
.png&blockId=d316aec1-9268-4da2-84c7-2f7166327ff5&width=3600)
이번 블로그는 데이터 큐레이션에 대한 내용을 다룬다. 데이터 큐레이션은 데이터 구축과 생성뿐만 아니라 데이터의 활용 가치를 높이는 모든 활동을 포함한다.
.png&blockId=216d69b5-308d-4ae1-b5bf-9f85db89e684)
1. 말뭉치 구축의 변화 양상
를 통해서 1차 한국어 데이터 큐레이션을 진행하던 시기인 2019에는 구문분석 데이터와 유사문장, 병렬 코퍼스 등이 다수였다.
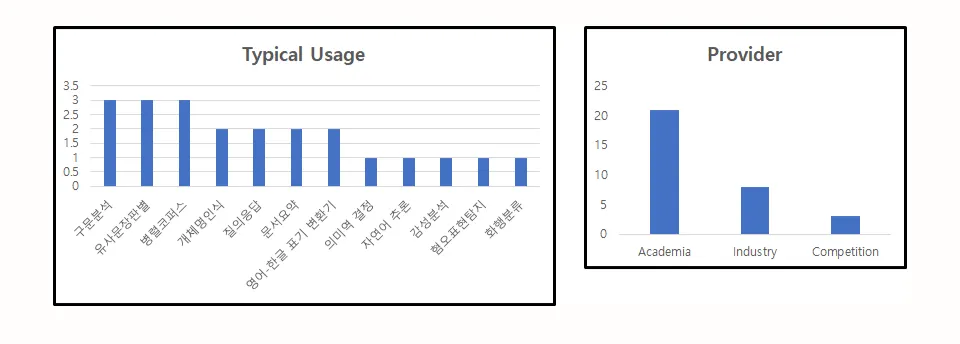
<그림1> 데이터의 일반적 사용과 제공 기관
이는 다음 이미지와 같이 형태소나 문장을 분석하여 그 특성을 추출하여 필요한 정보를 처리하는 데이터가 주로 구축되었기 때문이다.
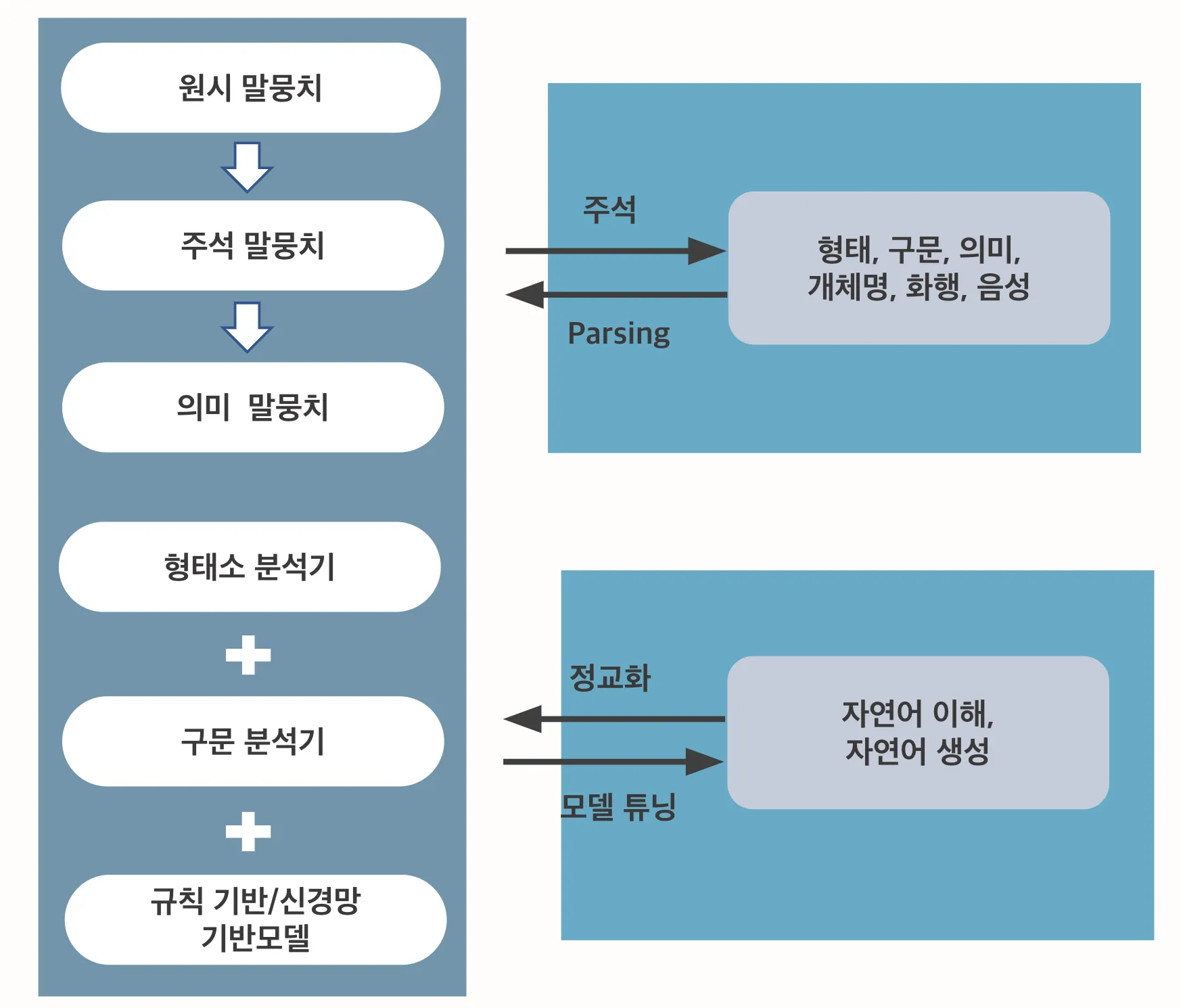
<그림2> 텍스트 데이터의 분석 방법과 자연어 처리 과제 세분화
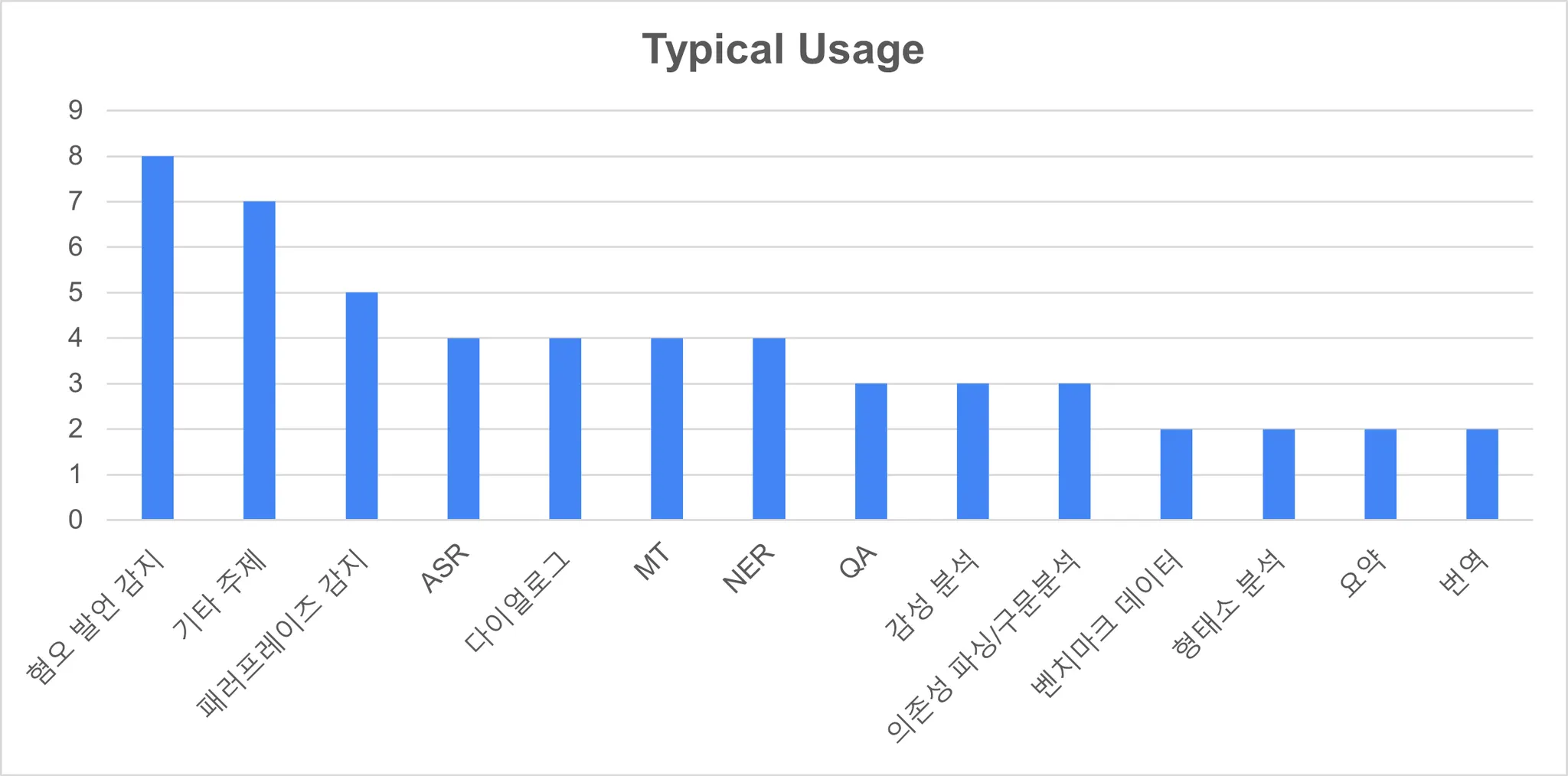
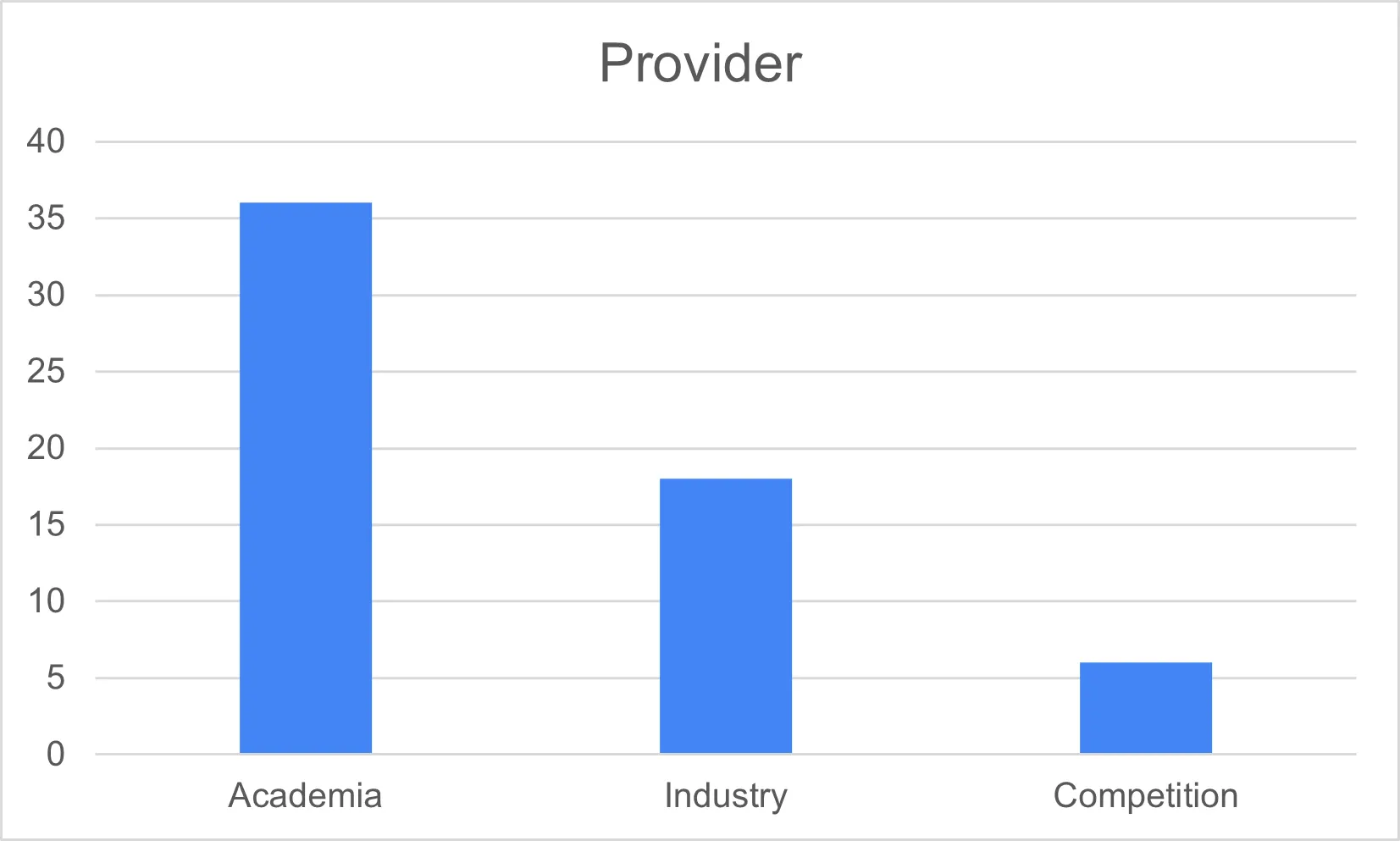
2020년부터 현재(2023년)까지는 혐오 표현과 함께 다양한 주제(기타 주제에 포함됨)의 데이터가 증가하였다. 전반적으로 의미 분류와 관련된 데이터가 연구와 산업에서 많이 사용된 것을 확인할 수 있다.
<그림3> 데이터의 일반적 사용과 제공 기관
이러한 변화를 반영하여 시기에 따라 많이 구축된 데이터를 하나의 이미지로 나타내면 다음과 같다.

<그림4> From Cho et al.(2023): Diachronic Overview of (Open) Korean Corpora (1990s – 2023)
이와 같은 변화가 있게 된 원인으로 word2vec 이전에는 구문이나 형태 등에서 얻은 정보를 자연어처리에서 주로 사용했다면 word2vec 이후에는 수집된 데이터를 정제하면서 정답 세트를 통해 모델을 교육하는 방식으로 모델링이 진행되었기 때문이다.

<그림5> 자연어처리의 일반적 과정
즉, word2vec 이전에는 다음과 같이 구문을 분석하는 연구들이 많았고 지금까지도 다양한 연구들이 진행되고 있다.
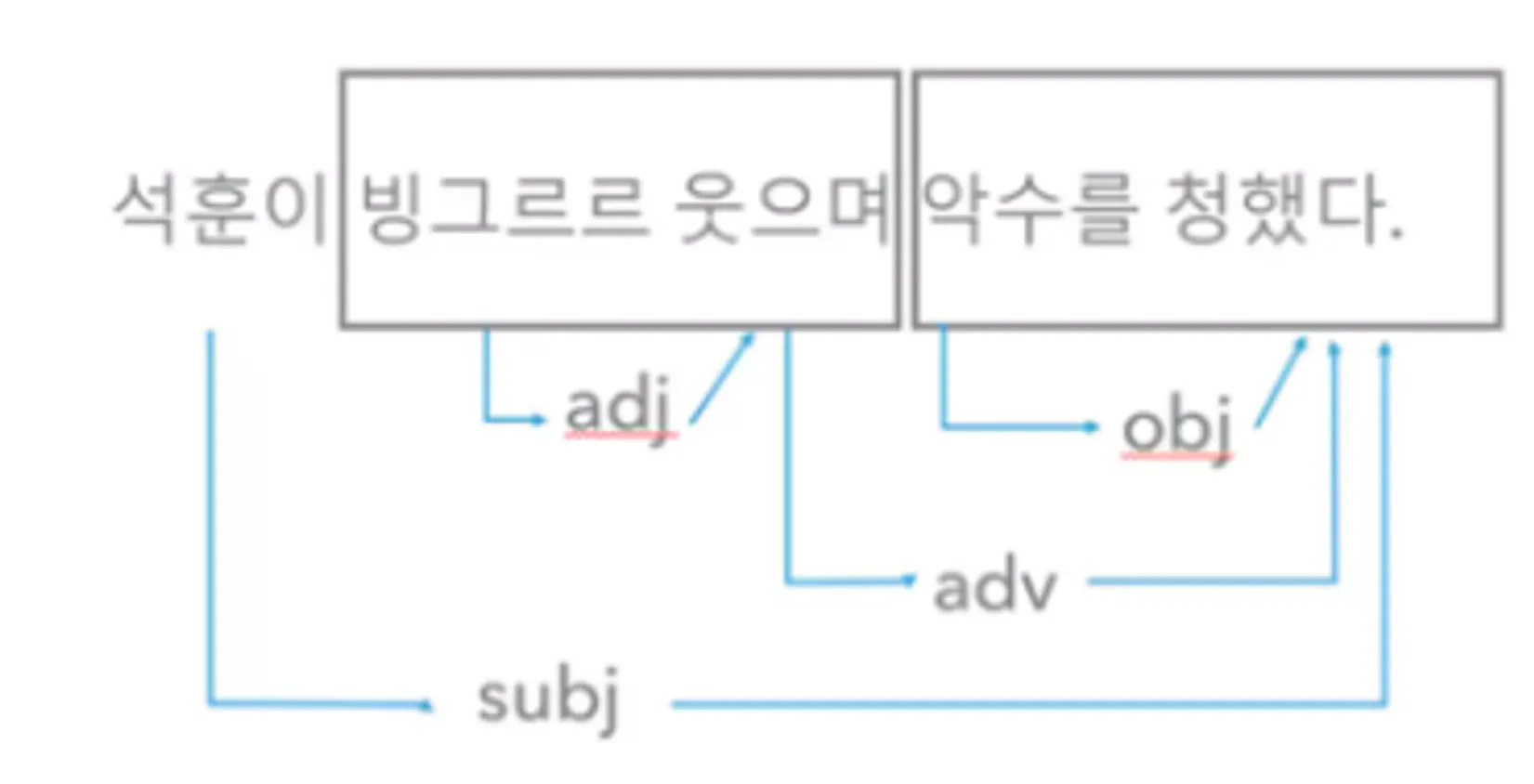
<그림6>박진호(2004)에서 인용, subj 주어, obj 목적어, adj 관형어, adv부사어
word2vec 이후 벡터 공간상에서 단어들 간의 관계를 파악할 수 있게 되면서 네이버 영화평 데이터와 같이 많은 양의 데이터에 긍정 감성이면 1, 부정 감성이면 0이라는 레이블을 붙이고 BERT와 같은 모델이 잘 학습하는지를 확인하는 과정이 자연어처리 분야에서 주를 이루었다.
$ head ratings_train.txt
id document label
9976970 아 더빙.. 진짜 짜증나네요 목소리 0
3819312 흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나 1
10265843 너무재밓었다그래서보는것을추천한다 0
9045019 교도소 이야기구먼 ..솔직히 재미는 없다..평점 조정 0
6483659 사이몬페그의 익살스런 연기가 돋보였던 영화!스파이더맨에서 늙어보이기만 했던 커스틴 던스트가 너무나도 이뻐보였다 1
5403919 막 걸음마 뗀 3세부터 초등학교 1학년생인 8살용영화.ㅋㅋㅋ...별반개도 아까움. 0
JavaScript
복사
네이버 영화평 데이터 일부 (https://github.com/e9t/nsmc)
2. 말뭉치 구축의 저변 확대
2020년을 전후하여 나타난 두드러진 변화 중에 하나는 국가뿐만 아니라 기업 및 기관들도 데이터 구축에 적극적으로 참여하였다는 것이다. 국립국어원(모두의 말뭉치), 정보화 진흥원(AI HUB), 네이버(NLP Challenge), 업스테이지(Klue benchmark), 스마일 게이트 AI(혐오 표현 데이터 등) 등이 그 예이다. 구체적인 데이터에 대한 설명은  Open-korean-corpora 에서 확인할 수 있다.
Open-korean-corpora 에서 확인할 수 있다.
말뭉치이름 | 발행연도 | 원시 말뭉치 / 주석 말뭉치 | 분량 | 예 |
일상대화 | 2020 (버전 1.0) | raw | 파일 2,232개, 총 317MB | 반려동물을 키우고 계신가요 |
어휘의미분석 | 2020 (버전 1.0) | tagged | 2019년도에 구축된 300만 어절 규모(문어 200만, 구어 100만 어절)와 메신저 대화 말뭉치 (92만 어절)를 대상으로 형태 분석과 어휘 의미(체언류와 용언류)를 분석한 말뭉치 | "word": "제주",
"sense_id": 8,
"pos": "NNP",
"begin": 1,
"end": 3,
"word_id": 1 |
어휘관계 | 2020 (버전 1.0) | tagged | 우리말샘 사전 기반 어휘 관계 기초 자료 20만 쌍(비슷한말 60,000쌍, 반대말 10,000쌍, 상위어 70,000쌍, 하위어 60,000쌍 | 가가대소 방소 유의어 |
문법성판단 | 2020 (버전 1.0) | tagged | 총 19,940개 문장(문법적 문장 9,970개 문장, 비문법적 문장, 파일 4개, 총 3.19MB | 높은 달이 떴다. 4.981(mean)
달이 뜸이 높았다. 2.223(mean) |
개체명 | 2020 (버전 1.0) | tagged | 총 300만 어절(문어 200만 어절, 구어 100만 어절), 파일 2개, 총 909MB | "form": "멕시코",
"label": "LC" |
유사문장 | 2020 (버전 1.0) | tagged | 179,589개 문장, 파일 1개, 총 42.5MB | "경기 성남시 판교신도시에서 이달 분양하는 중대형 아파트의 3.3m²당 분양가가 1500만 원 후반대로 결정될 것으로 보이는데 이는 2006년보다 200만 원 정도 싼 가격이다." |
웹 | 2020 (버전 1.0) | raw | 블로그 11,521건
게시판 9,089건
누리 소통망 1,989,656건
-리뷰: 96,810건 | "title": "비타민 사기 진짜 어려워..",
"form": "오메가3와 비타민C, 달맞이꽃종자유 등을 사려고 몇 시간을 검색하며 공부했다. 그 결과 오염되지 않은 바다에서 잡힌 먹이사슬의 하단에 있는 생선이 좋다고 들었는데(덩치가 커지면 중금속 오염이 심하다고 함) |
신문 | 2020 (버전 1.0) | raw | 기사 3,536,491건(2009년부터 2018년까지 10년 동안 생산된 신문 기사 연 1억여 어절), 파일 363개, 총 15.6GB | 2008년의 마지막 새벽, 언론의 카메라는 서울 여의도를 향했다. 방송법 등 주
요쟁점 법안이 상정될 국회 본회의장을 두고 여야 의원들의 전쟁을 기다리고 있었던 것 |
문어 | 2020 (버전 1.0) | raw | 책, 잡지, 보고서 등 저작권 문제가 해결된 저작물 10,045종의 문어 원시 말뭉치, 파일 10,045개, 총 4.24GB | 01범보다 무서운 곶감 |
구어 | 2020 (버전 1.0) | raw | 공적 독백 2,490건
공적 대화 19,104건
준구어-대본 4,102건(드라마 ), 파일 25,696개, 총 6.73GB | "title": "EBS 정오뉴스 2018년 1월",
"author": "박민영 외",
"publisher": "EBS",
"date": "20180000",
"topic": "도서관의 변신, 메이커 스페이스에 대한 기사"
"form": "미국의 공공도서관들이 새로운 모습으로 변신하고 있습니다.", |
문서요약 | 2020 (버전 1.0) | tagged | 신문 말뭉치에서 추출한 기사 4,389건이 대상 말뭉치에서 기사 추출 주제 및 요약 작성 문장 13,167개 | 기사 제목, 부제목-1문장, 기사, 기사 요약-2문장 이상 |
구문 | 2020 (버전 1.0) | tagged | 총 300만 어절
문어 200만 어절
구어 200만 어절, 문어 1.07GB, 구어 583MB | "word_form": "판교신도시에서",
"head": 5,
"label": "NP_AJT" |
형태분석 | 2020 (버전 1.0) | tagged | 300만 어절(문어 200만 어절, 구어 100만 어절) 파일 2개, 총 2.31GB | "form": "제주",
"label": "NNP" |
추론확신성 | 2020 | tagged | 신문, 준구어 말뭉치에서 대상 담화 추출, 파일 1개, 총 272KB | 변화에 대한 적응이 항상
성공적일 수는 없다. 당신을
힘들게 하는 팀원이 당신의
리더십을 키우는 원동력임을
기억한다면, 갈등을 겪을
때마다 당신은 더욱 발전할 수
있는 기회를 |
일상대화 | 2021 | raw | 파일 4,143개, 총 560MB | 아 지금 |
신문 | 2021 | raw | 2020년 생산된 신문 기사 729,280건, 파일 35개, 총 2.95GB | 대통령, 시장 방문만 하지 말고 실천해달라 |
국회회의록 | 2021 | raw | 5,395건(73,478,080어절), : 파일 5,395개, 총 307MB | 회의를 시작하도록 하겠습니다. |
추론확신성 | 2021 | tagged | 문어, 신문, 구어, 대화, 파일 1개, 총 1.457KB | 선행 문장- 대상 문장 P5: 그렇게 바꾸어가면 만성 피로에 걸릴 일이 없거든요.- 후행 문장 |
온라인대화 | 2022 | raw | 총 74,665건(대화 메시지, 파일 47,421개, 총 835MB | "지금 운동하러가려고하는데 반팔 반바지 입으니까 선크림을 발라야돼 |
신문 | 2022 | raw | 2021년 생산된 신문 기사 978,342건, 파일 34개(zip 압축파일 1개, 898MB) | 변이 바이러스’ 잡는 모더나 백신 2000만명 올 2분기 한국 온다 |
메신저 | 2022 | raw | 총 3,836건(대화 메시지 691,535개), 총 212MB | 짜쟌 |
맞춤법교정 | 2022 | tagged | 약 400만 어절, 파일 1개, 총 517MB | 하이하이 |
개체명연결 | 2022 | tagged | 총 약 1,100만 어절(웹 500만, 문어 300만, 구어 300만 어절)
- 국립국어원 개체명 분석 말뭉치 2020(버전 2.1): 500만 어절(웹)
- 국립국어원 개체명 분석 말뭉치 2021(버전 1.0): 600만 어절(문어 300만, 구어 300만 어절), 파일 323개, 총 255MB | "id": 2,
"form": "고대",
"label": "DT_DYNASTY",
"begin": 27,
"end": 29,
"kid": "07070000000019",
"wikiid": "378315",
"URL":
"https://ko.wikipedia.org/wiki/%EA%B3%A0%EC%A0%84_%EA%B3%A
0%EB%8C%80 |
국립국어원 말뭉치 신청 및 활용 방법 등은 아래 영상 링크에서 확인할 수 있다.


3. 사전 학습 모델의 발전과 학습용 데이터 세트
•
SKTBrain/KoBERT : 한국어 위키 문장(5M)
•
klue/roberta : 모두의 말뭉치, 커먼크롤, 나무위키, 네이버 뉴스 크롤링, 국민청원
•
monologg/KoELECTRA :
- v1, v2의 경우 약 14G Corpus (2.6B tokens) (뉴스, 위키, 나무위키)
- v3 모두의 말뭉치 약 20G 추가 (신문, 문어, 구어, 메신저, 웹)
•
ChatGPT 이후는 Llama 등 초거대 언어모델(LLM)이 등장하고 Fine tuning 또는 Instruction tuning 과 같이 튜닝 기술이 주요 연구와 개발 분야에 적용되기 시작하면서 초거대 언어모델에 입력으로 사용될 원시 데이터, 질의 응답, 멀티턴 데이터와 튜닝에 사용할 생성 데이터 및 생성 모델의 평가에 사용할 테스트 데이터들이 주로 구축되었다. 초거대 언어모델과 인스트럭션 데이터는 다음 편에서 다룬다.
참고 자료
•
•
Won Ik Cho, Sangwhan Moon, and Youngsook Song. 2020. Open Korean Corpora: A Practical Report. In Proceedings of Second Workshop for NLP Open Source Software (NLP-OSS), pages 85–93, Online. Association for Computational Linguistics.
•
Won Ik Cho, Sangwhan Moon and Youngsook Song(2023), Revisiting Korean Corpus Studies through Technological Advances, " in Proc. PACLIC 2023
◦
발표 자료 :