

Introduction
•
Prompting은 사람이 초거대 언어 모델(LLM)을 제어하고 소통하는 수단이라 볼 수 있음.
•
사용자는 원하는 결과를 얻기 위하여 어떻게 하면 Prompting을 잘 만들 것인가 하는 일반적인 방법론에 대한 요구는 계속 증가할 것으로 보임
•
최근 생성뿐만 아니라 자연어 이해(문장 분류, 시퀀스 레이블링, 질의응답) 과제에서 프롬프트 튜닝이 미세 튜닝보다 성능이 좋아졌다는 리포트(Lifu Tu et al. (2022)) 와 COT(Jason Wei et al. (2022)) 등의 프롬프트 방법론, 그리고 멀티모달에서의 응용(Andy Zeng et al. (2022)) 등이 선보이기 시작함
•
이 아티클에서는 프롬프팅을 통해 Zero-shot 성능을 향상시키는 흥미로운 두 편의 논문을 다룸

•
리뷰 논문
◦
◦
개요
•
COSP : Consistency-based Self-adaptive Prompting
•
USP : Universal Self-adaptive Prompting
•
Unlabeled data와 black-box LLM을 통하여 zero-shot in-context learning(ICL) 의 성능을 향상시키려는 목표를 가진 서로 다른 방법론 2가지
•
COSP가 주로 reasoning을 타겟팅하고 있는 반면 USP는 classification(CLS), short-form generation(SFG), long-form generation(LFG) 등 조금 더 다양한 task를 타겟팅하고 있음.
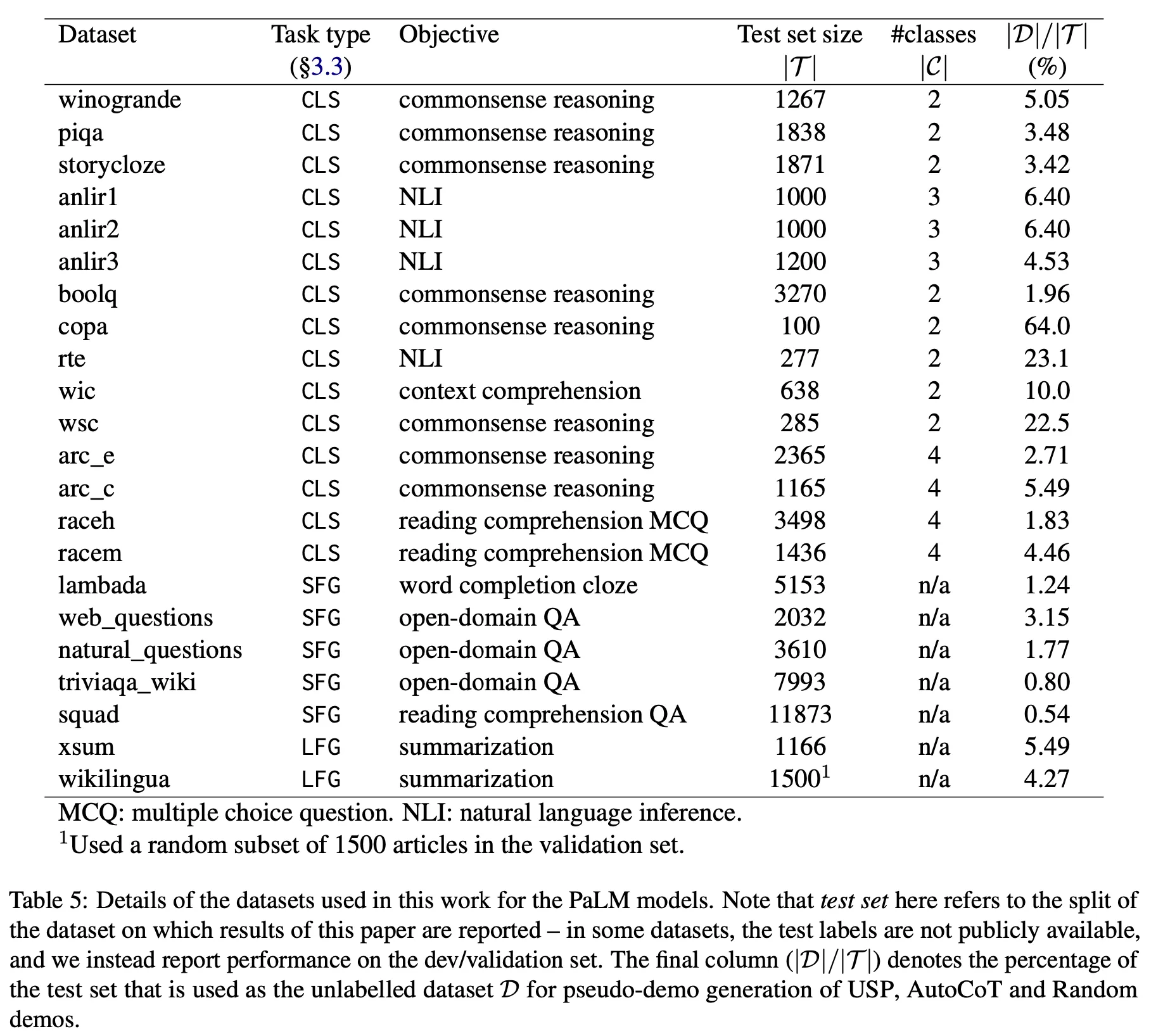
•
방법론 측면에서 high-level의 컨셉은 거의 비슷하나 각 단계별 디테일에서 약간씩 차이가 존재 (COSP 대비 USP가 가진 차이점)
◦
데모 생성용 데이터 세트와 테스트세트를 명확히 분리 (의존성을 없앰)
◦
Task-specific selector 통하여 주어진 과제에 맞는 데이터 선택 전략을 적용
◦
최종 결과에는 majority voting을 적용하지 않고 LLM을 한번만 호출하여 greedy decoding으로 생성
방법론
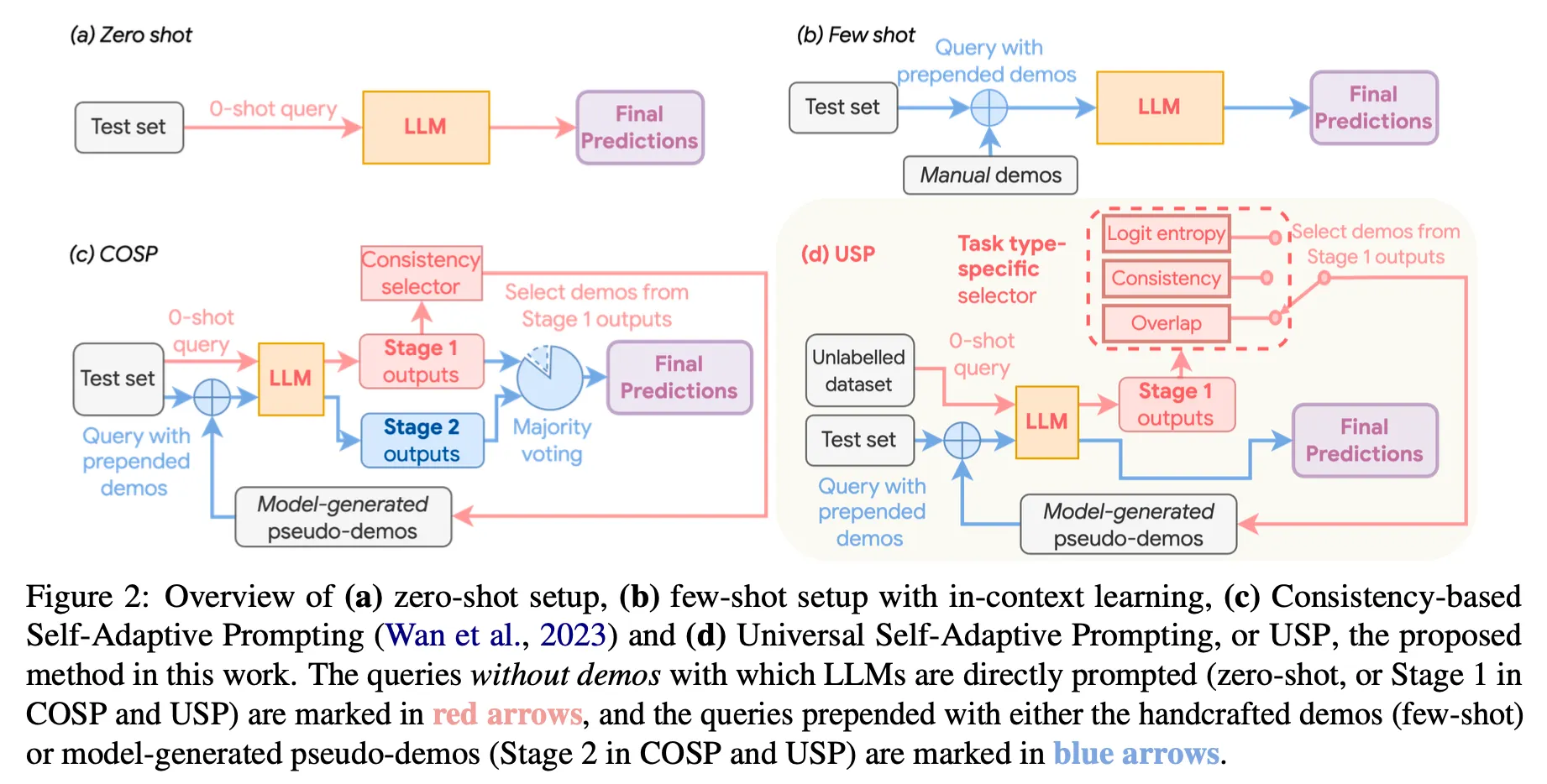
•
Stage 1 : pseudo data 생성 및 선택
◦
Zero-shot 결과 생성
▪
COSP : zero-shot CoT prompt로 LLM을 여러 번 호출하여 1차 생성 결과를 얻음
▪
USP : zero-shot prompt로 classification은 1번, 그 외 generation은 여러 번 호출하여 1차 생성 결과를 얻음
◦
Prompt에 넣을 데모 데이터 선택
▪
기본 전략
•
생성한 예제의 quality를 측정할 수 있는 scoring function 정의 및 score 계산. scoring function의 정의는 각 task별로 다름 (아래 참조)
•
아래 값이 최대가 되는 예시를 Greedy 하게 하나씩 선택하여 원하는 갯수 K개가 될 때까지 추가 (S_c : cosine similarity)
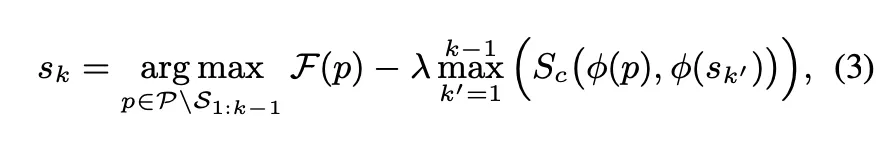
▪
COSP
•
m개의 생성 결과 중 heuristic rule(e.g., 수 관련 문제에 숫자가 존재하지 않음, 너무 짧은 길이 등)을 적용하여 filtering
•
Scoring function : USP와 동일한 scoring function을 사용하기 위하여 원래 COSP논문의 함수에서 부호를 변경. (q_a, q_b : a(b)-th phrases in rationale r)
▪
USP
•
Classification
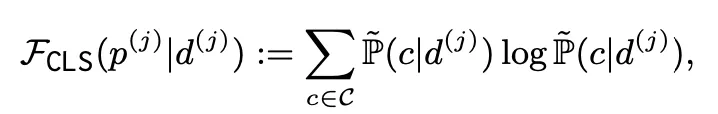
•
Short-form Generation
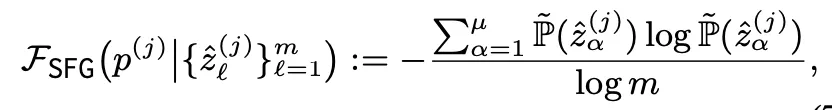
•
Long-form Generation
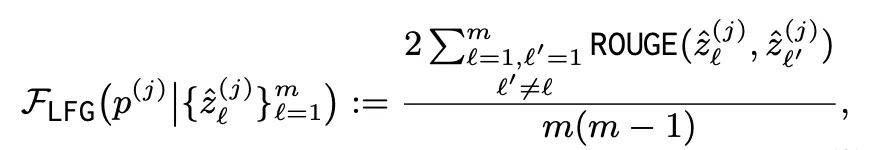
•
Stage 2 : few-shot 결과 생성 & 최종 결과 도출
◦
COSP
▪
최종 선택한 K개의 예제를 기존 prompt에 추가하여 LLM을 호출, 추가로 m가지의 결과를 생성.
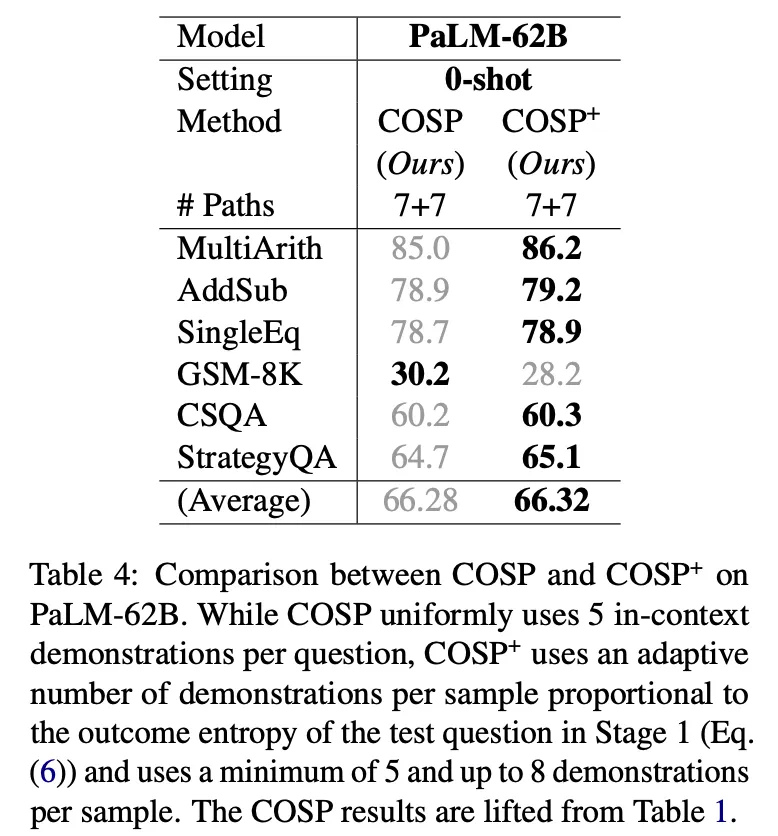
▪
normalized entropy에 따라 동적으로 K값을 조정하는 COSP+도 실험 : entropy가 높다는 것은 그만큼 더 어려운 문제일 가능성이 높으므로 더 많은 예제를 선택. 추가적인 성능 향상이 있었음
▪
majority voting으로 최종 결과 선택
◦
USP
▪
LLM을 한번만 호출하여 greedy decoding으로 생성
결론
•
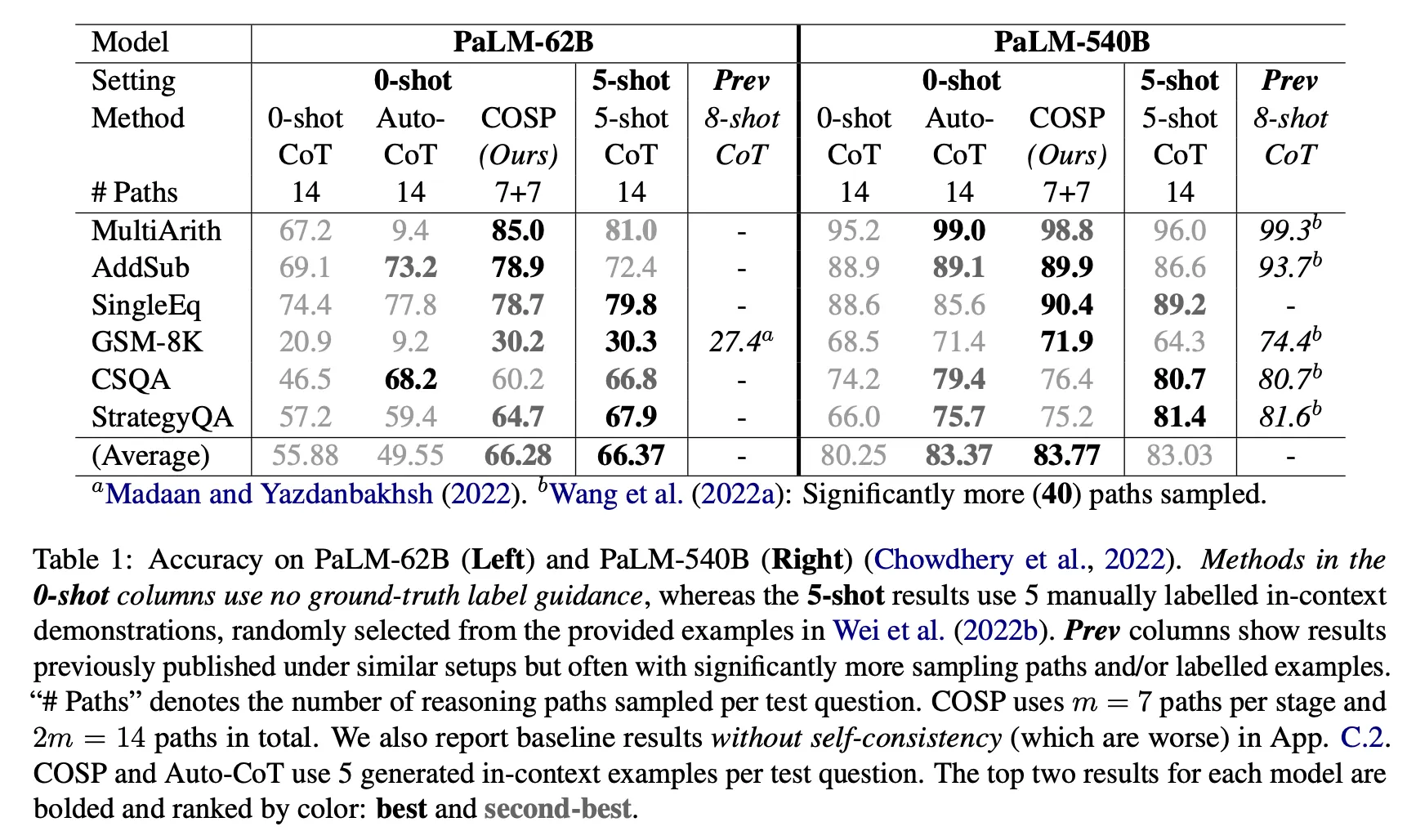
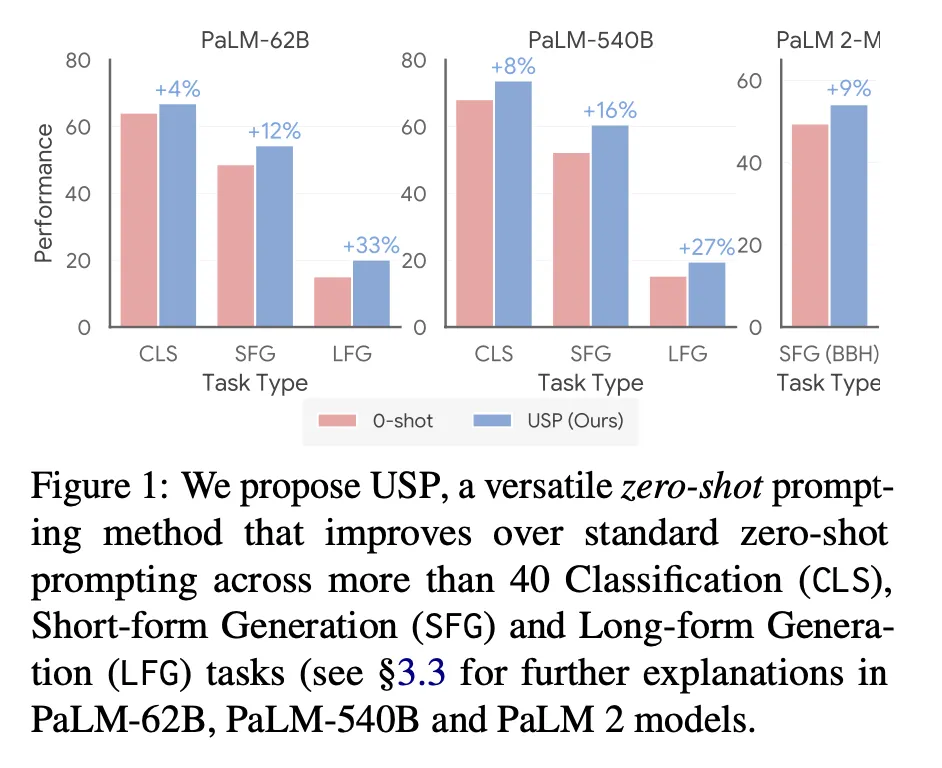
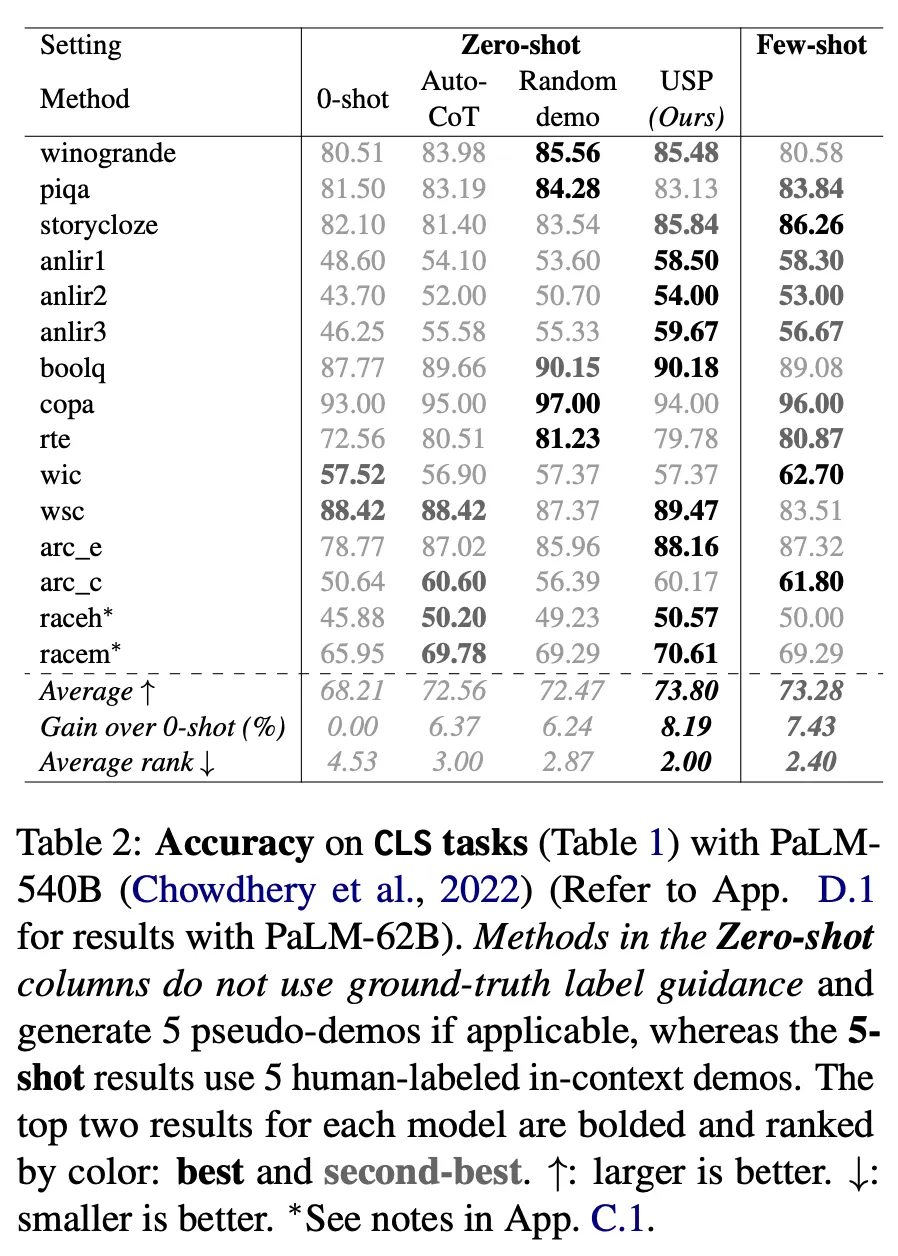
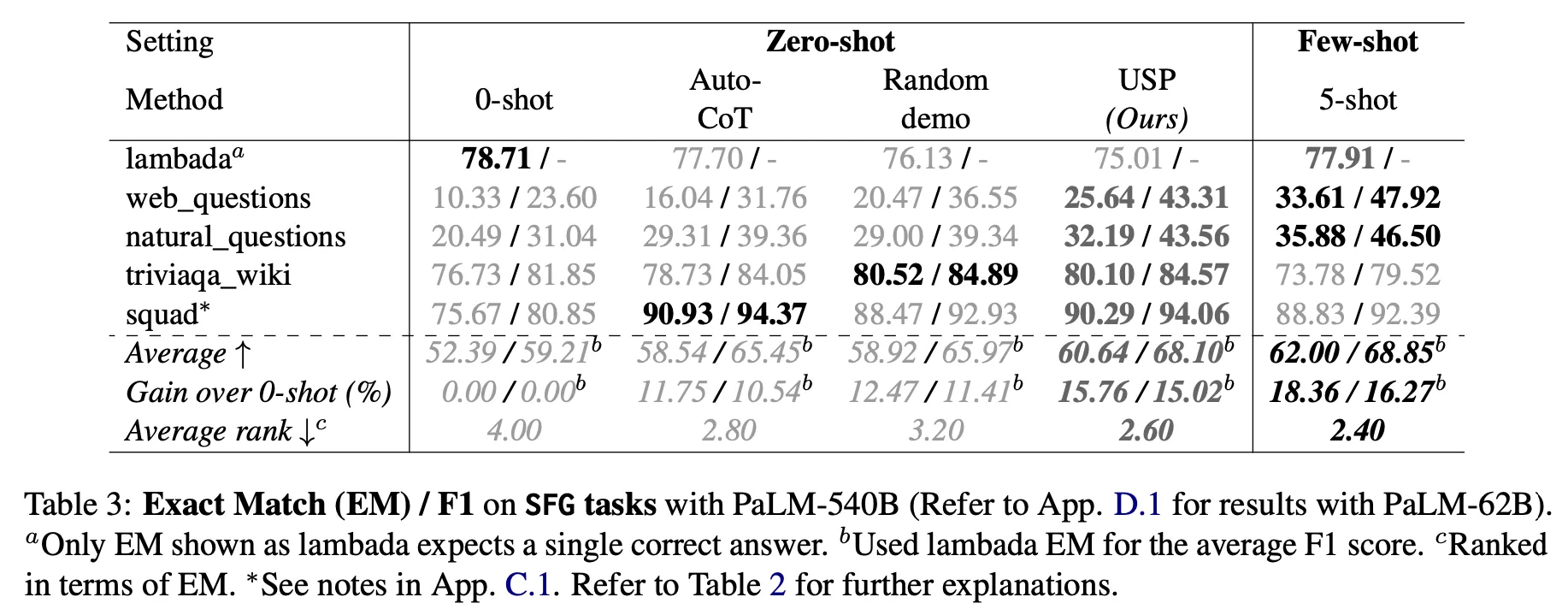
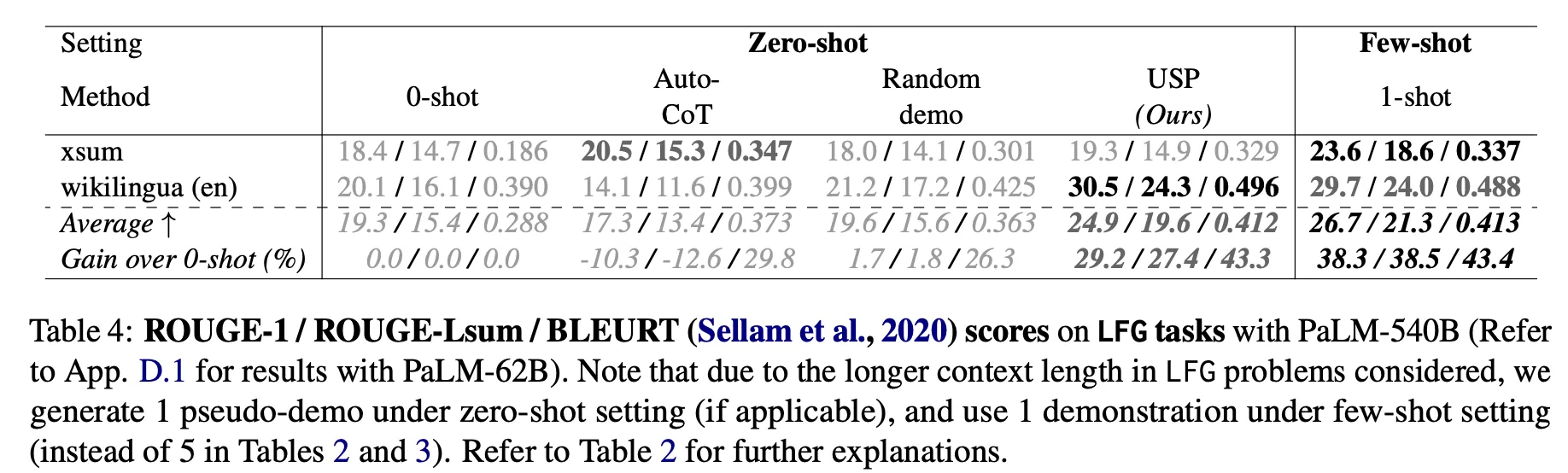
Zero-shot 대비 성능 향상이 관찰됨
•
COSP on 6 reasoning tasks : 절대값이 >10% (PaLM-62B), >3%(PaLM-540B) 향상
•
USP on 40 NLG, NLU tasks : 상대값으로 4-33% (PaLM-62B), 8-27% (PaLM-540B) 향상
논의 사항
•
동일 저자가 거의 비슷한 시기에 발표한 같은 목적을 달성하기 위한 2가지 방법론.
•
Labeled data가 전혀 없는 상황에서 모델 성능을 높일 수 있는 흥미로운 방법론. 그렇지만 완전한 zero-shot ICL 방법론이라기 보다는 데이터 및 프롬프트 생성 방법론의 관점으로 적용해 보는 것이 실용적으로 더 유용하다고 판단
◦
사용할 수 있는 labeled 데이터가 전혀 없고 LLM을 black-box API로만 사용할 수 있는 상황을 가정하여 Sionic AI와 같은 스타트업을 포함하여 거의 대부분의 상황에 적용이 가능한 방법론
◦
한번 결과를 얻을 때마다 zero-shot 으로 여러번 생성하고, few-shot으로 최종 생성하는 2단계를 거쳐야 하기 때문에 만약 이 방법론 그대로 inference를 구성하기에는 비용 및 응답 속도 측면에서 이슈가 존재.
◦
따라서 첫 번째 pseudo data를 생성하고 선택하는 Stage 1의 경우는 실시간 inference 때가 아니라 프롬프트를 설계하는 단계에서 작업하고 실제 inference는 Stage 2의 호출 1번만 발생하는 방식으로 활용 가능. COSP에서도 마지막 majority voting 단계를 few-shot에 대해서만 하면 위와 같은 방식으로 Stage를 분리하여 구현 가능
더 읽을 거리
Lifu Tu, Caiming Xiong and Yingbo Zhou(2022), “Prompt-Tuning Can Be Much Better Than Fine-Tuning on Cross-lingual Understanding With Multilingual Language Models”, Conference on Empirical Methods in Natural Language Processing.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, Denny Zhou(2022), “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”
Andy Zeng, Maria Attarian, Brian Ichter, Krzysztof Choromanski, Adrian Wong, Stefan Welker, Federico Tombari, Aveek Purohit, Michael Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, Pete Florence(2022), “Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language”