

도입
•
LLM이 생성한 결과에 대해 어떻게 자동으로 평가할 것인지(LLM-as-a-Judge)는 최근 여전히 뜨거운 연구 주제
•
이러한 능력은 모델 답변이 적절한지 여부를 평가하는 것 뿐만 아니라 데이터에 대한 Labeling도 자동화 가능
•
이를 통해 사람들은 모델이 스스로 결과를 생성하고 판단하며, 판단 결과를 다시 학습하는 과정을 무한 반복함에 따라 AI가 스스로 똑똑해질 수 있다는 기대(또는 두려움)를 하며, 그래서 관심이 많은 것으로 보임
•
이 아티클에서는 LLM의 평가 능력을 향상시키기 위한 서로 다른 Meta의 최근 논문 2편을 묶에서 소개함
•
리뷰 논문
◦
◦
개요
•
요약 : LLM의 평가 능력을 향상시키기 위해 학습할 데이터를 생성하는 서로 다른 두 방법론을 다룸
•
첫 번째 논문은 모델의 판단 결과를 평가하는 Meta-Judge 개념을 도입하고 이것을 활용한 Meta-Rewarding 이라는 새로운 학습 방법을 제안하고 LLM의 Self-Improvement 과정을 고도화
•
Llama-3-8B-Instruct 모델을 사용하여 예전 버전의 GPT-4 보다 더 뛰어난 성능을 달성하였으며 Claude 3 Opus 와 비슷한 수준을 달성. 특히 Meta-Judge는 모델의 판단 능력을 향상시킴
•
두 번째 논문은 Original Instruction과 LLM을 통해 생성한 Noisy Instruction을 활용하여 학습할 데이터셋을 구성하였으며, Llama-3-70B-Instruct 모델을 통하여 효과를 입증
Meta-Rewarding
Method

•
Previous Method : Self-Rewarding Language Models
◦
◦
여기서는 Actor와 Judge만 존재하며, Judge 모델의 판단 결과를 기반으로 Preference Dataset을 구성하여 DPO 방식으로 모델을 튜닝하는 과정을 반복
◦
이 때 Preference Dataset은 동일 문제에 대한 여러 개의 판단 결과 중에서 최고점을 받은 답변과 최저점을 받은 답변으로 구성. 즉, Length-bias에 대한 고려는 없었음
•
LLM은 다음의 3가지 역할을 수행
◦
Actor : 주어진 task에 대한 답변을 생성. Llama-3-8B-Instruct 사용
◦
Judge : 생성한 답변의 점수를 평가하고 그 설명을 기술. Llama-3-8B-Instruct 사용

▪
5점 scale로 아래 이미지와 같은 rubric을 근거로 답변 채점 및 근거 작성
▪
앞선 연구에서 사용한 프롬프트와 동일
◦
Meta-Judge : Judge 단계에서 생성한 판단에 대한 평가를 수행. Llama-2-70B-Chat 사용

▪
보다 정확한 판단을 위하여 성능 좋은 LLM을 사용한 것으로 추정
▪
Meta-Judge 능력을 추가로 더 튜닝하지는 않음
•
데이터셋 생성 방법
◦
주어진 task에 대해서 Actor 모델에서 여러 개의 답변을 생성()
◦
각각의 답변에 대해서 Judge 모델로 여러 개의 평가 결과를 작성(에 대한 평가 : )
◦
Actor Preference Dataset 생성
▪
동일한 문제에 대해서 Judge 모델의 평가 결과 중에서 높은 점수를 갖는 답변()와 낮은 점수를 갖는 답변()을 각각 선택하여 Preference Pair로 구성
▪
그러나 이때 단순히 모델의 평가 점수만 신뢰할 경우 Length-bias의 영향을 크게 받음. 따라서 그것을 조정하기 위한 Length-Control Mechanism을 적용
▪
Length-bias : Reward Model에서 일반적으로 더 긴 길이의 답변이 선호된다는 현상 (https://arxiv.org/abs/2404.04475, https://arxiv.org/abs/2403.19159, https://arxiv.org/abs/2406.17744)
◦
Judge Preference Dataset 생성
▪
Judge 모델의 평가 점수 Variance가 가장 큰 답변을 대상으로 선택. 모델이 평가하기 어려운 문제를 고른다는 취지
▪
각 답변에 대한 N개의 평가를 Pairwise로 Meta-Judge 프롬프트에 넣고 결과를 생성. Positional Bias를 제거하기 위하여 아래와 같이 Weight를 구하고 최종 Battle Matrix를 생성

▪
이렇게 생성한 B를 바탕으로 각 Judgement별로 Elo Score를 계산한 후 가장 높은 점수와 낮은 점수를 받은 Judgement를 선택
•
학습 방법
◦
이전 단계에서 학습한 모델로 생성한 데이터를 기반으로 튜닝

Results
•
GPT4-Turbo 답변과 선호도 비교 평가
◦
8B 모델로 GPT-4-0314, GPT-4-0613 보다 더 높은 성능을 달성했으며 Claude 3 Opus와 비등한 성능 달성

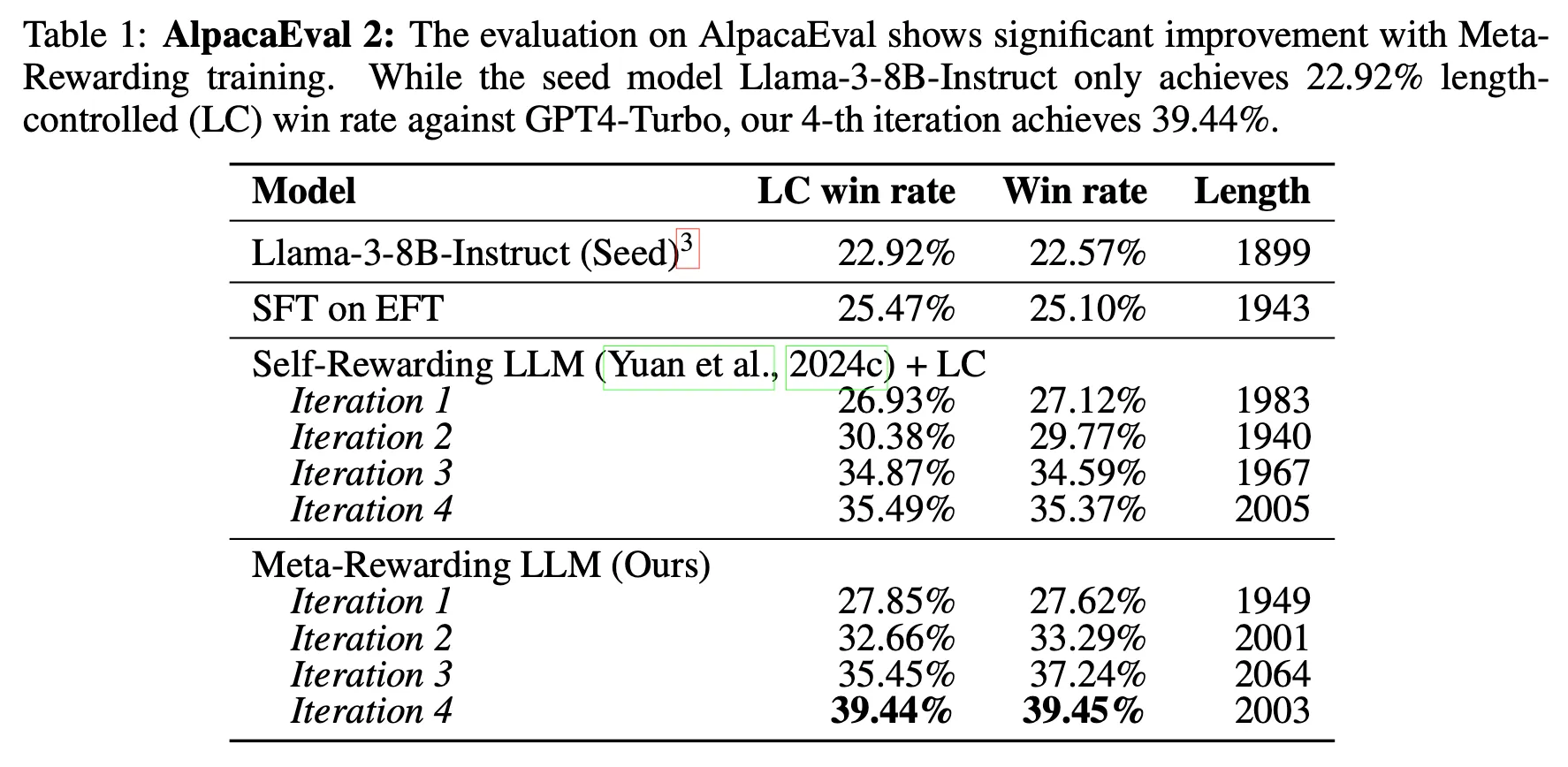
•
단, 보다 어려운 문제(Arena-Hard)에서는 GPT4-Turbo 대비 win rate이 감소. 이 데이터에서는 GPT-4나 Opus 대비 성능이 더 낮을 가능성도 존재
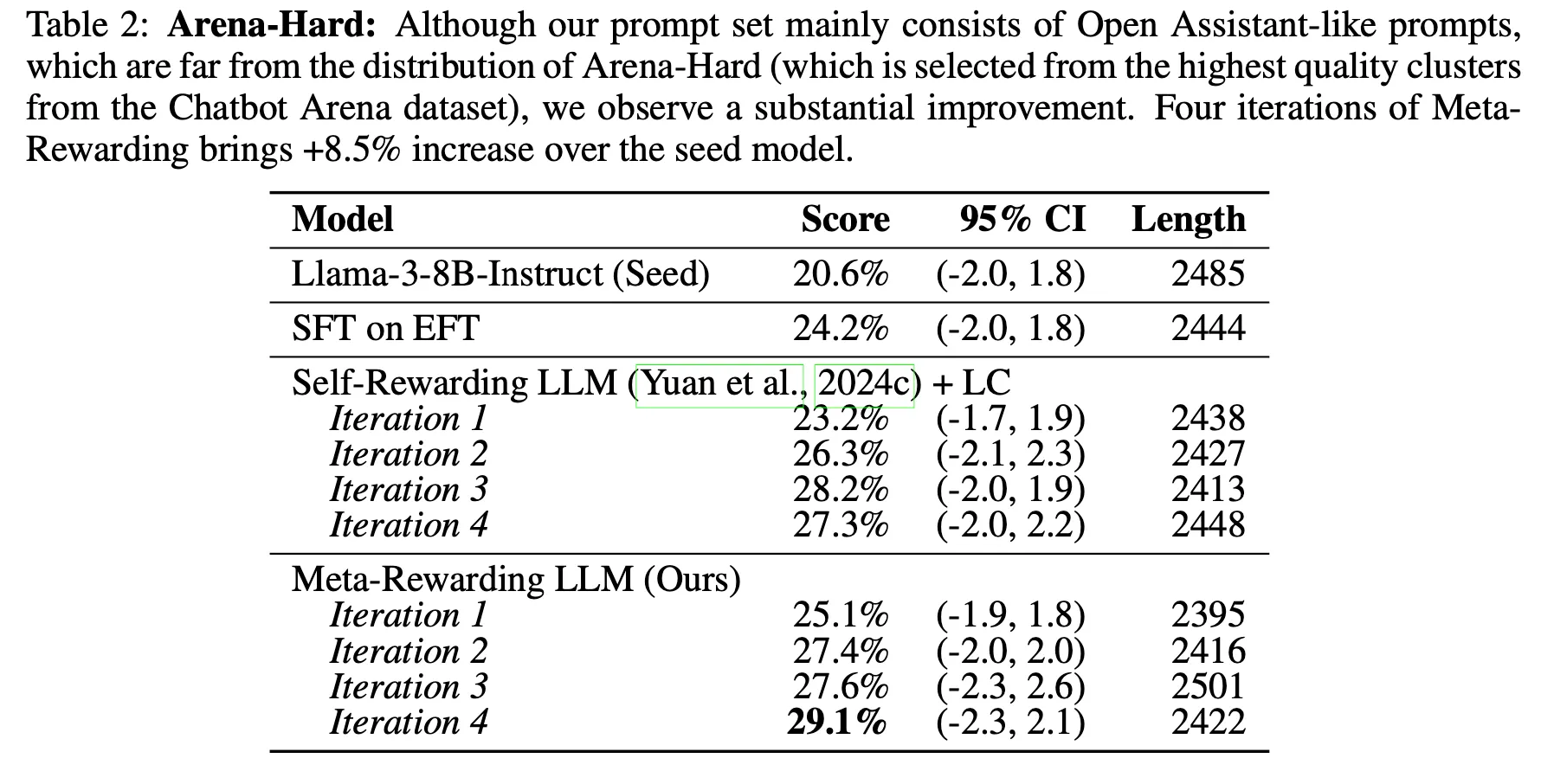
•
이전 방법은 모델의 평가 능력의 한계로 인하여 Iteration 4에서 더 이상 성능이 향상되지 않지만 Meta-Rewarding의 경우 지속적으로 향상됨을 관찰
•
대부분의 카테고리에서 성능 향상이 존재
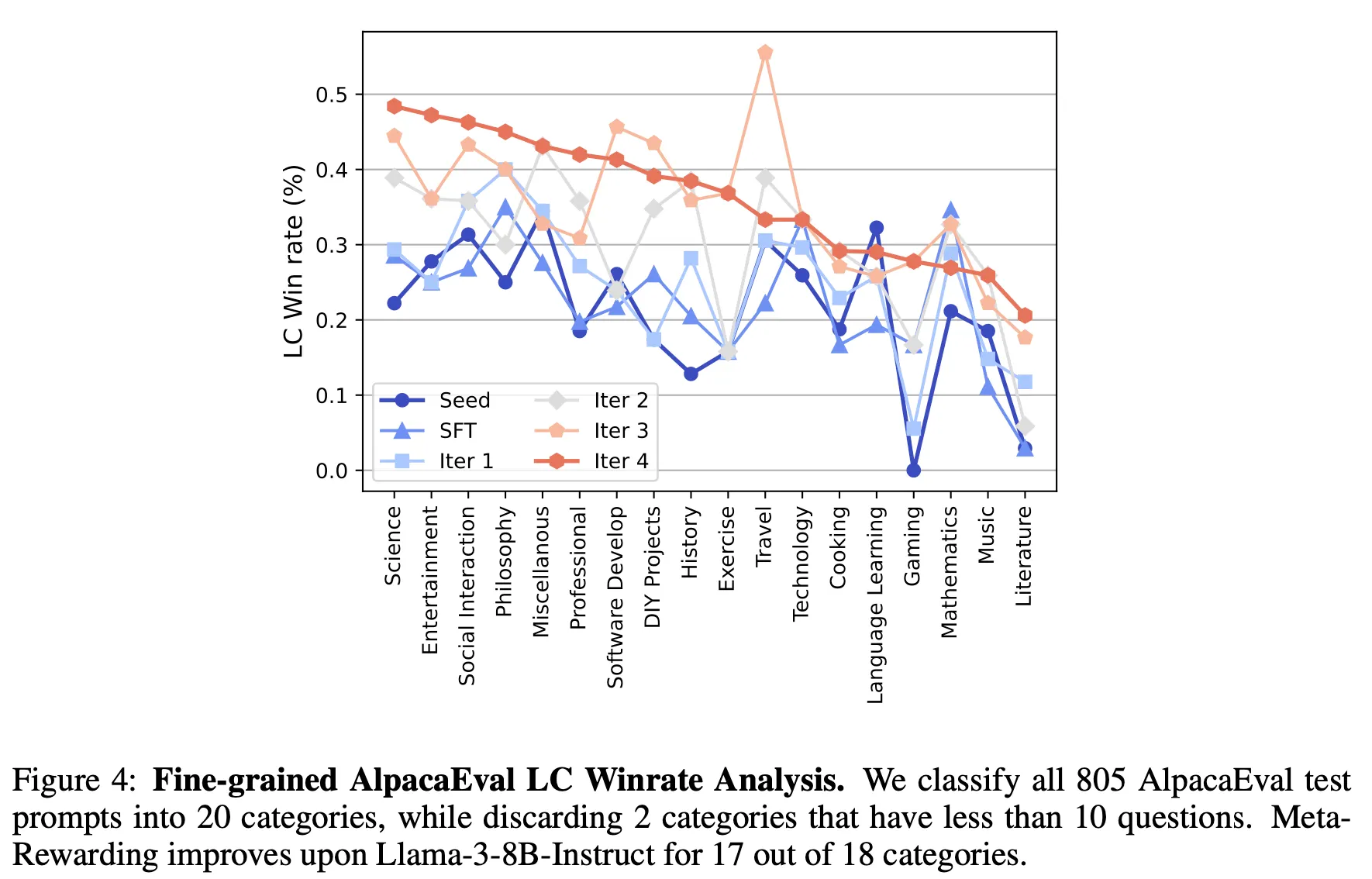
•
Judge 모델의 판단 능력 향상. 단, 이 능력은 Iteration 증가에 따라 지속적으로 향상되는 것은 아님
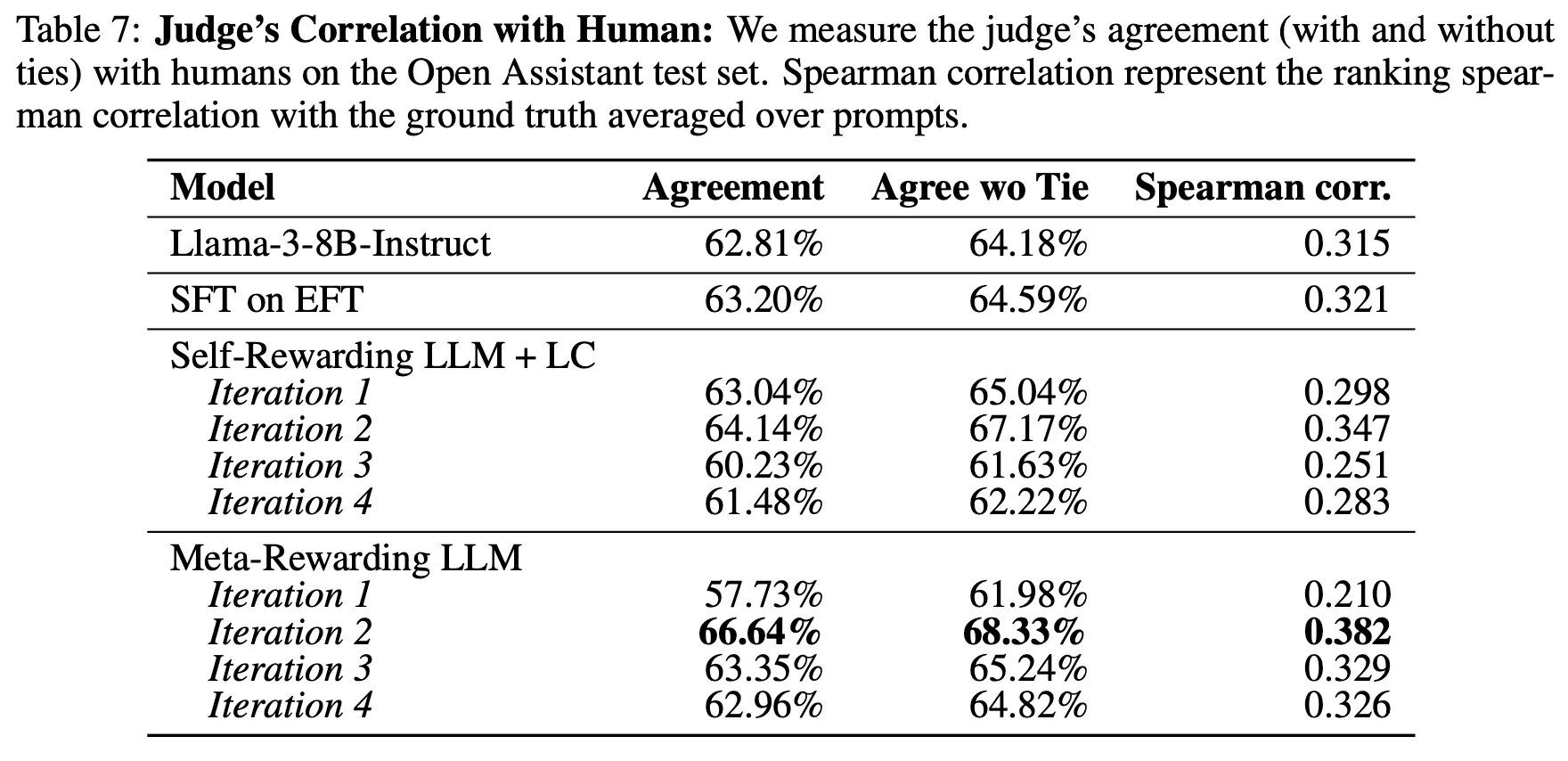
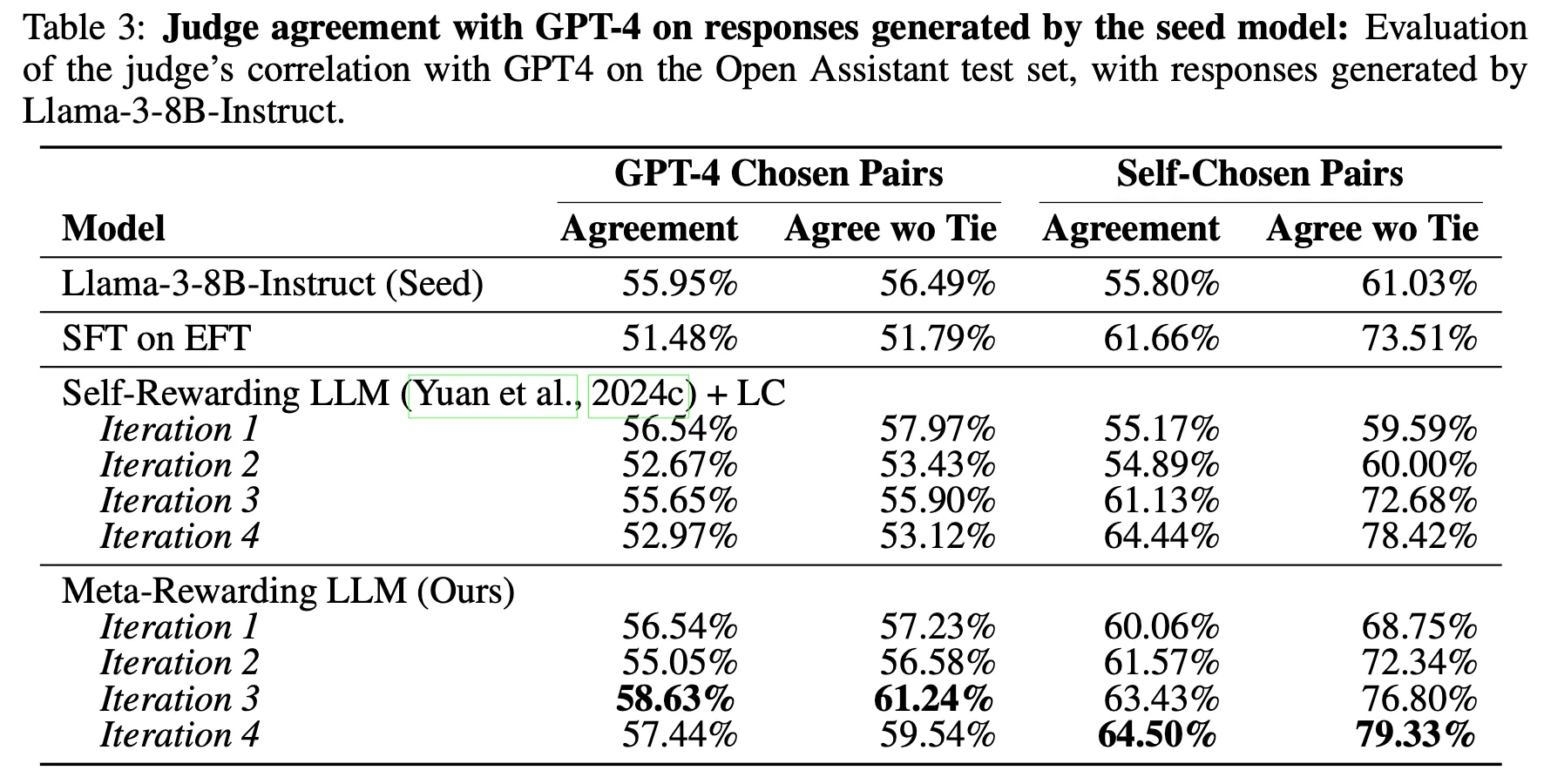
•
Meta-Judge의 bias
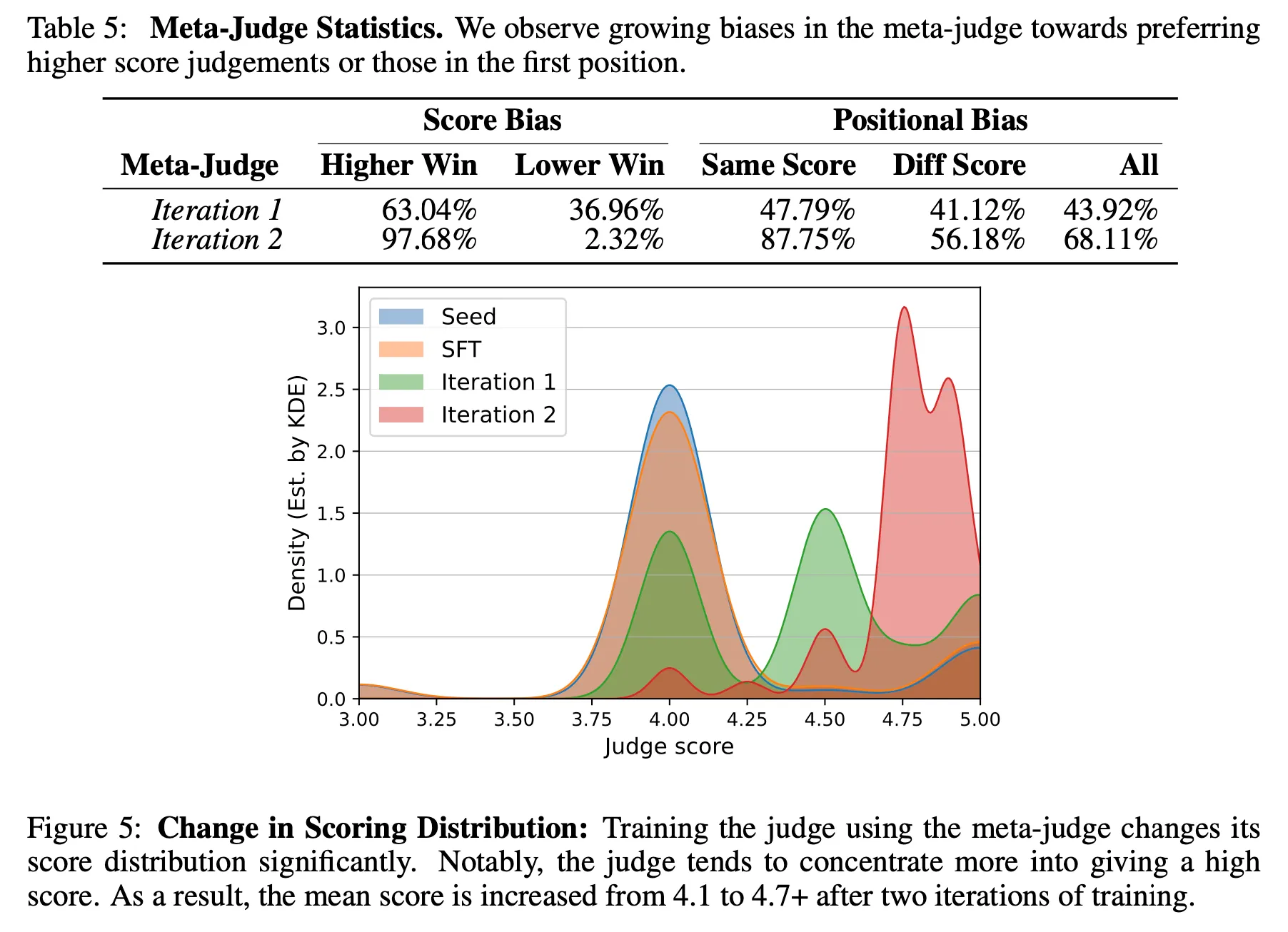
◦
두 번쨰 iteration부터는 score bias와 position bias가 크게 증가 -> Judge 모델의 평가 능력이 지속 향상하지 않는 원인 중 하나일 것으로 추측
Self-Taught Evaluator
Method
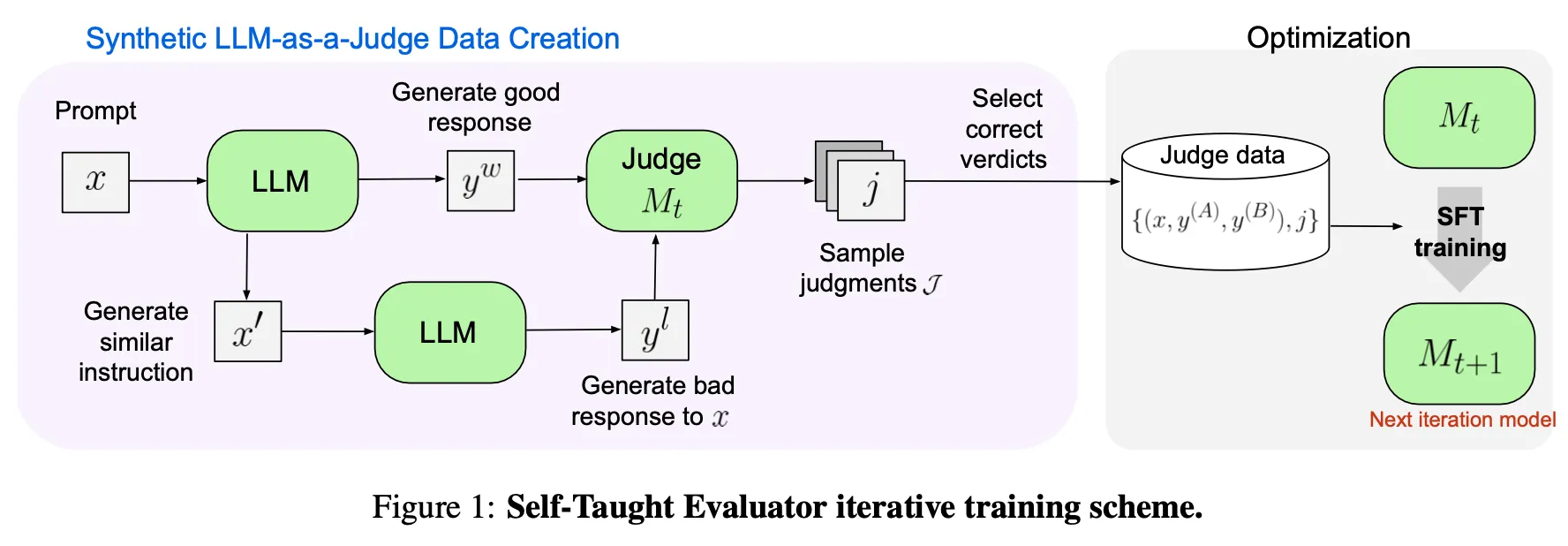
•
위에서 사용한 용어 기준으로 LLM은 Actor, Judge 2가지 역할을 수행
•
데이터셋 생성 방법
◦
사람이 생성한 Instruction Dataset을 수집
◦
LLM을 통하여 Instruction의 카테고리를 분류하고, 복잡도 및 답변 길이에 대하여 Labeling을 수행. Mixtral 22Bx8 모델 사용

◦
분류된 정보를 기반으로 보다 '어려운' Instruction을 선택하고 LLM에 입력으로 넣어 정답을 생성 (Winning Answer)
◦
LLM을 통해 위 Instruction을 비슷하지만 의미상 약간 다른 형태로 변형하여 생성 (Noisy Instruction). 이렇게 생성한 Instruction을 다시 LLM에 넣고 답변 생성 (Losing Answer)

◦
위에서 생성한 두 개의 답변을 바탕으로 LLM을 통하여 총 N개의 평가를 생성. 이 때 Winning Answer를 더 높게 평가하는 결과만 남기고 제거

◦
위 과정에서 생성한 데이터를 Random Sampling하여 학습 데이터를 구성
•
학습 방법
◦
사용한 모델 : Llama3-70B-Instruct
◦
첫 Iteration 단계에서 답변 생성 및 평가 결과 생성은 Mixtral 22Bx8 모델을 사용. 이후로는 직전 단게에서 튜닝된 모델을 사용하여 생성
◦
각 단계에서 생성한 데이터를 Llama3-70B-Instruct 모델에 튜닝. (ith 단계에 학습한 모델에 추가 학습하는 것이 아님. 즉, 중간단계의 모델은 각 단계의 학습 데이터 생성용으로만 활용)
Results
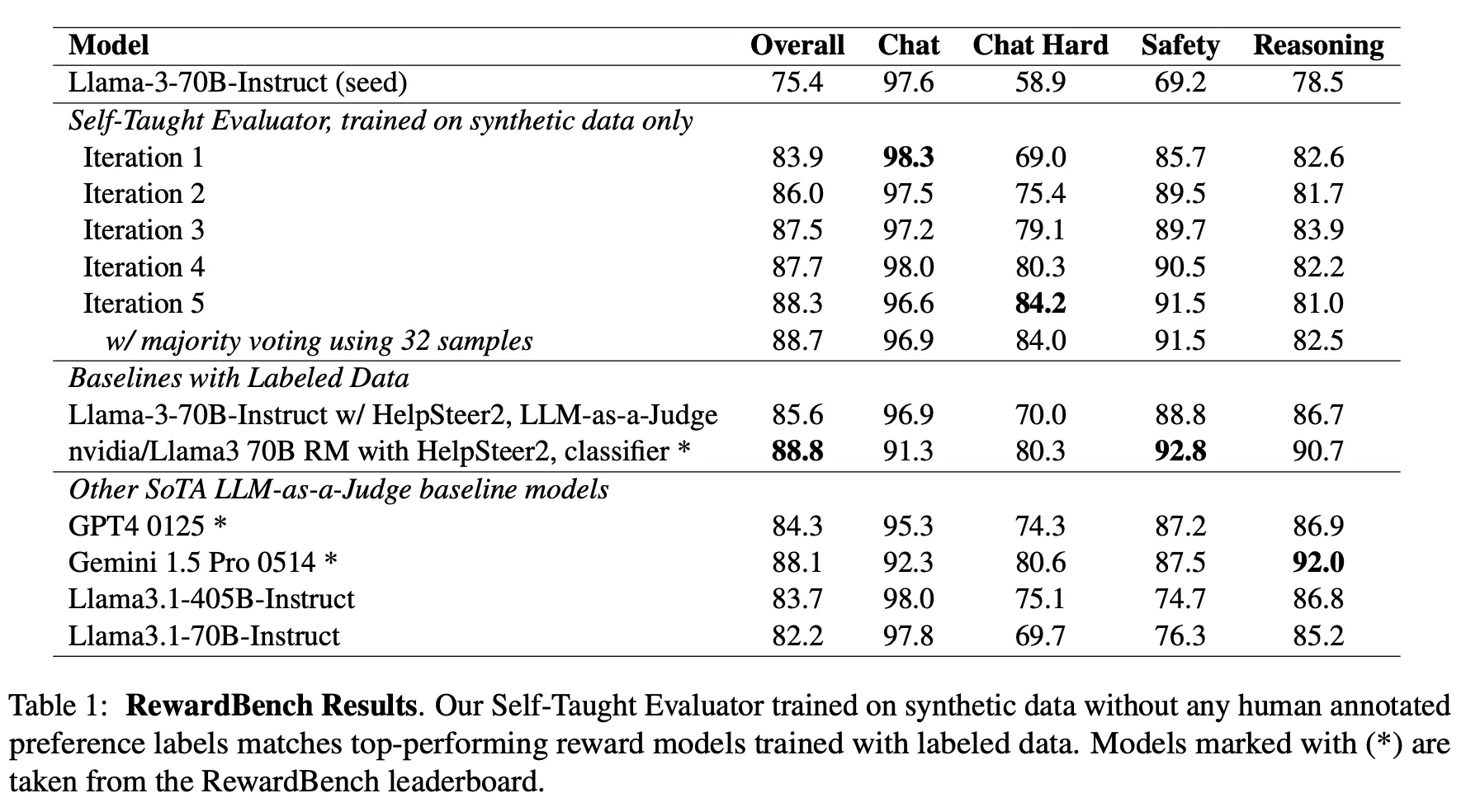
•
단계를 거듭할수록 지속적인 평가 능력 향상이 관찰됨
•
두 개의 입력 중 어떤 것이 좋은지 Binary Classification으로 파인튜닝한 모델과도 거의 비슷한 성능
•
시중에 나와있는 최신 High-end LLM의 평가 능력보다 더 나은 모습을 보임 (OpenAI의 최신 모델 및 Claude 3.5를 실험하지 않은 것은 아쉬움)
Discussion
•
두 논문은 모두 Meta에서 거의 비슷한 시기에 공개되었음. 저자에 Jason Weston만 공통으로 존재하는 것으로 보아 서로 다른 팀에서 비슷한 주제로 연구한 결과라 보임
•
LLM이 평가하는 능력을 향상시키기 위해 Unsupervised 방법으로 Preference Dataset을 구축하는 서로 다른 두 가지 방법에 대한 내용
•
첫 논문의 경우 접근 방법이 비교적 단순한 편으로 고도화 여지는 있어 보이지만 모델의 판단 결과 자체에 대하여 평가하는 Meta-Judge 개념이 동작한다는 것을 보인 첫 사례로 의의가 있다고 판단. 반면 두 평가 결과의 Preference에 대한 판단을 다시 LLM에 맡겨야 한다는 부분에서 한계점도 보임
•
두 번째는 'Noisy Instruction'이란 방법을 적용하여 (어느 정도) 확실하게 두 평가 결과에 대한 Preference를 Labeling할 수 있으며, 따라서 학습 Iteration이 거듭될수록 이 방법의 Upper Limit이 더 높을 것으로 예상
•
두 방법 모두 사용하는 LLM의 능력이 일정 수준 이상이어야 효과가 존재할 것으로 보임. 특히 Meta-Judge 모델은 왠만한 수준의 LLM으로는 만족할만한 결과가 나오지 않을 것으로 예상(아마 그것이 Llama-2-70B-Chat을 사용한 이유일 것으로 추측)
•
그렇더라도 Meta-Judge 능력의 한계로 인하여 Judge 능력의 향상도 빠르게 Saturation이 되므로 Iteration 4 이후에는 높은 확률로 성능이 수렴할 가능성이 존재. 즉, 아직 이 방법 역시 Self-Improvement를 통한 향상의 폭은 한계가 존재하는 것으로 보임