로 weight_decay 값을 적절히 주어 모델의 가중치가 너무 큰 값을 가지지 않도록 함으로서 오버피팅 현상을 해소할 수 있다. 스케줄러는 Cosine Decay를 사용하여 안정적으로 끊김없이 Loss가 감소하도록 할 것이다.
#모델이 예측한 결과와 체크포인트가 저장될 출력 디렉터리
output_dir = "./results"
# 훈련 에포크 수
num_train_epochs = 1
# fp16/bf16 학습 활성화(A100으로 bf16을 True로 설정)
fp16 = False
bf16 = False
# 훈련용 배치 크기
per_device_train_batch_size = 1
# 평가용 배치 크기
per_device_eval_batch_size = 1
# 그래디언트를 누적할 업데이트 스텝 횟수
gradient_accumulation_steps = 1
# 그래디언트 체크포인트 활성화
gradient_checkpointing = True
# 그래디언트 클리핑을 위한 최대 그래디언트 노름을 설정.
# 그래디언트 클리핑은 그래디언트의 크기를 제한하여 훈련 중 안정성을 높임.
# Maximum gradient normal (그래디언트 클리핑) 0.3으로 설정
max_grad_norm = 0.3
# 초기 학습률 AdamW 옵티마이저
learning_rate = 2e-6
# bias/LayerNorm 가중치를 제외하고 모든 레이어에 적용할 Weight decay 값
weight_decay = 0.001
# 옵티마이저 설정
optim = "paged_adamw_32bit"
# 학습률 스케줄러의 유형 설정, 여기서는 코사인 스케줄러 사용
lr_scheduler_type = "cosine"
# 훈련 스텝 수(num_train_epochs 재정의)
max_steps = -1
# (0부터 learning rate까지) 학습 초기에 학습률을 점진적으로 증가시키 linear warmup 스텝의 Ratio
warmup_ratio = 0.03
# 시퀀스를 동일한 길이의 배치로 그룹화, 메모리 절약 및 훈련 속도를 높임
group_by_length = True
# X 업데이트 단계마다 체크포인트 저장
save_steps = 0
# 매 X 업데이트 스텝 로그
logging_steps = 25
JavaScript
복사
Step 6. SFT 파라미터 값 설정
•
이전에 준비했던 데이터셋을 바탕으로 Supervised Fine-Tuning (SFT) 를 진행해보자. 우리는 SFTTrainer로 Import한 라이브러리를 사용할 것이다.
•
SFT는 라벨러들이 제작한 프롬프트 데이터셋을 이용하여 베이스 모델을 지도학습 바탕으로 파인 튜닝하는 기법으로, 주어진 일정 토큰에 대한 다음 토큰을 예측하는 형식으로 진행된다. 우리의 데이터셋으로 치면 주어진 질문에 대한 답변을 유추하는 형태가 될 것이다.
•
max_seq_length 는 입력 시퀀스에 대한 최대 사이즈를 의미한다. 예를 들어 문장 2개가 합쳐질 때 maximum sequence가 어느 정도일 지를 결정한다.
•
packing 이란 훈련 과정에서의 효율성을 높이기 위해 복수 개의 예시 문장을 하나의 Input 시퀀스로 넣어주는 기법을 의미한다.
•
device_map 을 통해서 몇 번 GPU를 로드할 지 지정할 수 있다. 본인은 학습 환경이 GPU 1대였기 때문에 0번 GPU를 로드하도록 설정하였다.
# 최대 시퀀스 길이 설정
max_seq_length = None
# 동일한 입력 시퀀스에 여러 개의 짧은 예제를 넣어 효율성을 높일 수 있음
packing = False
# GPU 0 전체 모델 로드
device_map = {"": 0}
JavaScript
복사
Step 7. 데이터 세트 로딩과 데이터 타입 결정
•
이제 위에서 알아보았던 파라미터를 주입해보도록 하자. 먼저 SFT를 진행하기 위한 데이터셋을 로드한다. 그리고 BitsAndBytesConfig 인스턴스를 생성할 때 앞서 살펴보았던 데이터 타입을 주입하도록 하자.
dataset = load_dataset(dataset_name, split="train")
[Output]
Downloading readme: 100%|██████████| 1.02k/1.02k [00:00<00:00, 8.09MB/s]
Downloading data files: 0%| | 0/1 [00:00<?, ?it/s]
Downloading data: 0%| | 0.00/967k [00:00<?, ?B/s]
Downloading data: 100%|██████████| 967k/967k [00:00<00:00, 2.20MB/s]
Downloading data files: 100%|██████████| 1/1 [00:00<00:00, 2.24it/s]
Extracting data files: 100%|██████████| 1/1 [00:00<00:00, 1054.38it/s]
Generating train split: 100%|██████████| 1000/1000 [00:00<00:00, 89155.15 examples/s]
Plain Text
복사
compute_dtype = getattr(torch, bnb_4bit_compute_dtype)
# 모델 계산에 사용될 데이터 타입 결정
bnb_config = BitsAndBytesConfig(
load_in_4bit=use_4bit, # 모델을 4비트로 로드할지 여부를 결정
bnb_4bit_quant_type=bnb_4bit_quant_type, # 양자화 유형을 설정
bnb_4bit_compute_dtype=compute_dtype, # 계산에 사용될 데이터 타입을 설정
bnb_4bit_use_double_quant=use_nested_quant, # 중첩 양자화를 사용할지 여부를 결정
)
JavaScript
복사
Step 8. GPU 호환성 확인
•
현재 GPU가 bfloat16 형태를 지원하는 지 확인한다. 만약 GPU의 CUDA 버전이 8 이상이라면 해당 데이터 타입을 지원하는 것이다.
•
bfloat16이란 모델의 트레이닝 속도를 높일 수 있는 데이터 타입으로서, 16비트 부동 소수점 형식을 나타낸다. 물론 32비트 부동 소수점 형식보다는 정확도가 비교적 떨어지지만 메모리 요구 사항이 적다는 점에서 모델 학습에 유용하다고 할 수 있다.
# 만약 GPU가 최소한 버전 8 이상이라면 (major >= 8) bfloat16을 지원한다고 메시지를 출력.
# bfloat16은 훈련 속도를 높일 수 있는 데이터 타입.
if compute_dtype == torch.float16 and use_4bit:
major, _ = torch.cuda.get_device_capability()
if major >= 8:
print("=" * 80)
print("Your GPU supports bfloat16: accelerate training with bf16=True")
print("=" * 80)
JavaScript
복사
Step 9. 베이스 모델 로딩
•
이제 사전 훈련된 베이스 모델과 토크나이저를 로드한 다음 LoRA 연산을 적용해보자.
# Load base model
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map=device_map
)
model.config.use_cache = False
model.config.pretraining_tp = 1
# Load LLaMA tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 동일한 batch 내에서 입력의 크기를 동일하기 위해서 사용하는 Padding Token을 End of Sequence라고 하는 Special Token으로 사용한다.
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right" # Fix weird overflow issue with fp16 training. Padding을 오른쪽 위치에 추가한다.
# Load LoRA configuration
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM", # 파인튜닝할 태스크를 Optional로 지정할 수 있는데, 여기서는 CASUAL_LM을 지정하였다.
)
# Set training parameters
training_arguments = TrainingArguments(
output_dir=output_dir,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
weight_decay=weight_decay,
fp16=fp16,
bf16=bf16,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=group_by_length,
lr_scheduler_type=lr_scheduler_type,
report_to="tensorboard"
)
# Set supervised fine-tuning parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
)
JavaScript
복사
[Output]
pytorch_model-00002-of-00002.bin: 0%| | 0.00/3.50G [00:00<?, ?B/s]
Upload 2 LFS files: 0%| | 0/2 [00:00<?, ?it/s]
pytorch_model-00002-of-00002.bin: 1%| | 30.5M/3.50G [00:04<06:41, 8.64MB/s]
.
.
.
pytorch_model-00001-of-00002.bin: 100%|██████████| 9.98G/9.98G [06:55<00:00, 24.0MB/s]
Upload 2 LFS files: 100%|██████████| 2/2 [06:58<00:00, 209.07s/it]
CommitInfo(commit_url='https://huggingface.co/sigridjineth/sionic-llama-2-7b-miniguanaco/commit/09f9f8db31ad72f292add66f6a35b92fc64bd031', commit_message='Upload tokenizer', commit_description='', oid='09f9f8db31ad72f292add66f6a35b92fc64bd031', pr_url=None, pr_revision=None, pr_num=None)
Plain Text
복사
Step 10. 모델 훈련과 훈련된 모델 저장
이제 모델을 저장하면 bade_model 파라미터를 제외한 Adapter 부분만 저장이 될 것이다. 아래와 같이 adapter_config.json 파일이 보이면 성공이다.
•
앞서 언급했듯이 trainer 객체는 이전에 정의된 여러 설정(모델, 데이터 세트, 훈련 파라미터 등)을 포함한다. train 메소드를 통해 데이터 세트를 반복적으로 처리하면서 모델의 가중치를 업데이트하는 모습을 볼 수 있다.
trainer.train()
# 훈련이 완료된 모델을 'new_model'에 저장
trainer.model.save_pretrained(new_model)
JavaScript
복사
[Output]
You're using a LlamaTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
/home/elicer/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
[1000/1000 37:46, Epoch 1/1]
warnings.warn(
Step Training Loss
25 1.691000
50 2.435900
75 1.529900
100 2.866300
125 1.665800
150 2.570100
175 1.635100
200 2.771900
225 1.516600
250 2.527600
275 1.659200
300 2.742900
325 1.806100
350 2.258200
375 1.736300
400 2.426000
425 1.647400
450 2.333400
475 1.522800
500 2.074800
525 1.554100
550 2.018100
575 1.577300
600 2.528600
625 1.618900
650 2.385800
675 1.494100
700 2.507100
725 1.608700
750 2.616200
775 1.460400
800 2.407700
825 1.504700
850 2.582100
875 1.583400
900 2.475300
925 1.485700
950 2.668500
975 1.676400
1000 2.351000
Plain Text
복사
Step 11. 모델 이름 출력, 기본 모델 재로딩 후 LoRA 가중치와의 통합
•
학습된 LoRA adapter 가중치를 원본 모델에 병합하는 merge_and_unload 메서드
를 활용해 모델과 LoRA를 따로 불러와 매핑하지 않고 하나의 모델로 활용한다.
•
LoRA 어댑터를 통해 얻은 파인튜닝의 결과물 크기는 몇 MB밖에 되지 않는다. 이러한 어댑터를 사전 훈련된 모델에 merge_and_unload 한 줄로 병합하고 해당 모델을 배포한다. 이러한 어댑터 패턴의 장점은 특정한 태스크에 따라 파인튜닝 된 어댑터를 유연하게 설정할 수 있다는 것이다.
# base_model과 new_model에 저장된 LoRA 가중치를 통합하여 새로운 모델을 생성
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16
)
model = PeftModel.from_pretrained(base_model, new_model) # LoRA 가중치를 가져와 기본 모델에 통합
JavaScript
복사
[Output]
NousResearch/Llama-2-7b-chat-hf
Loading checkpoint shards: 100%|██████████| 2/2 [00:00<00:00, 4.03it/s]
Plain Text
복사
model = model.merge_and_unload()
JavaScript
복사
# 사전 훈련된 토크나이저를 다시 로드
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 토크나이저의 패딩 토큰을 종료 토큰(end-of-sentence token)과 동일하게 설정
tokenizer.pad_token = tokenizer.eos_token
# 패딩을 시퀀스의 오른쪽에 적용
tokenizer.padding_side = "right"
JavaScript
복사
Step 12. Hugging Face Hub 로그인
•
우리가 최종적으로 병합한 모델을 업로드하기 위해 마지막으로 허깅페이스에 로그인하자.
from huggingface_hub import interpreter_login
interpreter_login()
JavaScript
복사
[Output]
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
To login, `huggingface_hub` requires a token generated fromhttps://huggingface.co/settings/tokens .
Token: ········
Add token as git credential? (Y/n) y
Token is valid (permission: write).
Cannot authenticate through git-credential as no helper is defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub.
Run the following command in your terminal in case you want to set the 'store' credential helper as default.
git config --global credential.helper store
Readhttps://git-scm.com/book/en/v2/Git-Tools-Credential-Storage for more details.
Token has not been saved to git credential helper.
Your token has been saved to /home/elicer/.cache/huggingface/token
Login successful
Plain Text
복사
Step 13. 모델과 토크나이저를 Hugging Face Hub에 업로드
•
이제 모델과 토크나이저를 Hugging Face Hub에 업로드한다. 해당 과정이 중요한 이유는 우리가 GPU를 통해 파인튜닝한 모델을 다운로드받아 Local 환경의 WebGPU를 지원하는 브라우저에서 구동할 것이기 때문이다.
•
이후 필요할 때 언제든지 접근하여 다운로드 할 수 있고 공동 연구자들이 협력할 수 있는데 도움을 줄 것이다.
•
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)
JavaScript
복사
[Output] pytorch_model-00002-of-00002.bin: 0%| | 0.00/3.50G [00:00<?, ?B/s]
Upload 2 LFS files: 0%| | 0/2 [00:00<?, ?it/s]
pytorch_model-00002-of-00002.bin: 1%| | 30.5M/3.50G [00:04<06:41, 8.64MB/s]
pytorch_model-00002-of-00002.bin: 1%|▏ | 46.3M/3.50G [00:05<03:24, 16.9MB/s]B/s]
pytorch_model-00002-of-00002.bin: 1%|▏ | 51.4M/3.50G [00:06<03:56, 14.6MB/s]]
.
.
.
pytorch_model-00001-of-00002.bin: 100%|██████████| 9.98G/9.98G [06:55<00:00, 24.0MB/s]
Upload 2 LFS files: 100%|██████████| 2/2 [06:58<00:00, 209.07s/it]
CommitInfo(commit_url='https://huggingface.co/sigridjineth/sionic-llama-2-7b-miniguanaco/commit/09f9f8db31ad72f292add66f6a35b92fc64bd031', commit_message='Upload tokenizer', commit_description='', oid='09f9f8db31ad72f292add66f6a35b92fc64bd031', pr_url=None, pr_revision=None, pr_num=None)
JavaScript
복사
이번 시간에는 LLaMA2를 바탕으로 나만의 데이터셋을 활용하여 사전 훈련된 모델을 파인튜닝 하는 과정을 간단하게 실습해보았다. 다음 아티클에서는 우리가 허깅페이스에 업로드한 모델을 바탕으로 외부 네트워크가 전혀 연결되지 않은 Local 환경에서도 WebGPU를 활용하여 Private하게 LLM을 구동하도록 프론트엔드를 구성하는 방법에 대하여 알아보도록 하겠다.
참고 자료 링크
•
LLaMA 공식 허깅페이스: meta-llama/Llama-2-7b · Hugging Face
•
테스트 링크 : LIama:abs.perplexity.ai
•
관련 뉴스와 블로그
•