

도입
•
Prompting은 사람이 초거대 언어 모델(LLM)을 제어하고 소통하는 수단이라 볼 수 있음.
•
별도의 파라미터 업데이트 없이 이러한 prompting만 입력하는 in-context learning(ICL) 방식을 통해 LLM이 다양한 문제에서 뛰어난 성능을 보여주고 있음
•
이 아티클에서는 복잡한 추론(reasoning) 문제에서 최신 방법론인 diversity of thought와 관련한 주요 reference들에 대하여 소개함

•
리뷰 논문
◦
◦
◦
◦
개요
•
일반적인 Prompting은 지시문과 예제(zero-shot인 경우는 지시문만)로 구성되며 최종 결과를 바로 생성하게 하는 방식
•
여기서 소개하는 논문들이 제안하는 방법은 크게 2가지로 나눌 수 있음
◦
풀이 과정을 LLM이 스스로 생성 : Scratchpads, CoT
◦
LLM이 문제를 여러 번 풀게 한 후 Ensemble : SC, DoT
•
이는 예를 들어 사람이 수학 문제를 풀 때 풀이 과정을 적고, 여러 번 검산하는 것과 비슷한 느낌으로 해석할 수 있음
방법론
•
Method 1 : 풀이 과정을 LLM이 스스로 생성
◦
Scratchpads와 CoT 모두 풀이 과정을 모델이 스스로 생성하는 점은 동일하나 CoT가 좀 더 자연어 형식으로 생성한다는 점에서 차이가 존재함.

Scratchpads
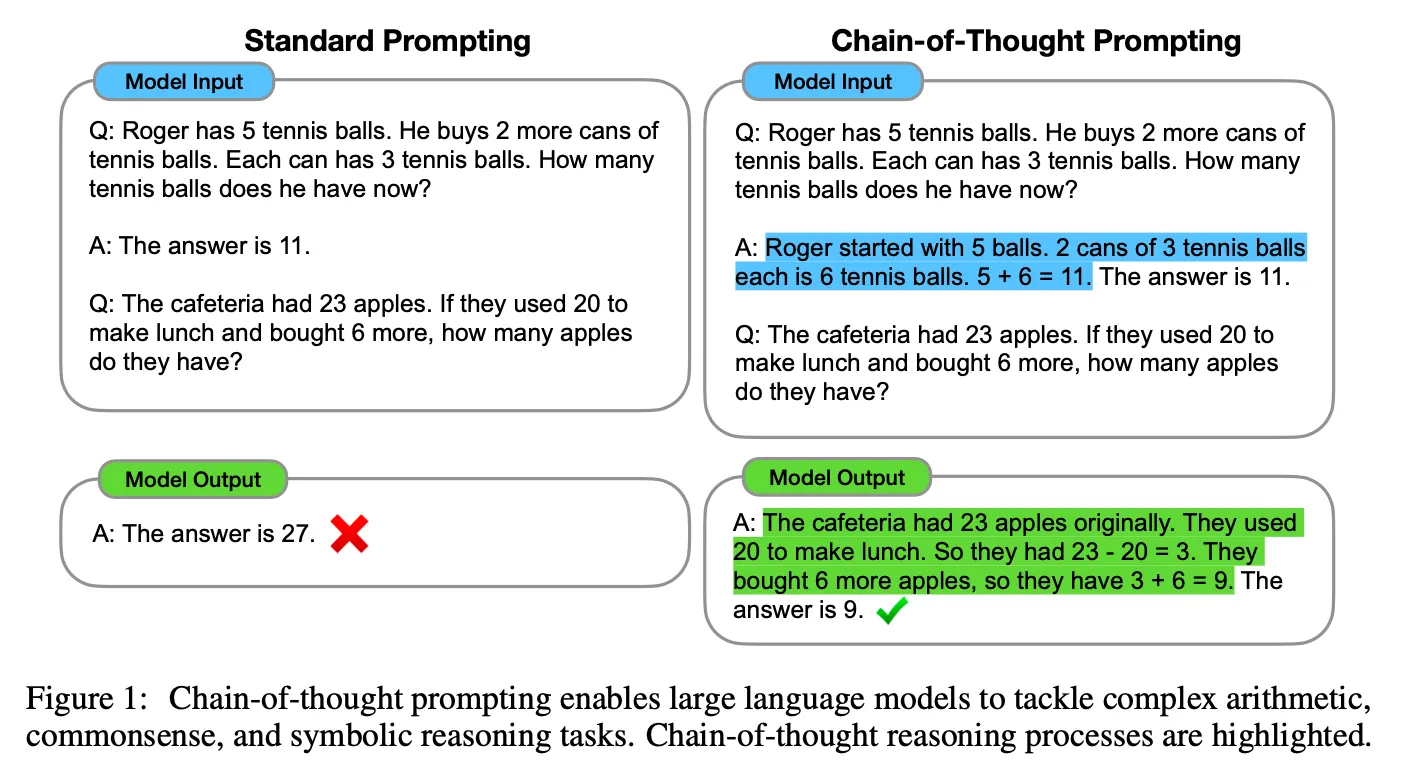
Chain-of-Thought
◦
비록 Scratchpads가 먼저 나왔으나 CoT 방식이 자연어 형태로 생성하여 LLM 능력을 leverage하는데 더 효과적이며 더 다양한 task에 적용 가능할 수 있는 일반적인 방법론이라 CoT가 이후 더 주목받은 것으로 생각됨
•
Method 2 : LLM이 문제를 여러 번 풀게 한 후 생성 결과를 emsemble
◦
SC
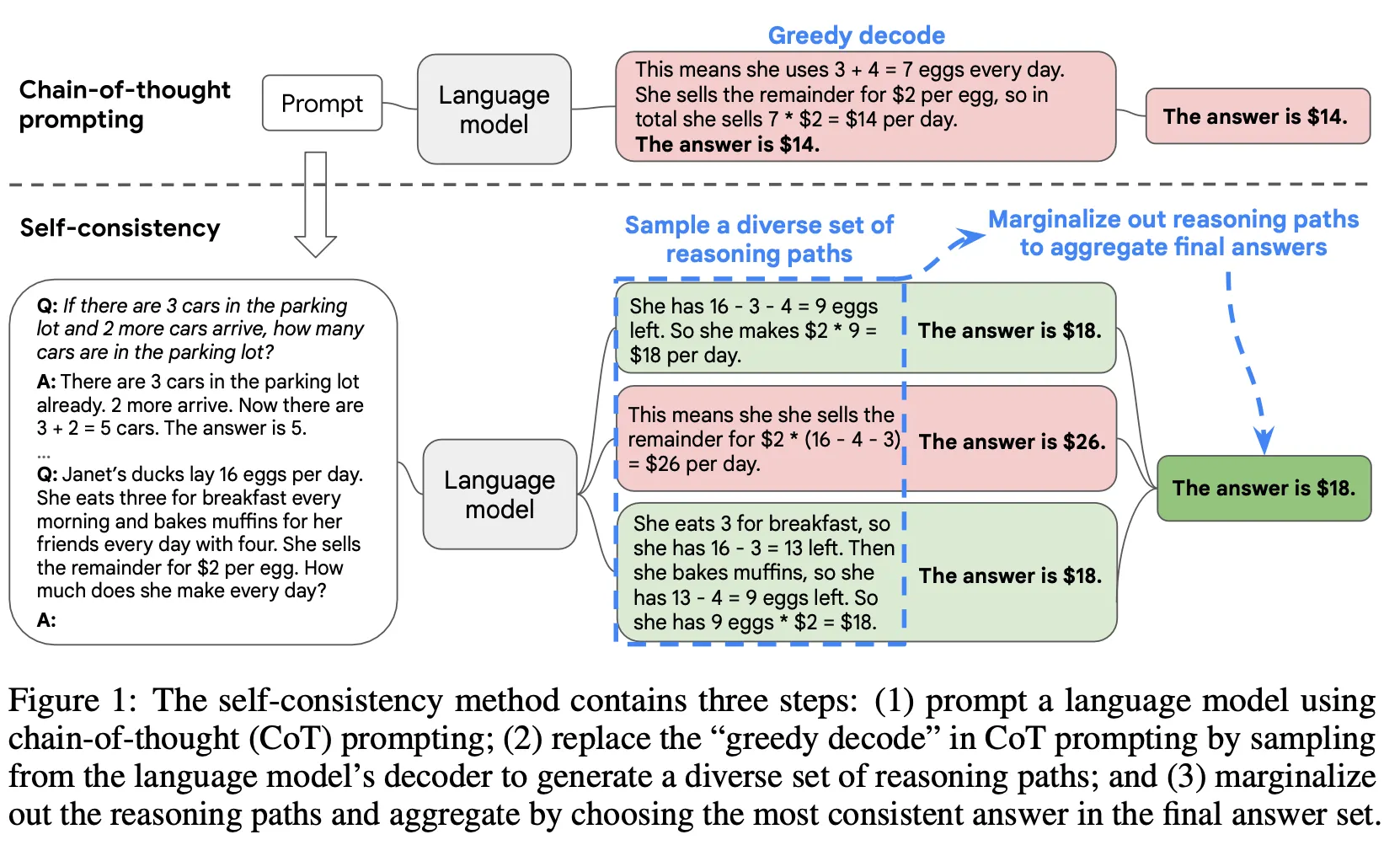
▪
CoT Prompting을 LLM에 입력하여 여러 종류의 결과를 생성
▪
생성한 결과에 대하여 majority vote를 적용하여 가장 많은 수의 답변을 최종 답변으로 결정
▪
다양한 종류의 decoder sampling 방법(e.g., temperature, top-k, top-p, nucleus sampling 등) 적용 가능
▪
◦
DoT

▪
하나의 질문에 대해서 서로 다른 “approach”로 풀이 과정을 생성하고 결과를 도출한 후 ensemble 하는 방법
▪
주어진 질문에 대하여 어떤 approach로 답을 구하라는 지시문을 입력. 위 예제에서는 “Using direct calculation”, “Using algebra”, “Using visualization” 3가지 approach로 생성하고 있음
▪
2가지 방법론을 제안.
•
DIV-SE(DIVerse reasoning path Self-Ensemble) : 하나의 프롬프트는 하나의 방법만 생성하게 한 후 총 n 번 호출을 하여 생성하는 방법
•
IDIV-SE(In-call DIV-SE) : 위 그림의 예제처럼 하나의 프롬프트에 n 가지 방법에 대한 답을 동시에 생성하는 방법
결과
•
Standard Prompting vs CoT
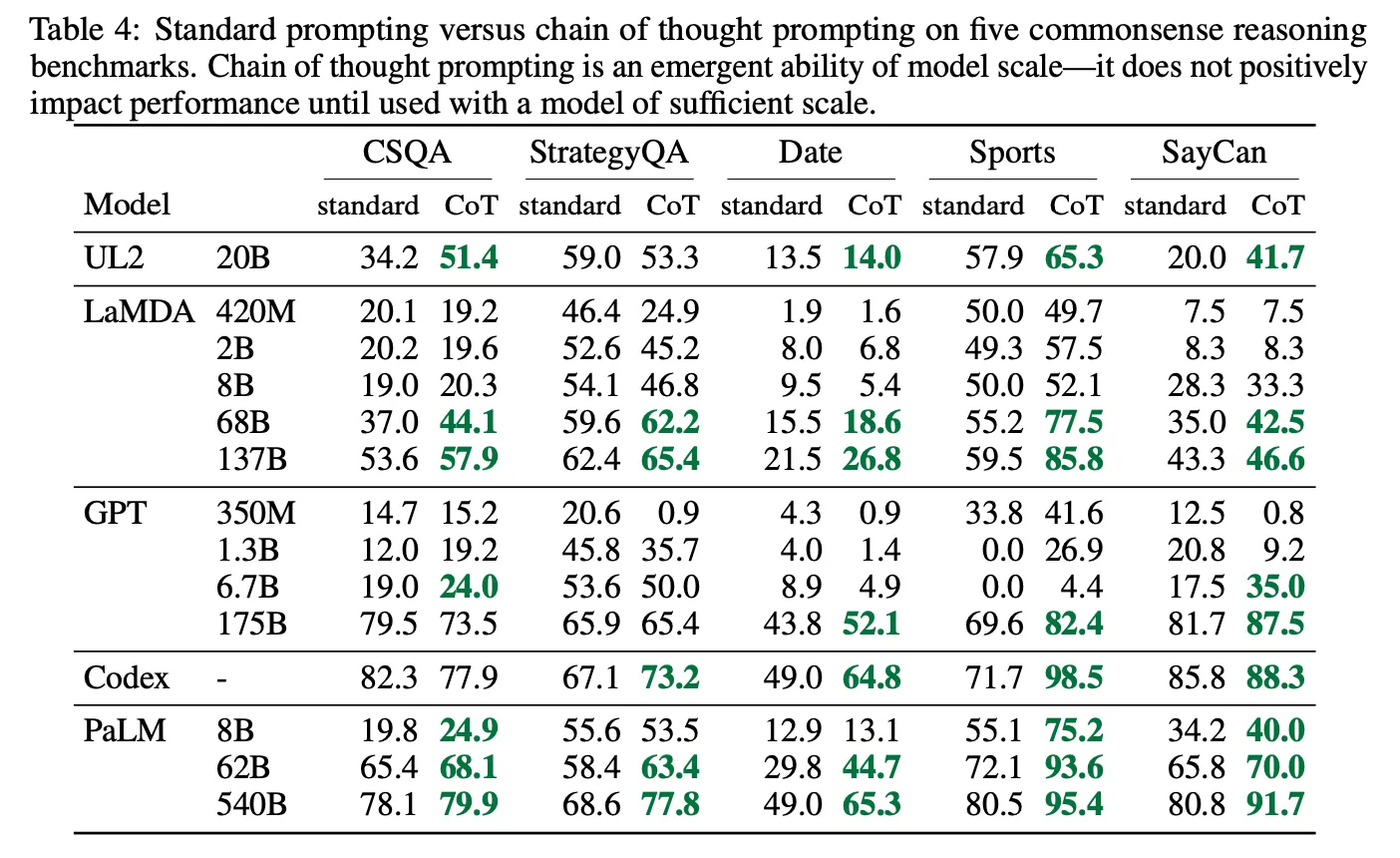
◦
LLM의 크기가 작은 경우 오히려 성능 하락이 존재하나 모델이 큰 경우 (60B 이상) 비교적 큰 폭의 성능 향상 존재 (emergent ability)
◦
작은 LLM의 경우 잘못된 풀이 과정을 생성하고 그것이 noise로 작용하는 경우가 많아서 성능이 오히려 하락한 것으로 보임
◦
위 현상은 LLM의 절대 크기보다는 LLM이 가진 능력에 더 큰 영향을 받음. 즉, sLLM이라도 최근 등장하는 훨씬 뛰어난 모델들의 경우는 효과가 있음 (e.g., 20B 크기인 ChatGPT)
◦
다양한 종류의 task에서 효과가 있음
•
CoT vs SC
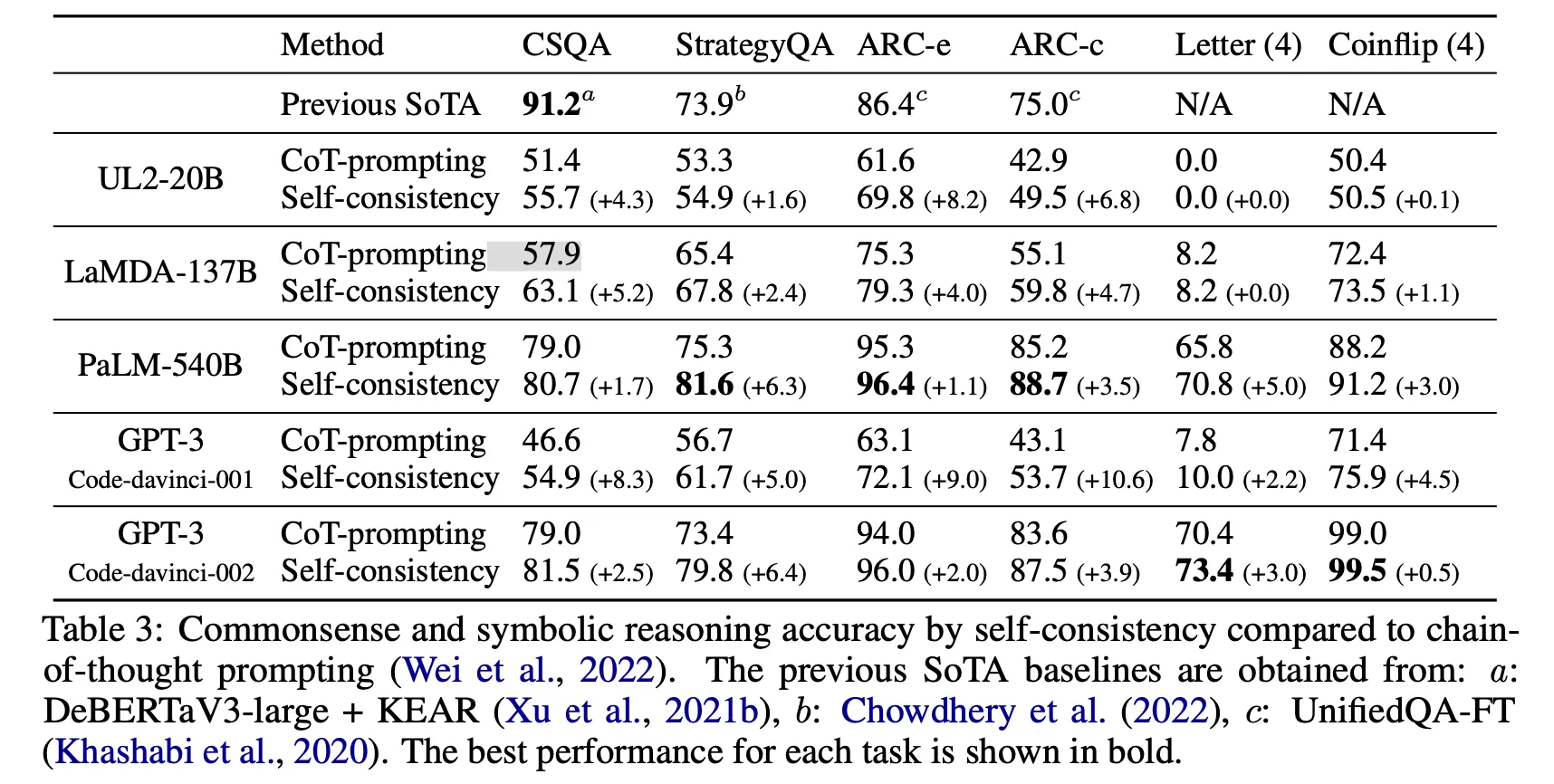
◦
점수 상승 폭에는 차이가 존재하나 single inference 대비 거의 모든 LLM, 모든 task에서 효과가 있음
◦
단, sampling 하는 횟수만큼 LLM을 호출해야 하므로 비례해서 추론 비용이 발생
•
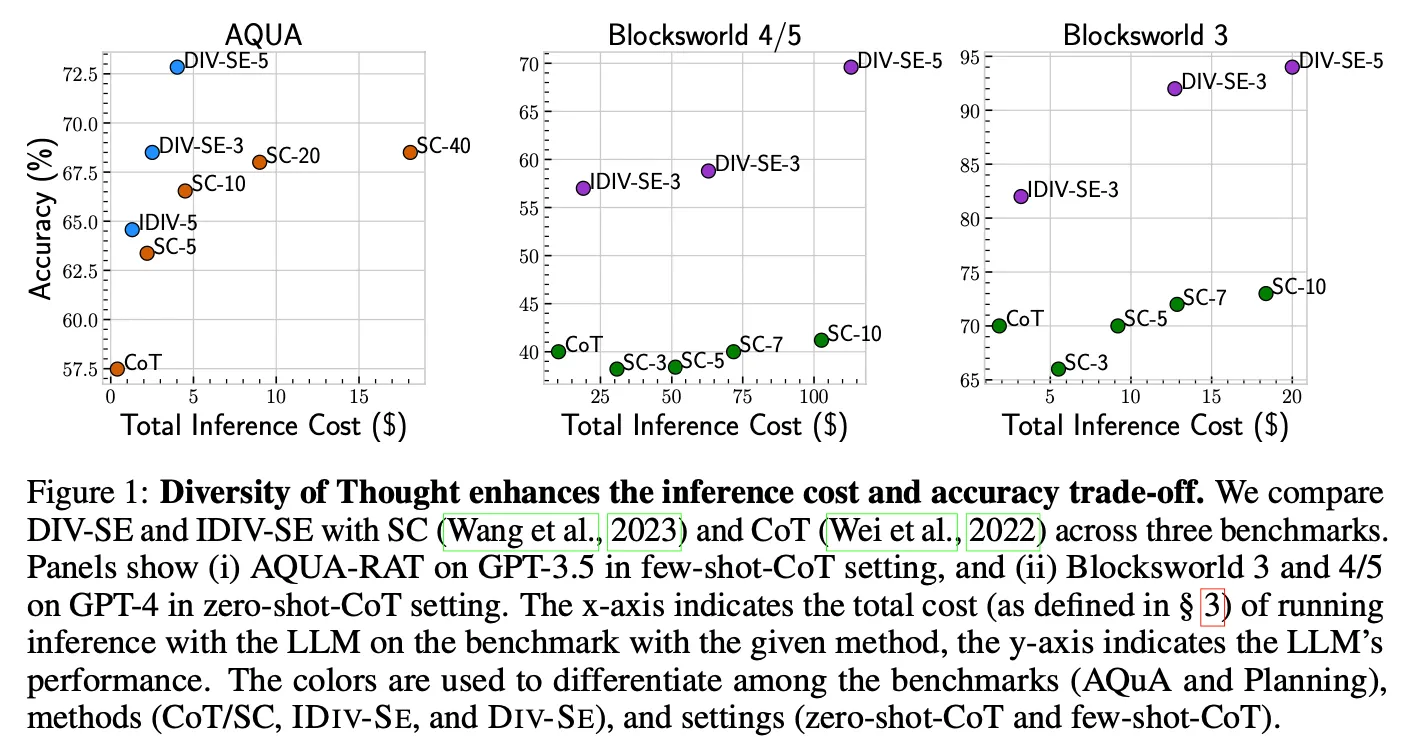
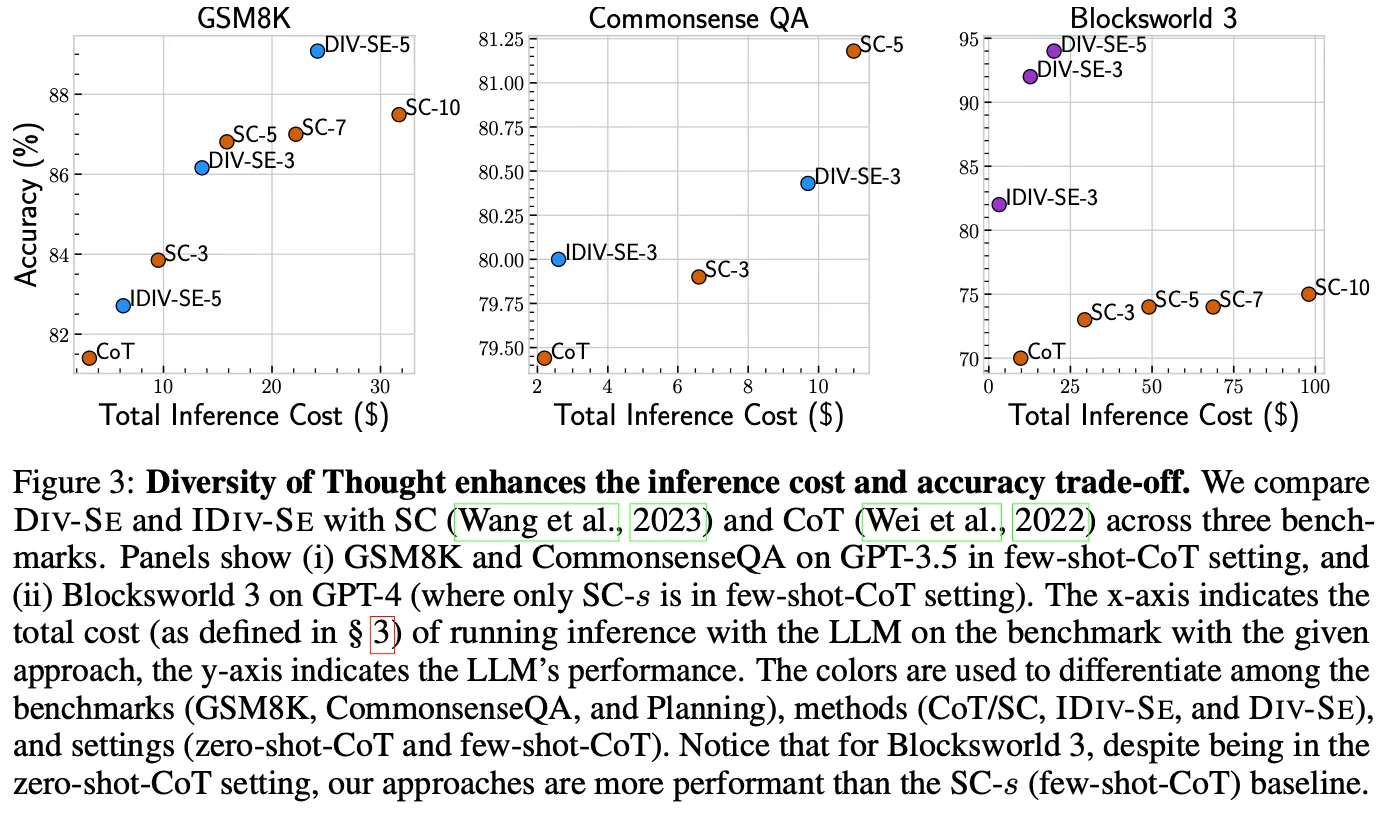
SC vs DoT
◦
더 좋은 cost-performance tradeoff를 제공
논의사항
•
LLM의 능력이 좋아지면서 zero-shot, few-shot으로 해결할 수 있는 문제의 종류 및 수준이 점차 높아지고 있음.
•
따라서 최적의 결과를 얻기 위한 prompt 설계 방법론이 앞으로도 점점 중요성이 높아질 것 같음
•
프롬프트를 통해 성능을 향상하기 위한 비교적 간단하고 유용한 방법론으로 참고할 만한 결과라 판단