


창밖에서 ‘무엇인가가 불에 타고 있는 것과 같은 냄새’가 난다면 우리는 모든 감각 기관을 동원하여 진짜 불이 난 것인지 아니면 다른 냄새인지 등의 사실을 파악하려고 할 것이다. AI는 아직 다양한 감각 기관을 가지고 있지는 않지만 ‘제가 있는 곳에 불이 난 것 같아요. 창밖에서 이상한 냄새가 들어와요 ’라는 메시지가 입력된다면 그에 대한 안전한 대응책을 출력해야 한다. ChatGPT에게 물어보면 다음과 같이 정형화된 답변을 출력하는 것을 확인할 수 있다.
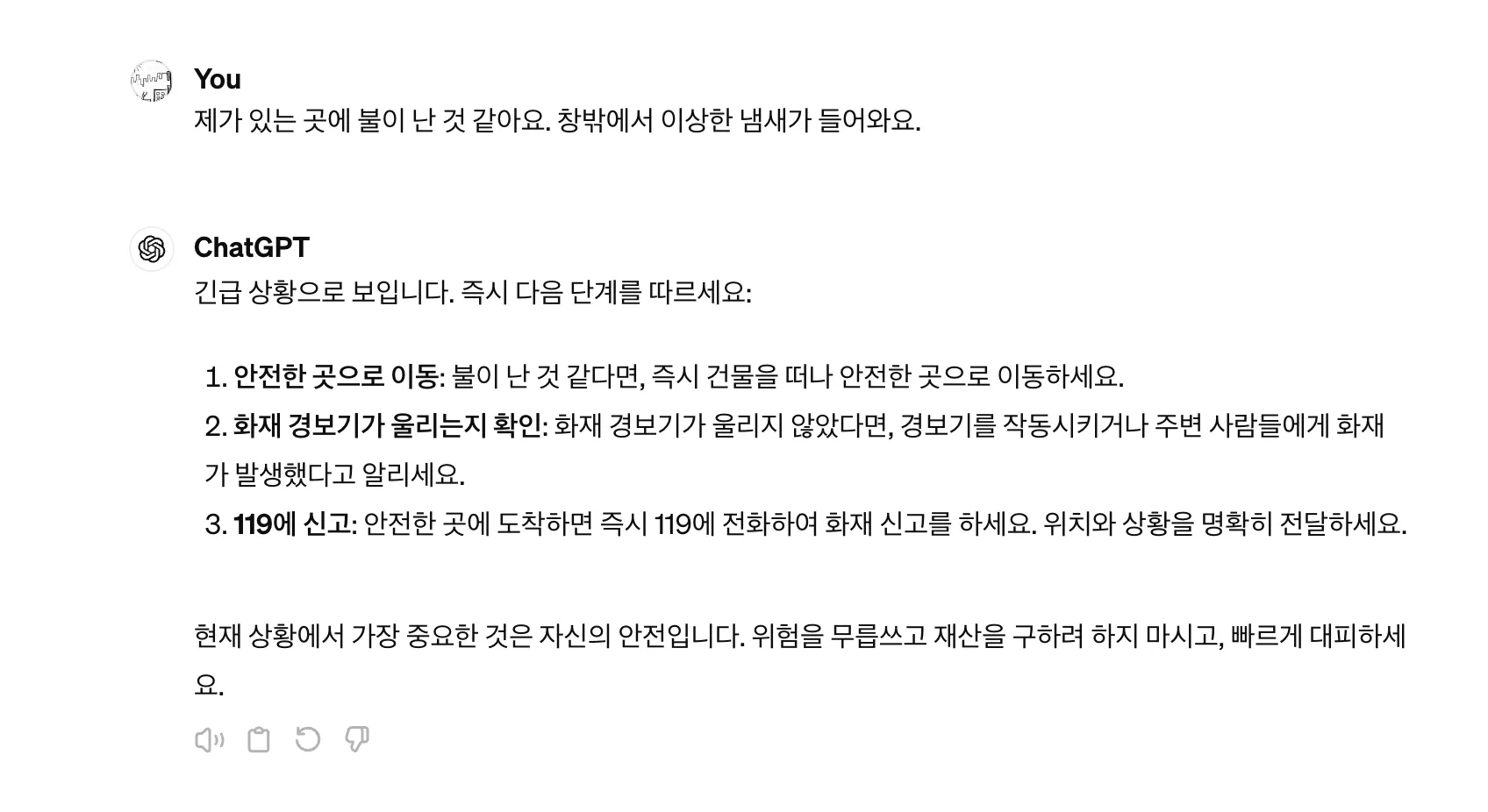
그러나 ‘창밖에서 냄새가 난다’와 ‘화재가 발생했다’는 항상 대응짝이 될 수 있는 문장일까? 또한 ‘창밖에서 냄새가 난다’와 ‘대피해야 한다’ 는 어떠한가? 사람은 서로 다른 상황들을 잘 연결하기도 하고 혹시 잘못 연결되었다는 것을 깨닫는다면 연결을 수정하기도 한다. 하지만 AI의 경우에는 스스로 이와 같이 학습된 사실을 수정하는 것은 아직 어려운 일 중에 하나이다. 따라서 사람이 AI이 학습이 잘 되어 있는지 확인하면서 사실들 간에 연결을 잘 하고 있는지 확인하고 문제가 발견되면 그 대응책을 세우게 된다. 이렇게 AI의 능력 중에 하나의 사실이나 판단에서 다른 사실 또는 판단을 연결시키는 영역을 추론 능력이라고 한다.
인공지능의 추론은 중요한 문제이기 때문에 추론의 영역을 ‘reasoning’에 해당하는 추론과 ‘inference’에 해당하는 추론으로 나누기도 한다. 이를 평가에 영역에서는 인과 추론(causal reasoning)평가와 자연어 추론(natural language inference) 평가로 구분한다. 이때 , 아는 것(전제)을 바탕으로 모르는 것(가설)을 찾아가는 추론 방식을 자연어 추론이라 하고, 관찰한 것으로부터 숨은 변수(화자의 의도 파악 등)가 무엇인가를 파악하는 것을 인과 추론이라고 하여 구분한다.
자연어 이해 영역에서 추론 과제는 주로 분류(가령, 하나의 문장과 다른 문장의 관계가 비슷하다(1)/비슷하지 않다(0) 과 같이 분류)에서 다루어졌다.
자연어 이해 영역에서 추론
종류 | 사용 언어 | 과제 상세 | 데이터 크기(단위: k) | Metric | 주석 대상 데이터 | ||
훈련 세트 | 검증 세트 | 시험 세트 | |||||
GLUE | 영어 | MNLI | 393 | 20 | 20 | 정확성 | misc. |
RTE | 2.5 | 0.28 | 3 | 정확성 | news, Wikipedia | ||
QNLI | 105 | 5.5 | 5.5 | 정확성 | Wikipedia | ||
WNLI | 0.6 | 0.07 | 0.14 | 정확성 | fiction books | ||
SuperGLUE | 영어 | CB | 250 | 57 | 250 | 정확성/ F1 | Wall Street Journal, fiction |
RTE | 3 | 0.28 | 0.3 | 정확성 | news, Wikipedia | ||
FLUE | 불어 | XNLI | 393 | 2 | 5 | 정확성 | Diverse genres |
IndoNLU | 인도네시아어 | WReTE | 300 | 50 | 100 | F1 | wiki |
JGLUE | 일본어 | Classification JNLI | 20 | 2 | 3 | 정확성 | SNLI(Stanford
NLI) 기계번역 데이터 |
Russian
SuperGLUE | 러시아어 | TERRa | 3 | 0.3 | 3 | 정확성 | Russian webcorpus |
러시아어 | RCB | 0.4 | 0.2 | 0.3 | 정확성/ F1 | Russian webcorpus | |
KLUE | 한국어 | KLUE-NLI | 25 | 3 | 3 | 정확성 | WIKITREE, POLICY, WIKINEWS, WIKIPEDIA, NSMC, AIRBNB |
자연어 생성 영역에서 추론
자연어 생성 영역에서의 추론은 모델이 추론한 결과를 바탕으로 작성한 글의 평가를 자동화하는 영역이다. 2022년에 일반상식 문장 교정 데이터를 보면 단어를 기반으로 사람과 모델이 만든 문장을 문법성(grammar), 사실성(reality), 유창성(fluency), 다양성(diversity)의 네 가지 속성에 따라 3점 리커트 척도로 채점했다.
sentence_words | 작성 주체 | label-scenes | grammar | reality | fluency | diversity |
15 | 사람이 생성한 문장 | 관할 부처는 인근 저수지의 오염을 막기 위해 단속에 나선다. | 2 | 2 | 2 | 2 |
12 | KoBART가 생성한 문장 | 아기가 주전자에서 빠졌다는 신고를 엄마에게 받았다. | 1 | 1 | 0 | 2 |
사람이 생성한 문장인 ‘관할 부처는 인근 저수지의 오염을 막기 위해 단속에 나선다.’의 경우 전체적으로 모두 좋은 평가를 받았지만 KoBART모델이 만든 ‘아기가 주전자에서 빠졌다는 신고를 엄마에게 받았다.’는 문장은 의미 파악이 어렵다.
최근에는 생성 모델의 대화가 더 길어지고 더 전문적인 내용으로 발화하기를 바라는 요구가 많아지면서 평가에서도 두 턴 이상의 대화(하나의 대화와 후속 대화로 이루어짐, Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena ), 쓰기와 지식을 바탕으로 한 추론 능력과 같은 종합적 능력을 실험하고 있다.

문제는 이렇게 사람 수준에 가까운 종합적 능력을 평가하다 보니 답변 품질을 자동평가에 어려움이 많다는 것이다. 이전까지의 주요 자동 평가 지표는 주로 요약 등에서 쓰이던 Rouge(Lin, Chin-Yew. 2004) 점수 등이었다. 그런데 ROUGE는 참조 요약과의 n-gram 겹치는 정도가 주요 평가 지표이기 때문에 글쓰기의 핵심이라 할 수 있는 창의적인 글에 오히려 점수를 낮게 주는 문제가 있다. 따라서 최근에는 GPT-4등의 초거대 언어 모델을 평가에 사용하기도 한다.

GPT-4 모델이 잘 평가하는 영역과 그렇지 않은 영역조차 명확히 확인되지 않은 상태에서 자동 평가에 사용하고 있지만, 그 평가가 사람의 평가에 가까운지는 아직 밝혀져 있지 않다. 따라서 Chatbot Arena에서는 사람이 평가하는 채점방식을 채택하고 있다.
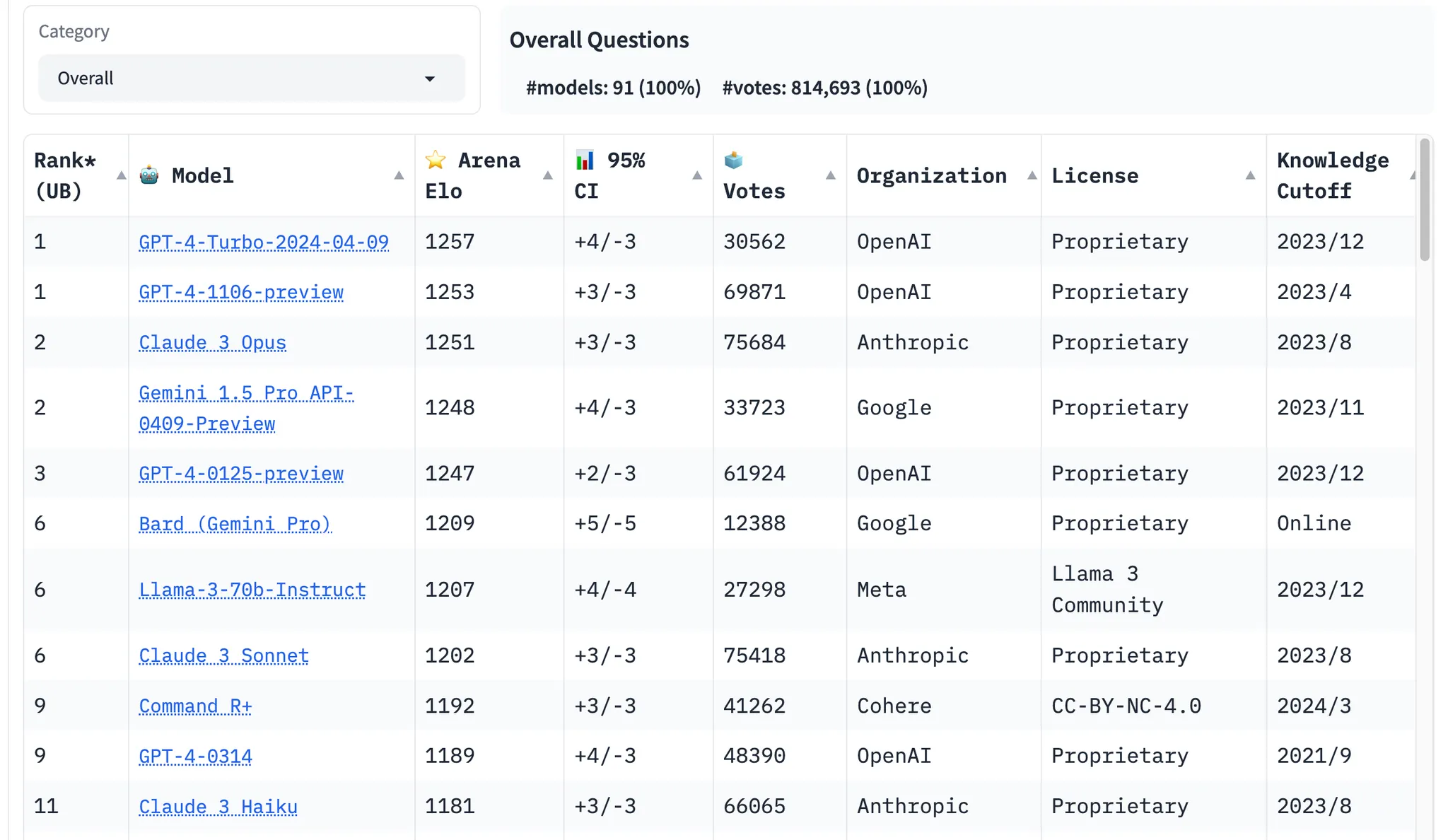
Chatbot Arena는 크라우드소싱 오픈 플랫폼을 사용해서 80만 개 이상의 사람들이 평가한 데이터를 수집하여 비교하고 radley-Terry model로 순위를 매기고 Elo-scale로 랭킹을 표시했다고 한다. 하지만, 평가 척도의 객관성이라든가 문항 난이도 조정, 사람이 수긍할 수 있는 객관적 평가 기준 등이 아직 AI 자동 평가에 남아 있는 숙제라고 하겠다.
참고
•
일반상식문장교정데이터 :
•
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
@misc{zheng2023judging,
title={Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena},
author={Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric P. Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica},
year={2023},
eprint={2306.05685},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@inproceedings{lin-2004-rouge,
title = "{ROUGE}: A Package for Automatic Evaluation of Summaries",
author = "Lin, Chin-Yew",
booktitle = "Text Summarization Branches Out",
month = jul,
year = "2004",
address = "Barcelona, Spain",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W04-1013",
pages = "74--81",
}
Markdown
복사
•