


도입
•
LLM이 외부의 지식이나 정보를 동적으로 활용하는 방법으로 RAG(Retrieval-Augmented Generation) framework가 매우 각광 받고 있음
•
Embedding model은 retrieval의 성능을 결정하는 가장 중요한 요소로 embedding model의 성능을 측정하기 위한 대규모 벤치마크 중 대표적인 것으로 MTEB(Massive Text Embedding Benchmark)이 존재
(이전 아티클 참고 : MTEB 상위권 방법론들)
•
이 아티클에서는 최근 MTEB에서 최고의 성능을 달성한 방법론에 대하여 소개함
•
개요
•
한줄 요약 : GPT-4를 활용하여 학습 데이터를 생성하고 그것으로 Mistral-7b 모델을 tuning 하여 MTEB에서 SOTA 성능을 달성
•
다국어 데이터도 생성하여 총 93개 언어에 대한 embedding 능력을 학습
•
DeepNet, LongNet, E5, Kosmos 시리즈 등 꽤 실용적인 연구를 많이 하는 그룹에서 발표한 논문
방법론 상세
•
Data Generation

◦
다양한 종류의 데이터를 생성하기 위하여 embedding task를 크게 몇 개의 그룹으로 나눈 후 각 그룹별로 다른 prompt template을 활용하여 데이터를 생성
◦
Asymmetric tasks
▪
Query와 document가 의미상 연관은 있지만 유사한 내용은 아닌 경우(질문-답변, 검색 query-관련 문서 등)
▪
이 경우는 short-short, short-long, long-short, long-long 4가지 subgroup으로 나눔
▪
위 그림 1에서와 같이 먼저 task의 instruction을 LLM이 생성하게 한 후 생성한 task instruction에 대하여 query 및 document를 생성하는 2단계로 진행
◦
Symmetric tasks
▪
Query와 document가 유사한 의미를 가지는 경우
▪
STS와 bitext retrieval 2가지 subgroup으로 나눔
▪
이 경우는 task instruction이 직관적이므로 사람이 직접 생성한 prompt를 통하여 바로 query 및 document를 생성 (e.g., “Retrieve semantically similar text.”)
◦
프롬프트에서 query_length, query_type, num_words 등 주요 feature들에 대하여 여러 개의 옵션을 사전에 만든 후 생성할 때마다 random sampling하여 최대한 다양한 데이터를 생성하였음
•
모델
◦
Backbone : Mistral-7b
◦
LoRA with rank=16, DeepSpeed ZeRO-3
◦
seq_length=512, batch_size=2048, LR=10^-4, linear decay, weight decay=0.1
◦
Query에 task instruction 을 합친 형태를 입력으로 사용함
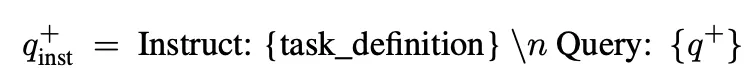
◦
Query와 document 입력 맨 뒤에 [EOS] token을 삽입한 후 이 토큰에 대한 embedding을 각각의 embedding vector()로 사용.
◦
입력 query와 positive document가 유사한 embedding이 되도록 InfoNCE loss로 학습. 여기서 은 in-batch negative 및 hard negative 모두 포함한 집합
◦
학습은 1 epoch 진행. V100 32장으로 18시간 소요
◦
MTEB evaluation은 document에 대한 encoding에 시간이 많이 걸려서 V100 8장으로 3일 소요
결과
•
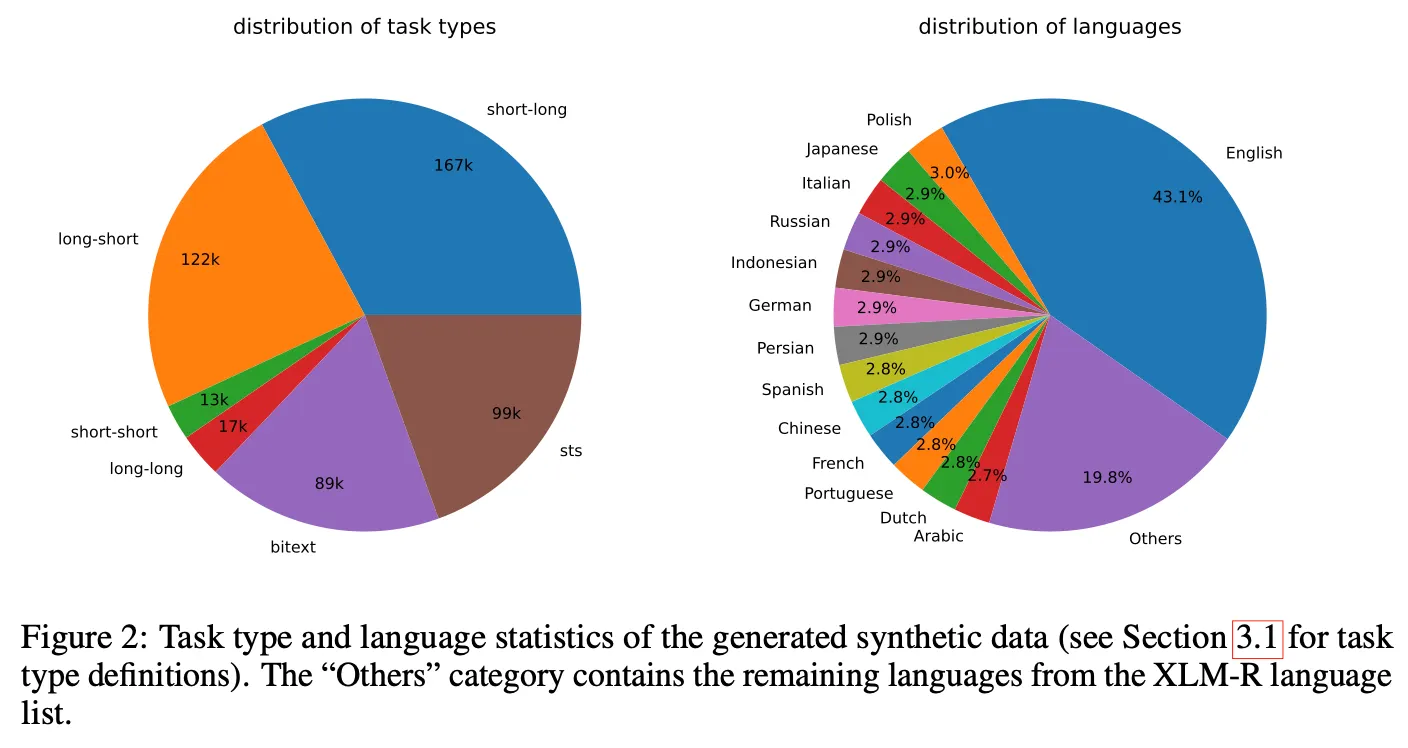
생성 데이터 유형 및 언어 종류
◦
총 150k개의 task로부터 500k개의 데이터를 생성. 데이터 생성에 180M 토큰 사용
◦
기존 labeled 데이터도 학습에 활용(아래 표에서 full data). 다음의 데이터로부터 샘플링하여 위에서 생성한 데이터 포함 총 1.8M 데이터를 수집
▪
ELI5, HotpotQA, FEVER, MIRACL, MS-MARCO, NQ, NLI, SQuAD, TriviaQA, Quora Duplicate Questions, MrTyDi, DuReader, T2Ranking
◦
Task 종류는 short-long 이 가장 많고 long-short, STS 등의 순서
◦
언어는 (당연하게도) 영어가 가장 많음
◦
GPT-3.5-turbo로 약 25%, GPT-4로 75%를 생성. GPT-3.5-turbo는 지시문이나 가이드라인을 명확히 따르지 않는 경우가 일부 있으나 전체 품질은 나쁘지 않아서 학습 데이터에 포함시킴
•
실험 결과
◦
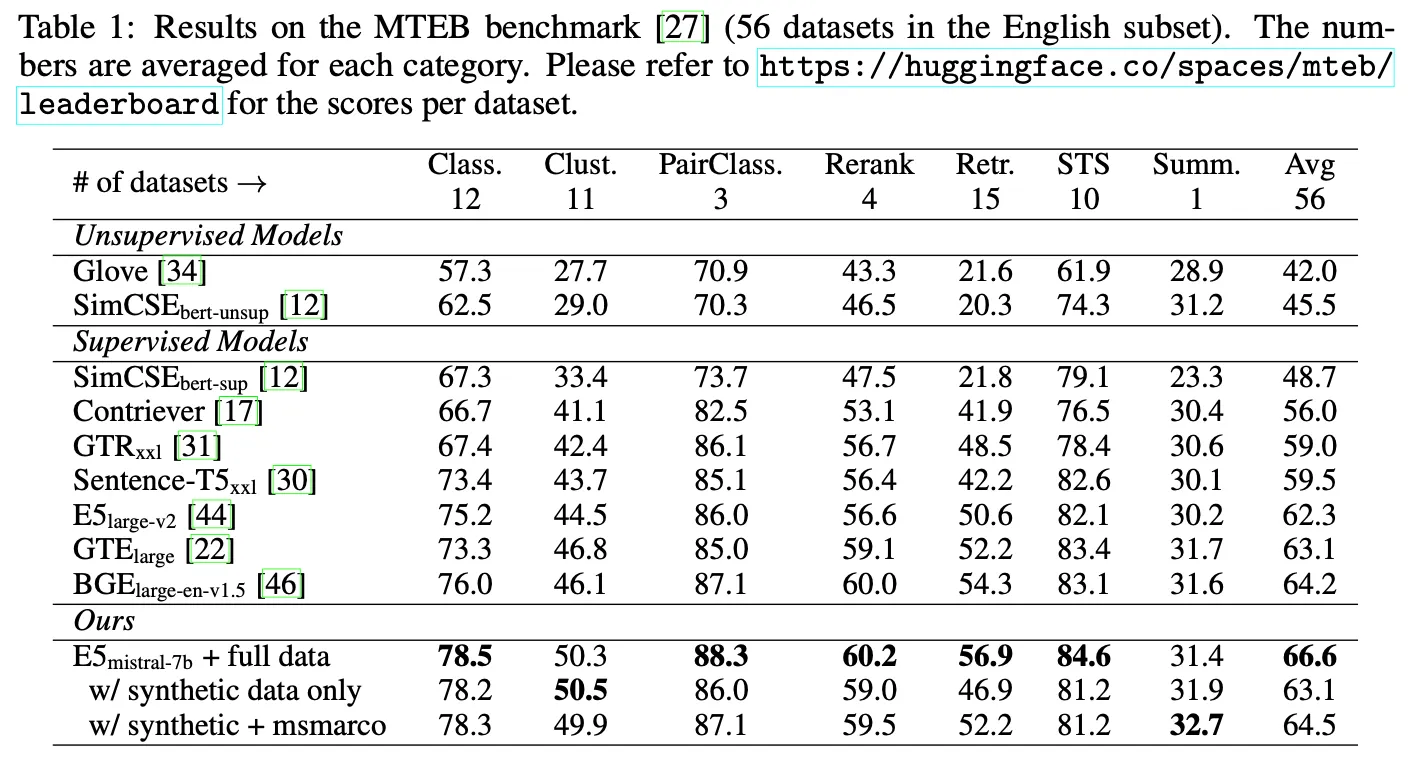
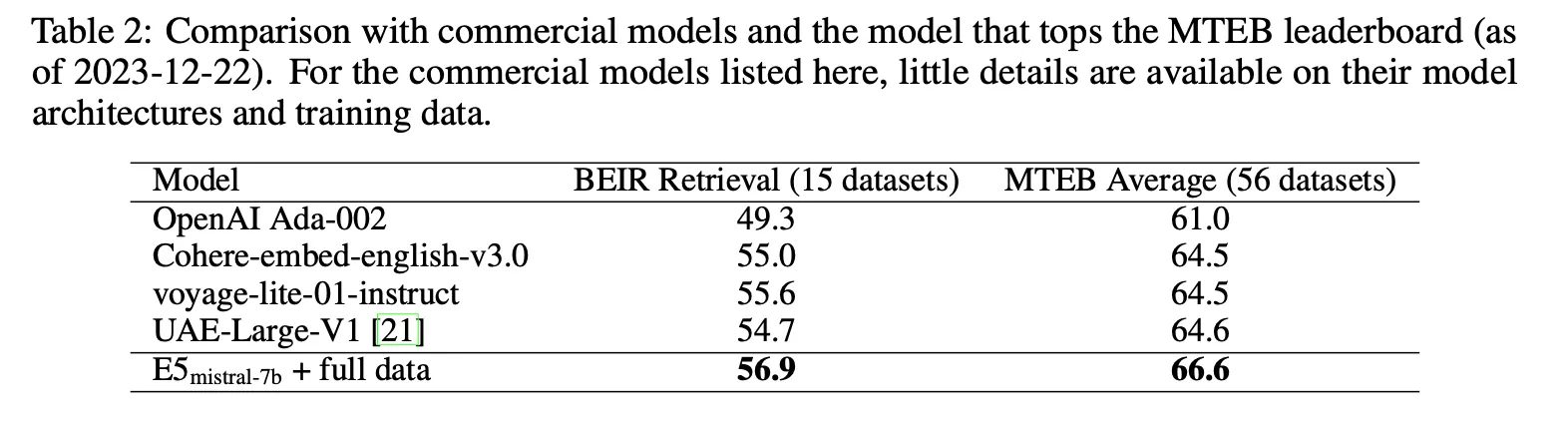
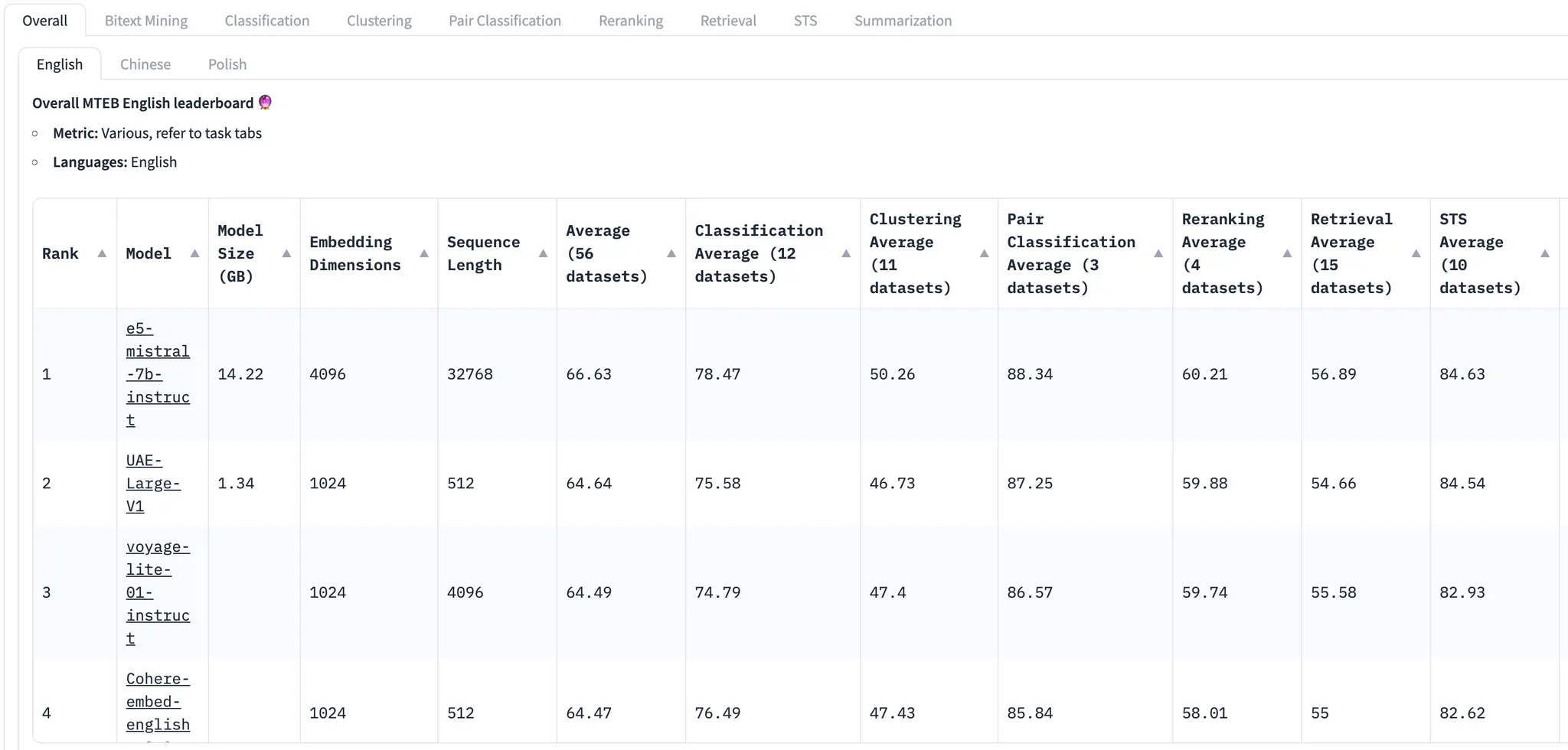
전체 데이터를 모두 학습에 활용한 모델이 MTEB에서 66.6점으로 SOTA를 달성.
◦
생성 데이터로만 학습한 경우에도 63.1점으로 괜찮은 성능을 얻음
▪
OpenAI보다는 높고 Cohere보다는 낮은 수준
▪
23년 8월경까지 SOTA였던 GTE-large와 비슷한 점수
◦
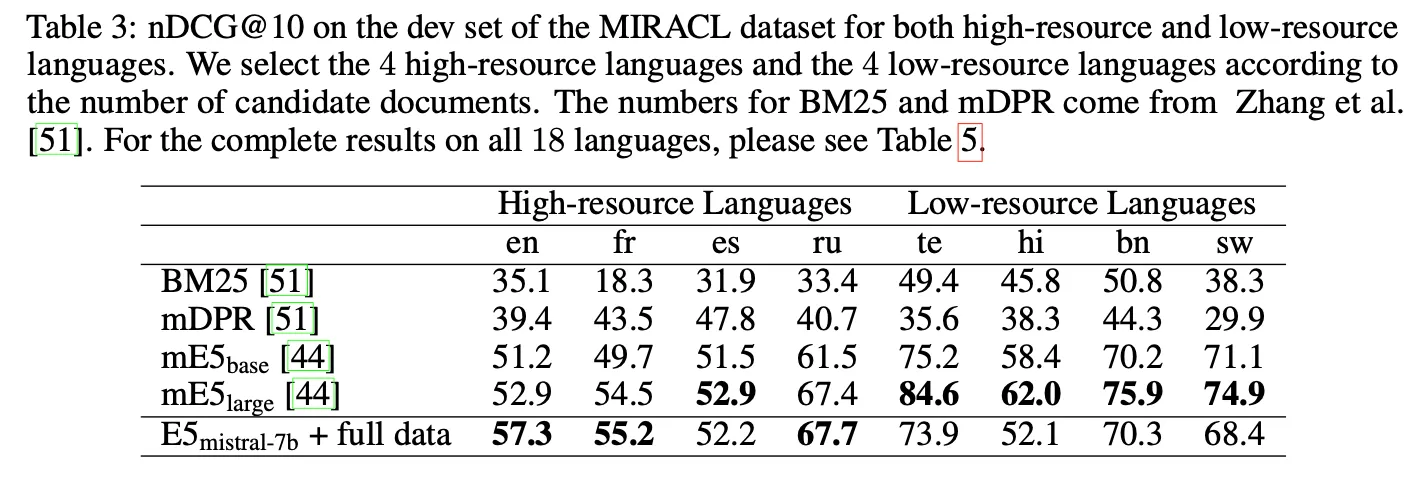
영어 이외에도 프랑스어, 러시아어 등에서는 꽤 좋은 성능을 보이나 low-resource 언어에서는 비교적 낮음. Mistral-7B 자체가 영어 위주로 학습되어서 그런 것으로 예상
◦
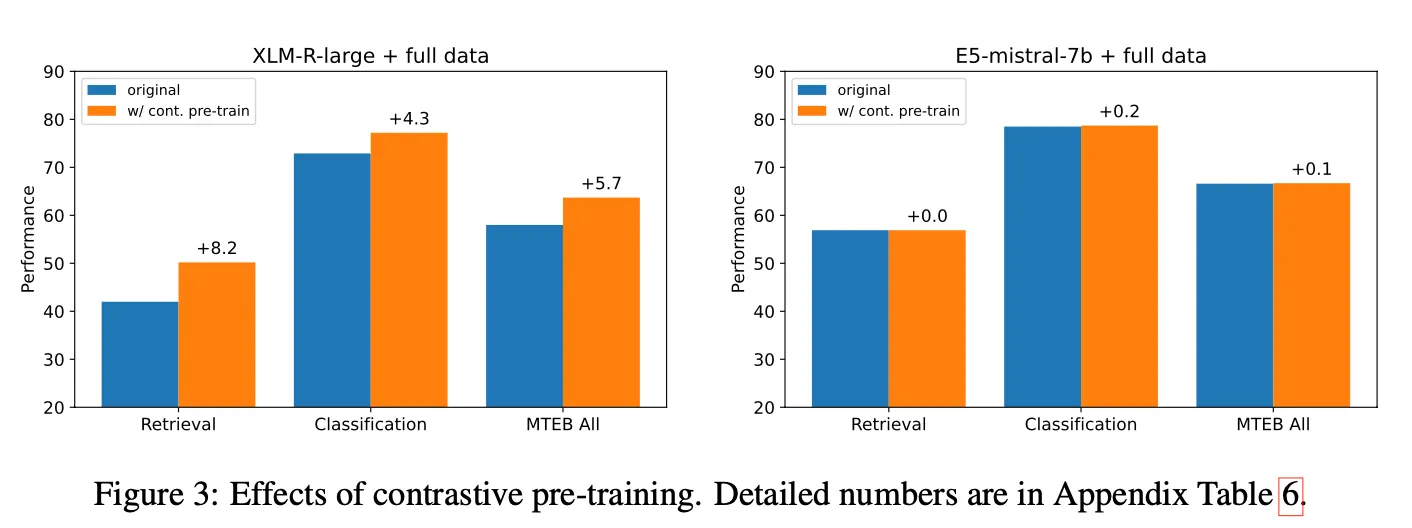
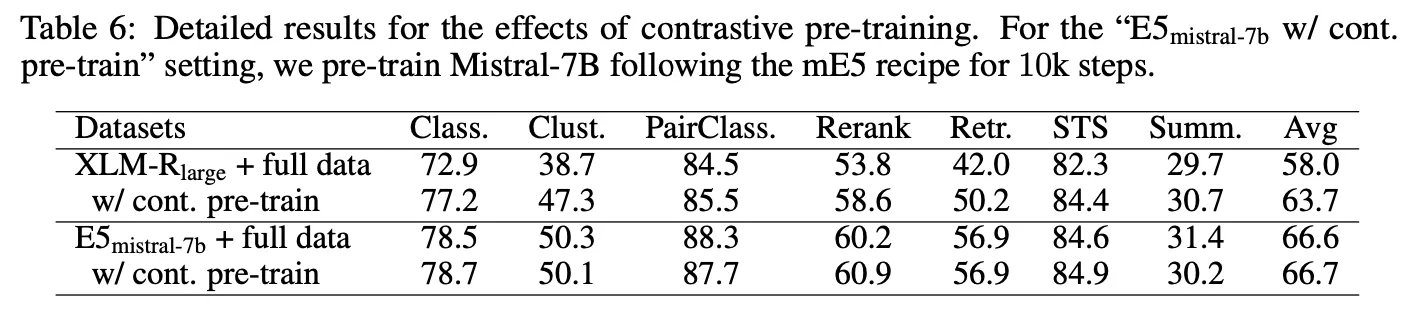
Pre-training 단계에서부터 contrastive learning을 적용했을 때의 효과가 별로 없었음. 모델이 크고 학습 데이터가 많아져서 그런 것으로 예상
◦
Ablation study
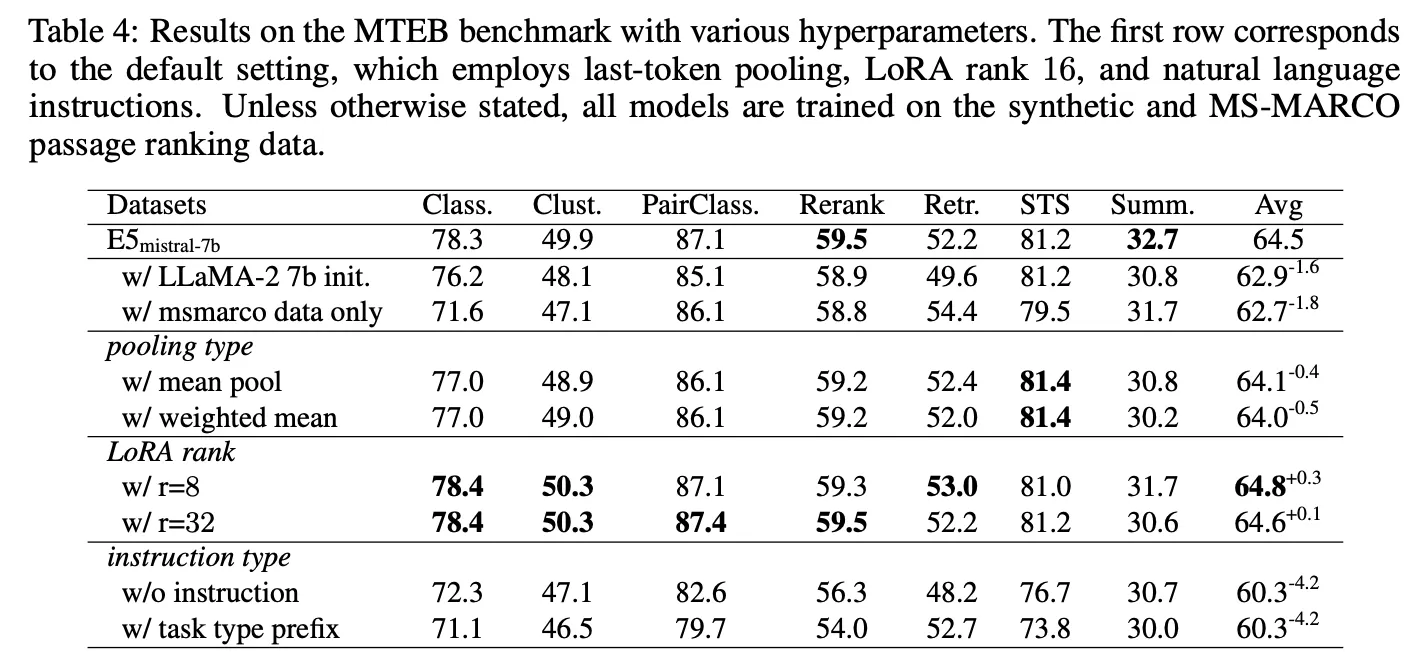
▪
LLaMA 2 백본 대비 Mistral-7B가 더 좋음 (62.9 -> 64.5)
▪
Augmentation 효과 있음 (62.7 -> 64.5)
▪
Pooling 방법은 그닥 효과가 없음 (64.5 -> 64.0 or 64.1)
▪
LoRA rank에 따라서 약간의 성능 차이가 있음 (다른 값이 더 좋은데 왜 r=16을 사용했는지는 명확하지 않음. 논문에서는 큰 차이가 아니라 그냥 r=16을 사용했다고 언급)
▪
Instruction을 넣어주는 것이 매우 중요! (60.3 -> 64.5). 이는 백본이 sLLM이라 promping을 이해하여 embedding 계산에도 도움을 주기 때문인 것으로 예상
Examples
•
사용한 Instruction 예시


논의사항
•
SGPT와 유사하게 비교적 큰 크기의 transformer decoder 백본을 활용한 접근 방법. 꽤 실용적이며 다양한 오픈 소스 sLLM이 존재하는 현재 시점에서 가장 유용한 접근 방법 중 하나라 판단
•
생성 데이터 및 데이터 생성에 사용된 프롬프트를 공개하지 않아서 (그들이 공개한 checkpoint를 쓰는 것 말고는) 제안한 방법론의 재현 및 검증이 어려운 점은 아쉬움
•
기존에도 그랬지만 앞으로도 계속 모델 checkpoint만 공개하고 실제 사용한 데이터나 데이터 수집/생성 detail은 공개하지 않는 추세가 점점 더 심해질 것 같음
•
Good Data is All You Need!!