

도입
•
•
이 아티클에서는 알고리즘 문제 뿐 아니라 다양한 natural language task 에서 LLM이 가진 뛰어난 code 생성 능력을 적절히 활용할 수 있는 방법론을 제시한 chain of code 라는 논문을 소개함
•

개요
•
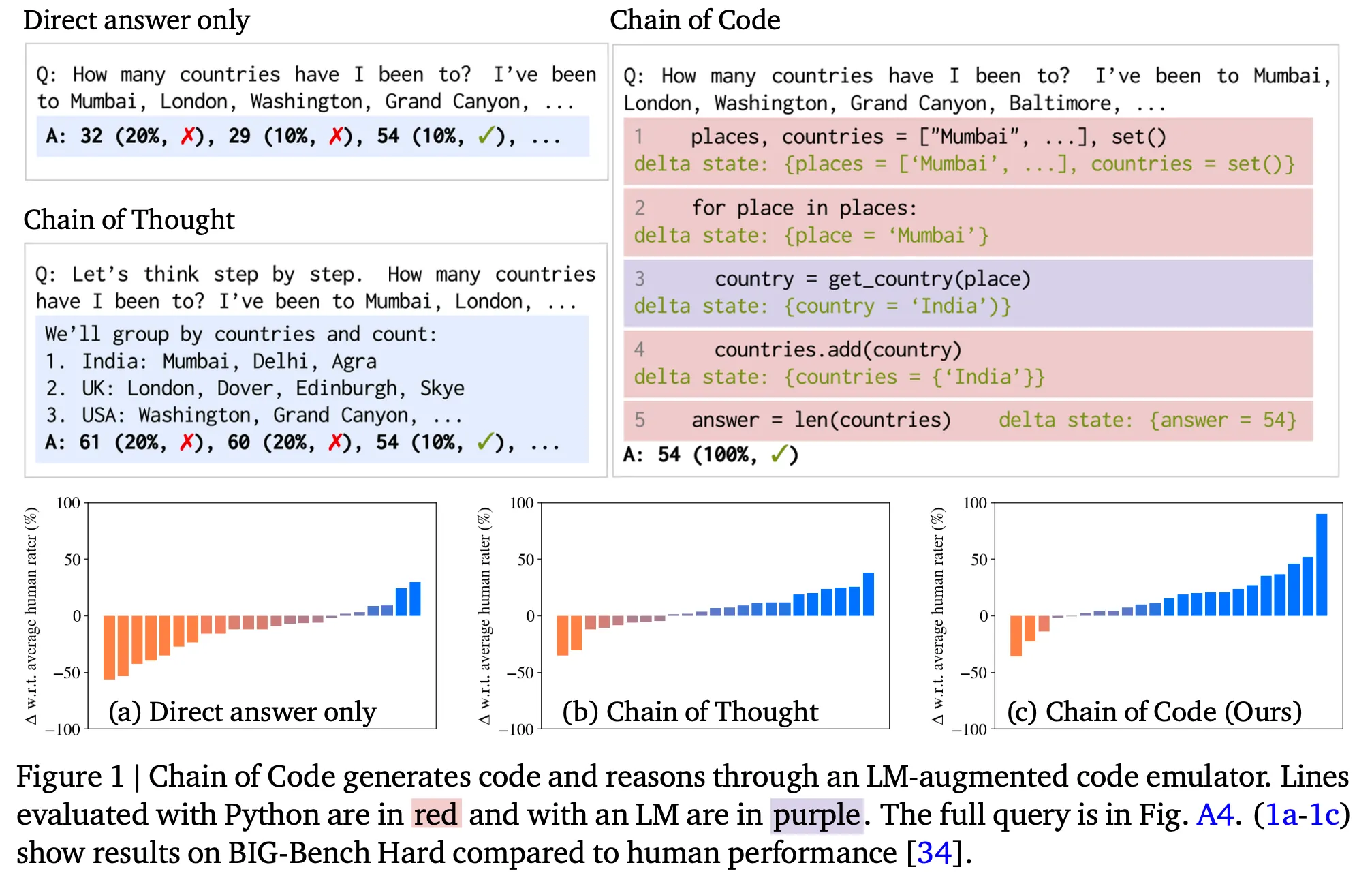
한줄 요약 : LLM에게 code-driven reasoning을 하게 했더니 효과가 좋다는 내용
•
수리적 계산 뿐 아니라 semantic reasoning을 해야 하는 문제에서도 LLM이 (pseudo) code를 생성하게 한 후 적절한 emulator로 실행하여 결과를 얻고 그것을 활용하면 더 좋은 성능을 달성할 수 있음을 보임 (e.g., detect_sarcasm(input))
•
•
특히 CoT는 일정 크기 이상의 LM에서만 효과가 있었던 것과 달리 CoC는 작은 LM에서도 효과가 있었음
방법론 상세
•
대표적인 기존 방법론과의 비교

◦
Scratchpad : 추론 과정을 code 형식으로 생성. LLM이 code interpreter 역할 수행(code의 실행을 LLM이 자체적으로 수행)
◦
Chain of thoughts : 추론 과정을 natural language로 생성. 이 내용을 다음 단계 생성에 활용
◦
Program of thoughts : 추론 과정을 code 형식으로 생성. 생성한 코드는 별도의 code interpreter에서 수행
•
아이디어는 비교적 간단. Code generation과 code execution 단계로 구성
•
Code generation : prompting 기법을 통하여 주어진 문제에 대하여 LLM이 풀이 과정을 code의 형태로 생성하도록 함
•
Code execution
◦
Python interpreter를 우선적으로 사용하며 여기서 실행할 수 없는 부분(e.g., detect_sarcasm(input))은 LLM을 emulator로 사용 (i.e., "LMulator")
◦
기본적으로는 Python의 try/except 문을 활용. 실제 구현 디테일을 기준으로 다음과 같은 variation이 존재
▪
Interweave : 생성 코드를 line by line으로 실행. 오류 발생 시 해당 생성 라인과 이전 context를 LLM에 넣어서 state 값을 출력
▪
try Python except LM : 생성 코드 전체를 Python으로 실행. 오류 발생 시 LM에 넣고 최종 답변을 생성
▪
try Python except LM state : 생성 코드 전체를 Python으로 실행. 오류 발생 시 LM에 넣고 중간 state들을 출력
◦
Baseline
▪
Python : 생성 코드 전체를 Python으로 실행. 실패시 그냥 fail
▪
LM state : 생성 코드 전체를 LM에 넣고 각 단계별 중간 state들을 출력. Scratchpad에 대응
▪
LM : 생성 코드 전체를 LM에 넣고 최종 답변을 생성
▪
Direct : few-shot prompting
▪
CoT : chain of thoughts
결과
•
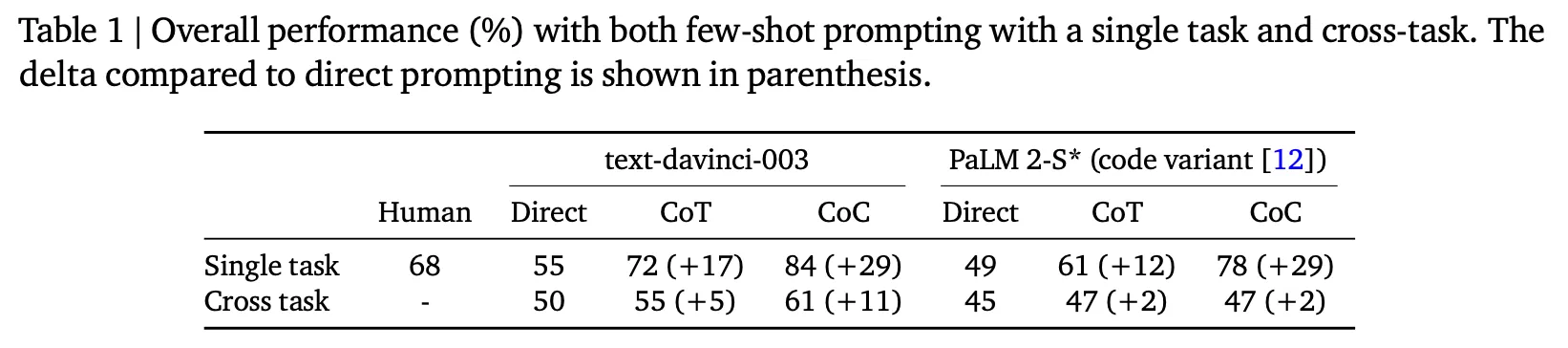
전반적인 성능 측면
◦
CoT보다 훨씬 좋은 성능을 보이며 특히 BBH에서 84%면 SOTA를 달성한 것이라 언급
◦
추가로 동일한 방법론을 적용했을 때 BBH 데이터 세트에서 text-davinci-003이 PaLM 2보다 다 성능이 더 좋음
•
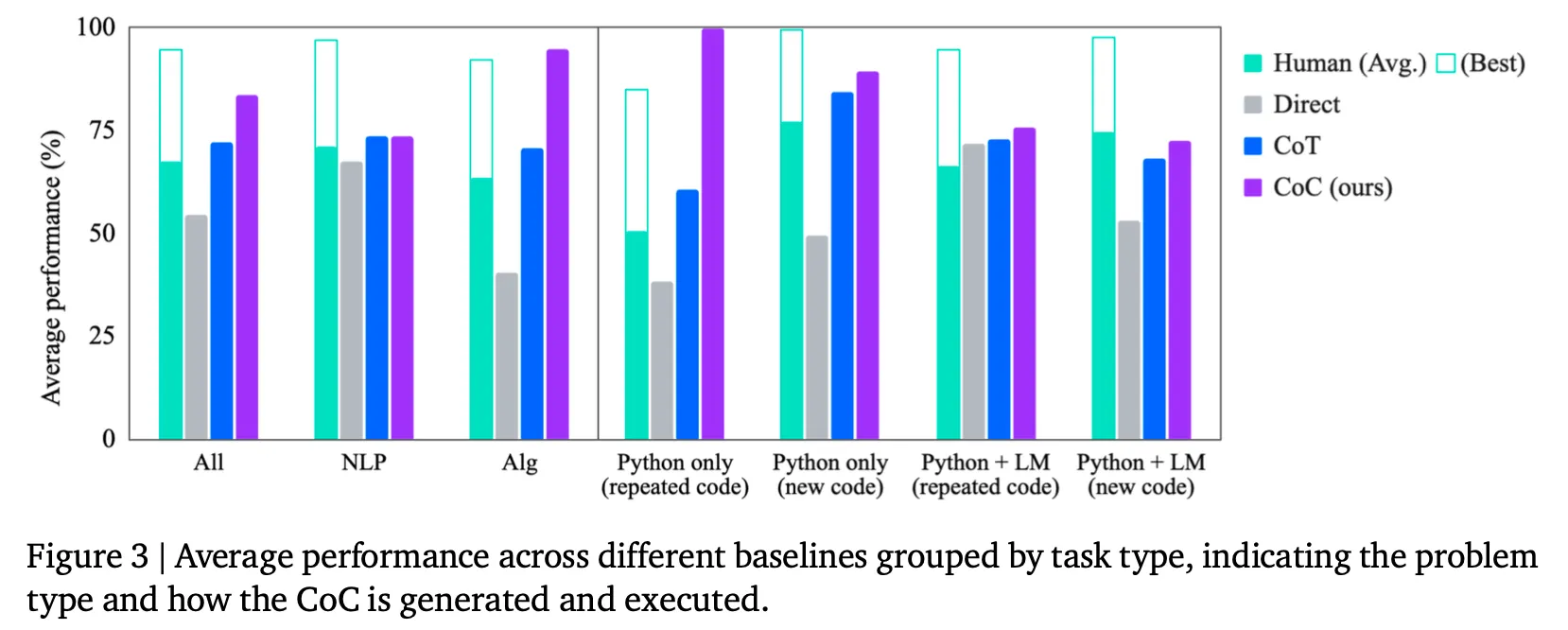
CoC가 잘 동작하는 유형은?
◦
NLP task는 CoT와 비슷한 수준이며 algorithm task에선 특히 강점이 있음
◦
Python으로 fully executable하면서 동일한 코드에서 입력만 바뀌는 task(Python only & repeated code)에선 거의 완벽한 모습을 보이며 나머지 경우도 효과가 줄어들기는 하나 여전히 baseline 대비 뛰어난 결과를 보여줌
•
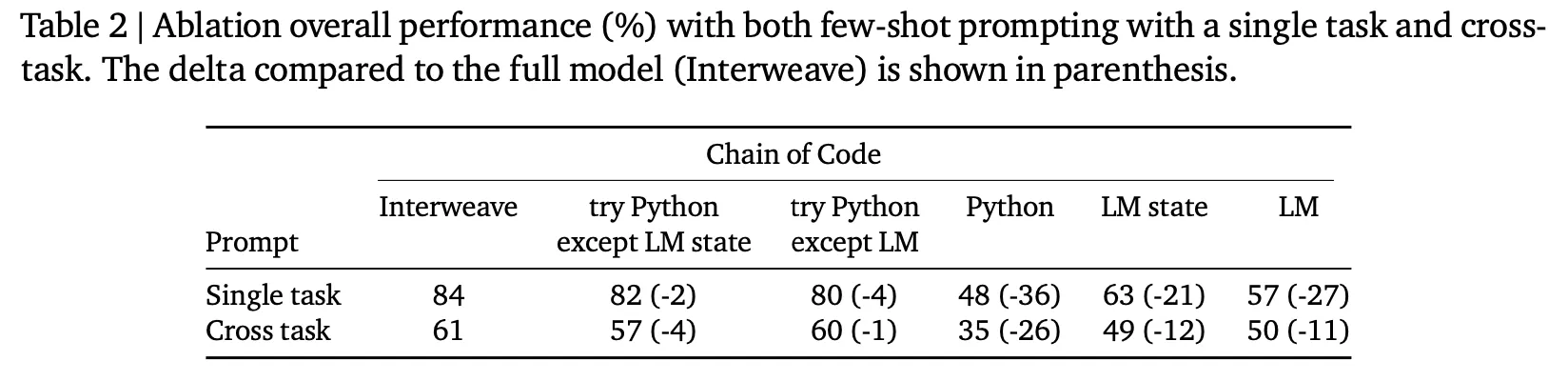
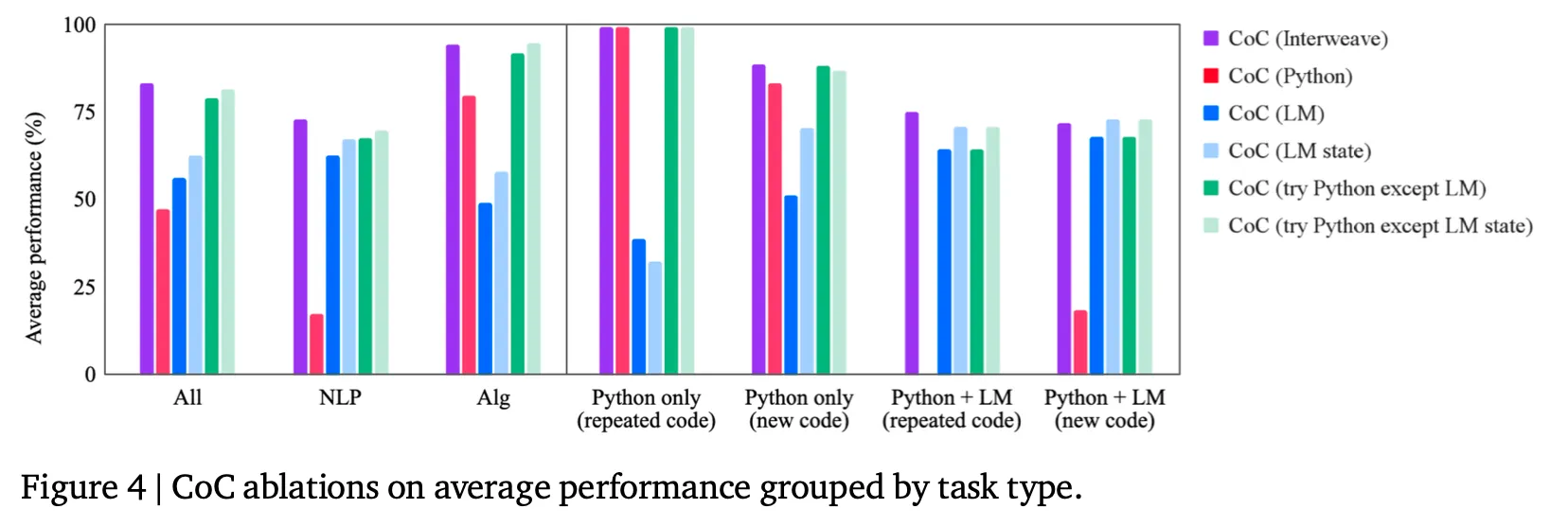
CoC에서 emulator 종류에 따른 성능 비교
◦
제안 방법 중 interweave가 가장 좋으나 다른 2가지 대안 방법들(try Python except LM state, try Python except LM)도 거의 비슷한 성능을 보여줌
•
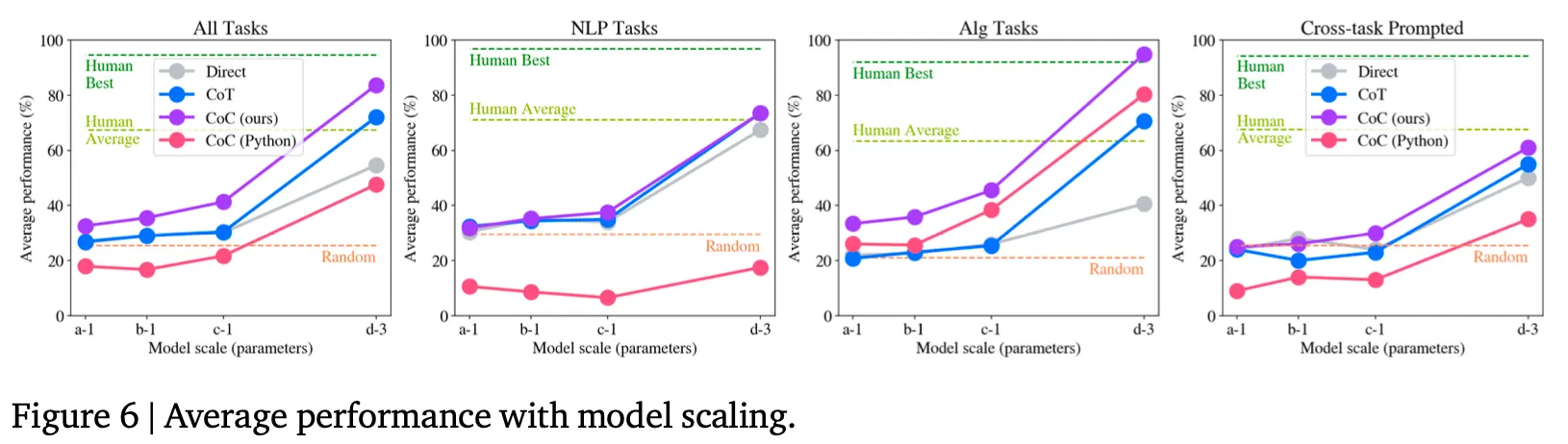
Model 크기에 따른 효과는?
◦
CoT처럼 모델 크기가 클수록 효과가 커짐
◦
단, CoT와 다르게 모델이 작더라도 direct prompting 대비 성능이 비슷하거나 더 좋음. 이는 모델에게 있어서 natural language를 생성하는 것보다는 code를 생성하는 것이 비교적 더 쉬운 과제라는 것을 보여주는 결과라 판단
•
Generalization 능력
◦
Cross task는 풀고자 하는 task에 해당하는 예제를 넣은 것이 아니라 다른 task의 예제를 넣었을 때의 성능. 따라서 여러 task에 대한 일반화 능력을 측정할 수 있는 방법이라 볼 수 있음
◦
위 그림(Table 2의 마지막 줄, Figure 6의 4번째 그래프)에서 보는 바와 같이 비록 cross task에서 CoC의 효과가 크게 감소하긴 하나 여전히 비교 대상 기법 대비 효과가 있음
•
Chat model에서의 효과

◦
InstructGPT(text-davinci-003) vs ChatGPT(3.5) vs ChatGPT(4)
◦
각 방법론에 맞는 instruction을 chat interface에 입력으로 넣음 (e.g., “direct answer”, “step-by-step”, “write python code to help solve the problem, if it’s helpful”)
◦
ChatGPT의 경우 Direct, CoT, CoC(Python)과 CoC(LM)만 적용하여 실험
◦
ChatGPT에서도 여러 턴에 걸쳐서 CoC(try Python except LM) 같은 방법은 적용이 가능할 것 같은데 이 부분은 별도로 실험하지 않았음
논의사항
•
GPT-3의 공개는 LLM이 parameter update 없이 간단한 prompt의 입력만으로 다양한 task를 수행할 수 있는 가능성을 보여주었다면, InstructGPT 및 이후 모델에서는 LLM의 이해 및 추론 능력이 비약적으로 향상된 모습을 보여주었음
•
그 원인으로는 instruction following 데이터와 더불어 대량의 code 를 학습한 것이 중요한 요소로 알려져 있음
•
이유를 추측해 보자면 code란 어떤 문제를 해결하기 위하여 정형화된 형태로 논리 구조를 표현하는 수단이므로 LLM이 다양한 추론 과정에서 "code"의 도움을 받아 관계를 도출하거나 계산을 수행하고, 다음 action을 예측하는 등의 모습을 보여주기 때문이라 추측
•
기존에도 LLM이 명시적으로 code를 생성하고 reasoning에 활용한 사례는 있었음. 그렇지만 이 논문은 생성 코드에 대해 code interpreter와 LLM interpreter 양쪽의 능력을 모두 leverage하는 방법론을 제시한 부분이 key idea라 생각
•
LLM의 능력을 극대화하기 위해서는 coding 능력 및 언어 이해 능력을 모두 최대한 활용해야 한다고 생각하며 그런 방향에서 흥미로운 방향의 연구라 생각