


최근 LLM은 기존의 가속기용 언어외에도 기본적인 C, numpy 처럼 기초적인 언어로 구현되고 있습니다. 이는 학습과 이해 목적은 물론 성능의 최적화 등 여러 가지 이유로 큰 의미가 있습니다.
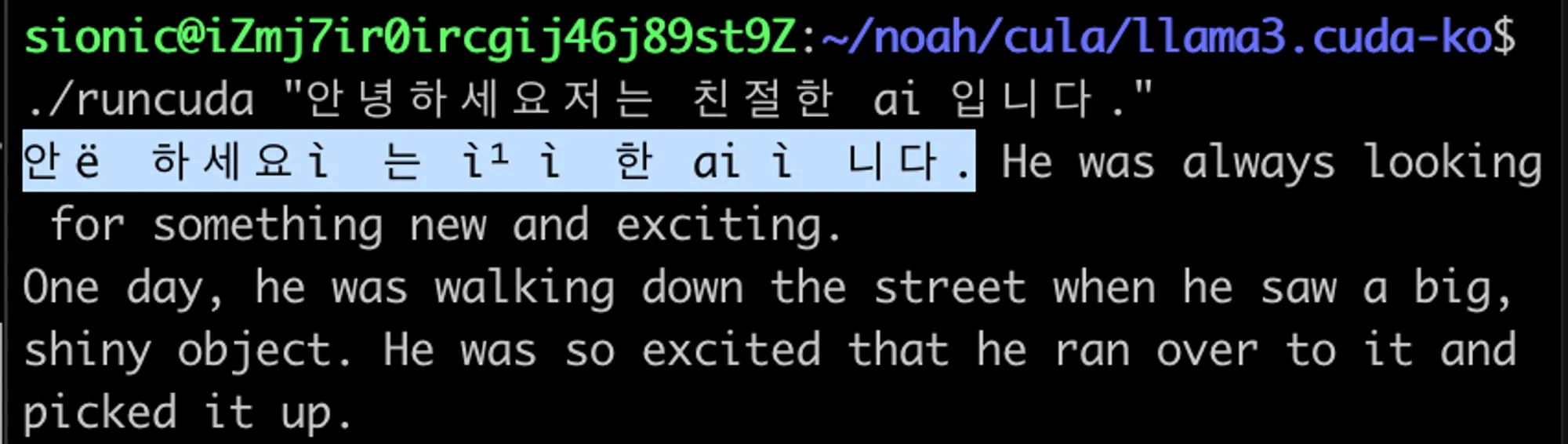
하지만 그중 상당 부분은 축약적으로 구현되어 있어서 다국어 지원이 안되는 경우가 있습니다. 이런 부분을 좀더 원리를 이해하고 구현한다면 다양한 디바이스에서의 (NPU, GPU, FPGA) 구현과 저수준, 고성능이 필요한 토큰 생성 전략에 직접적으로 큰 도움이 될 수 있습니다.
본 아티클은 순수 CUDA 및 C 문법을 따르는 구현으로 최소한의 구현으로 llama 모델을 추론하고 그 과정에서 LLM 의 다국어 멀티바이트 언어를 다루는 방법을 설명합니다.
(llama3 cuda base code - )
LLM이 강력한 성능을 보이면서 자연어처리 과제에서 다양하게 활용되고 있습니다.
자연어 처리의 관점에서 이러한 LM의 성능과 단점을 크게 개선한 지점 중 하나가 OoV(Out of Vocabulary) 문제의 해결입니다.
일반적으로 자연어는 기계가 이해하기 용이한 숫자 단위로 분해, 변환된 뒤 적절한 임베딩 벡터, 텐서 등으로 의미적 임베딩 과정을 거칩니다.
하지만 Vocabulary 를 크게 가져갈수록 모델과 계산 성능에 부담이 되며 너무 작게 가져갈 경우 사용하고 이해하는 어휘의 부족으로 모델이 성능이 저하되는 경우가 있습니다.
그것을 해결하기 위한 대안 중 하나가 본 글에서 다룰 BPE (Byte Pair Encoding) 형태의 여러 파생 알고리즘 입니다. 현시점엔 여러가지 알고리즘과 다양한방법론이 알려져 있지만 핵심 원리는 간단한 편입니다.
OoV 로 발생한 UNK_ 즉 모르는 어휘를 언어적 최소 단위인 형태소 보다 작은 단위로 분해합니다. 즉 정확히는 기계의 표현식인 바이트 수준까지 나누게 됩니다.
예를들어  라는 이모지는 다음과 같은 유니코드로 정의되며 (U+1F44C)
UTF-8 인코딩 형식에서는 [0xF0, 0x9F, 0x91, 0x8C] 4개의 바이트의 나열로 표현됩니다.
라는 이모지는 다음과 같은 유니코드로 정의되며 (U+1F44C)
UTF-8 인코딩 형식에서는 [0xF0, 0x9F, 0x91, 0x8C] 4개의 바이트의 나열로 표현됩니다.
라는 이모지는 다음과 같은 유니코드로 정의되며 (U+1F44C)
UTF-8 인코딩 형식에서는 [0xF0, 0x9F, 0x91, 0x8C] 4개의 바이트의 나열로 표현됩니다.
위와 같이 다국어 및 확장 문자들이 OoV가 발생한 경우 BPE 알고리즘은 이를 여러 바이트로 분할하여 2~4개의 토큰으로 나누게 됩니다.
그렇기 때문에 이를 적절한 표현식과 토큰들을 다시 합쳐서 적합한 출력을 할 필요가 있습니다. 단순하게 BPE로 발생한 바이트 순서열을 출력하면 아래와 같은 이상한 결과를 얻게 됩니다.
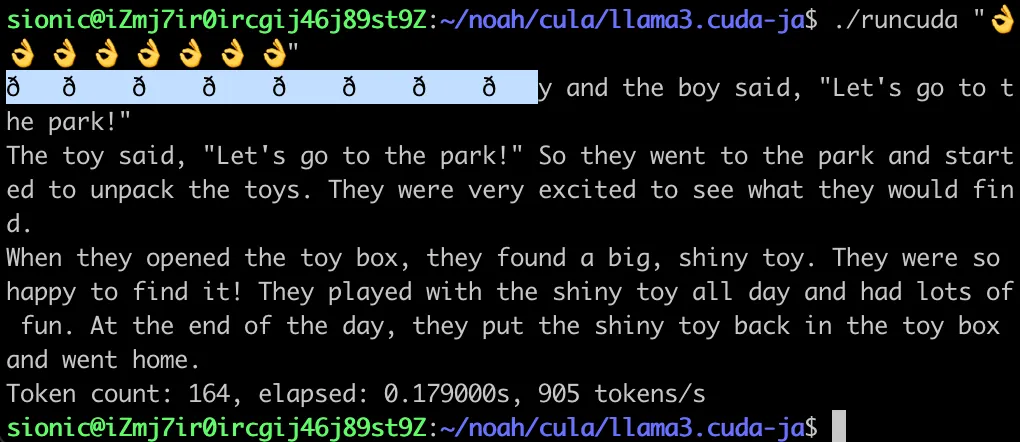
이런 경우 해당 토크나이저를 사용하면 간단한 문제이나 지금은 C 언어 수준의 최소한의 구현으로 그 원리를 알아보는 시간이기 때문에 약간의 리버스 엔지니어링을 통하여 접근하여 보겠습니다.
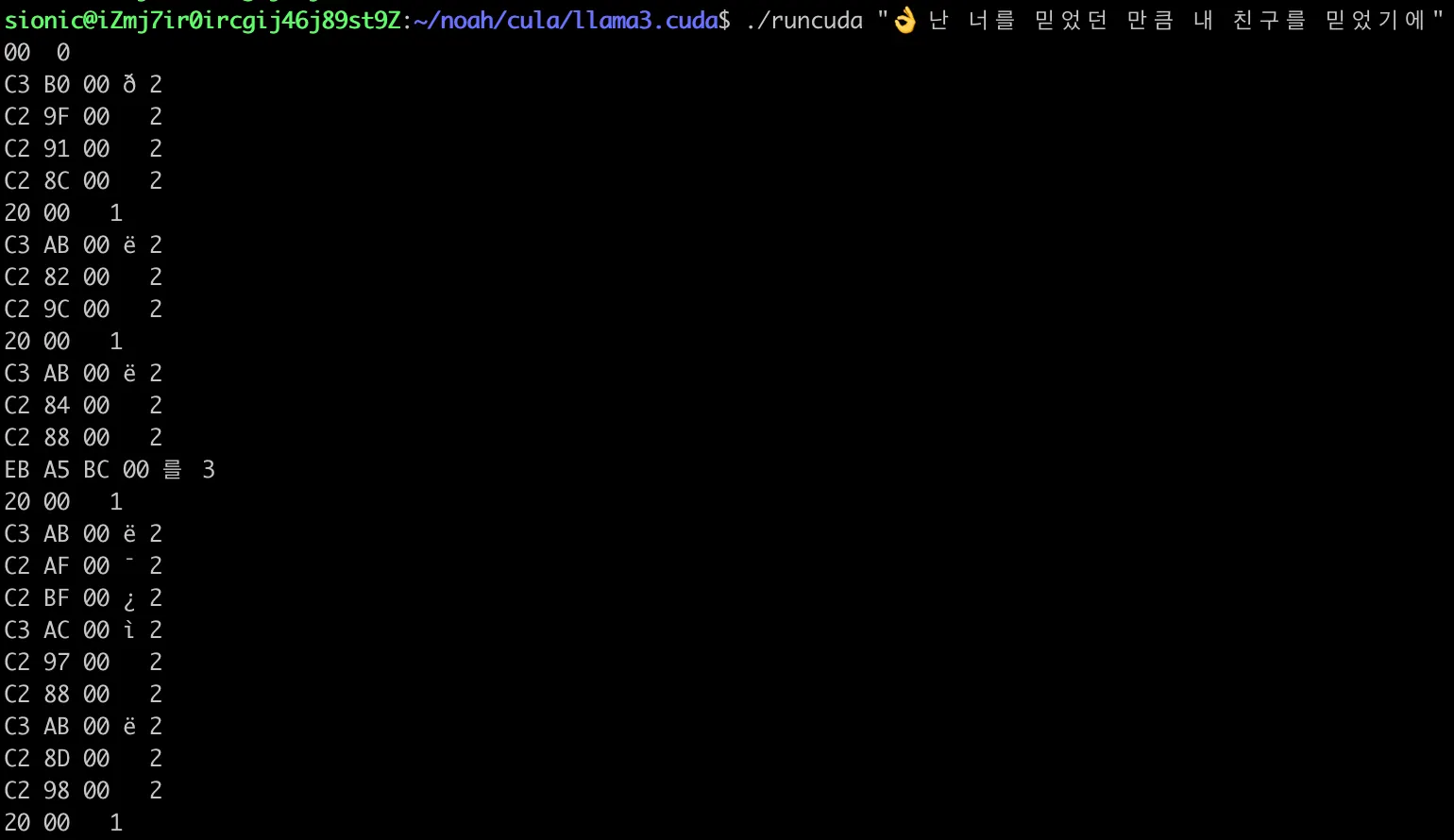
우선 해당 출력을 모두 토큰 혹은 문자열의 길이를 측정하고 그 내용을 바이트 단위의 16진수로 나누어 출력해보겠습니다.
가장 마지막 숫자가 문자열의 길이이며 예를 들어 2인 경우,
바이트1, 바이트2, 널 문자, 해당 문자열 출력값, 길이
순서입니다.
출력 코드는 아래와 같습니다.
void safe_printf(char *piece) {
...
int cutbit = 0xff;
int len = strlen(piece);
if (len == 0) {
printf("%02X %s %d \n", piece[0] & cutbit, piece, strlen(piece));}
if (len == 1) {
printf("%02X %02X %s %d \n", piece[0] & cutbit, piece[1] & cutbit, piece, strlen(piece));}
if (len == 2) {
printf("%02X %02X %02X %s %d \n", piece[0] & cutbit, piece[1] & cutbit, piece[2] & cutbit, piece, strlen(piece));}
if (len == 3) {
printf("%02X %02X %02X %02X %s %d \n", piece[0] & cutbit, piece[1] & cutbit, piece[2] & cutbit, piece[3] & cutbit, piece, strlen(piece));}
if (len == 4) {
printf("%02X %02X %02X %02X %02X %s %d \n", piece[0] & cutbit, piece[1] & cutbit, piece[2] & cutbit, piece[3] & cutbit, piece[4] & cutbit, piece, strlen(piece));}
unsigned char header = piece[1] & cutbit
if (header == 0xC3){
unsigned char mask = 0x40;
unsigned char payload = piece[1]
unsigned char decode = payload | mask;
printf("%c", decode );
}else if(header == 0xC2) {
printf("%c", payload);
}else{
printf("%s", piece);
}
C
복사
예제에서 값을 16진수로 출력하여 확인하는 이유는 1바이트, 8비트를 항상 두 자리의 16진수 숫자로 표현할 수 있기 때문에 4비트 단위의 기수적 직관성을 위해서 입니다.
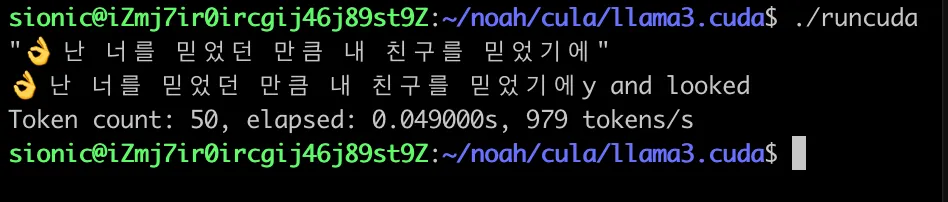
” 난 너를 믿었던 만큼” 이라는 노래 가사의 문장이 해당 llama.cuda 프로젝트의 출력 구문에서 순서대로 출력되는 것을 볼 수 있습니다.
난 너를 믿었던 만큼” 이라는 노래 가사의 문장이 해당 llama.cuda 프로젝트의 출력 구문에서 순서대로 출력되는 것을 볼 수 있습니다.#👌
C3 B0 00 ð 2 # 👌 - TrailByte and bit masking
C2 9F 00 2 # 👌 - 2 번째 바이트
C2 91 00 2 # 👌 - 3 번째 바이트
C2 8C 00 2 # 👌 - 4 번째 바이트
#
20 00 1 # 스페이스
#난
C3 AB 00 ë 2 # 난
C2 82 00 2
C2 9C 00 2
#
20 00 1 # 스페이스
#너
C3 AB 00 ë 2 # 너
C2 84 00 2
C2 88 00 2
#를
EB A5 BC 00 를 3 # 를
20 00 1
#믿
C3 AB 00 ë 2 # 믿
C2 AF 00 ¯ 2
C2 BF 00 ¿ 2
#었
C3 AC 00 ì 2 # 었
C2 97 00 2
C2 88 00 2
#던
C3 AB 00 ë 2 # 던
C2 8D 00 2
C2 98 00 2
#
20 00 1 # 스페이스
#만
EB A7 8C 00 만 3 #만
Markdown
복사
여기서 몇 가지 규칙을 찾을 수 있는데요. 자연어 처리에서 널리 사용되던 방식 중 하나인 BIO (Begin, Inside, Outside) 태깅 기법과 유사한 규칙을 볼 수 있습니다.
멀티 바이트 토큰이 출력될 경우
토큰의 첫번째 바이트가 C3
해당 바이트의 중간 연결 토큰은 C2
그외 토큰은 정상적인 UTF-8 헤더 범위
즉 다음의 이모지 토큰 는 다음과 같은 4개의 길이 2 문자열로 출력 됩니다.
는 다음과 같은 4개의 길이 2 문자열로 출력 됩니다.
C3 B0 00 ð 2 # 👌
C2 9F 00 2
C2 91 00 2
C2 8C 00 2
Markdown
복사
실제 UTF-8 인코딩 형식에서는 각각 두 번째 토큰인 B0 9F 91 8C 4개의 순서열로 표현될 것 같습니다. 하지만 실제로 출력을 진행하면 알 수 없는 문자가 출력되는 것을 볼 수 있습니다. 실제로 B0의 경우 일반적인 utf-8 문자 형식이 아니며 일부 규칙에 따라 첫 번째 토큰이 변환되어있는 것을 유추할 수 있습니다.
•
실제 UTF-8: F0 9F 91 8C
•
출력된 바이트: B0 9F 91 8C
C3 B0 00 ð 2 # 👌 - TrailByte and bit masking
C2 9F 00 2 # 👌 - 2 Second byte
C2 91 00 2 # 👌 - 3 Third byte
C2 8C 00 2 # 👌 - 4 Fourth byte
Markdown
복사
실제 유니코드 정의에서 위 이모지의 바이트 순서열은 다음과 같습니다.
[ 0xF0, 0x9F, 0x91, 0x8C ] 잘 살펴보면 특정 비트만 마스킹이 된다는 것을 확인할 수 있습니다.
해당 규칙을 간단한 비트 연산으로 고려하여 보면 다음과 같습니다.
1 1 1 1 0 0 0 0 -> F0
- 1 0 1 1 0 0 0 0 -> B0
------------------------
0 1 0 0 0 0 0 0 -> 40
Markdown
복사
위와 같이 왼쪽 두 번째 비트만 OR 연산이 처리되면 되는 간단한 규칙이 있다는 것을 알 수 있습니다.
해당 비트 마스크는 2진수 표현으로 0 1 0 0 0 0 0 0 , 16 진수 표현으로 (0x40) 이기 때문에
“ | 0x40 “ 연산을 추가해줍니다.
최종 코드는 다음과 같습니다.
1.
& 마스크를 사용하여 명시적으로 1바이트만 남깁니다.
2.
특수한 헤더가 존재할 경우 적절한 비트 연산으로 utf-8 표준 범위로 변환합니다.
3.
멀티바이트는 stdout 스트림에 1바이트 단위로 출력합니다.
4.
이외 완성된 토큰은 문자열 단위로 출력 합니다.
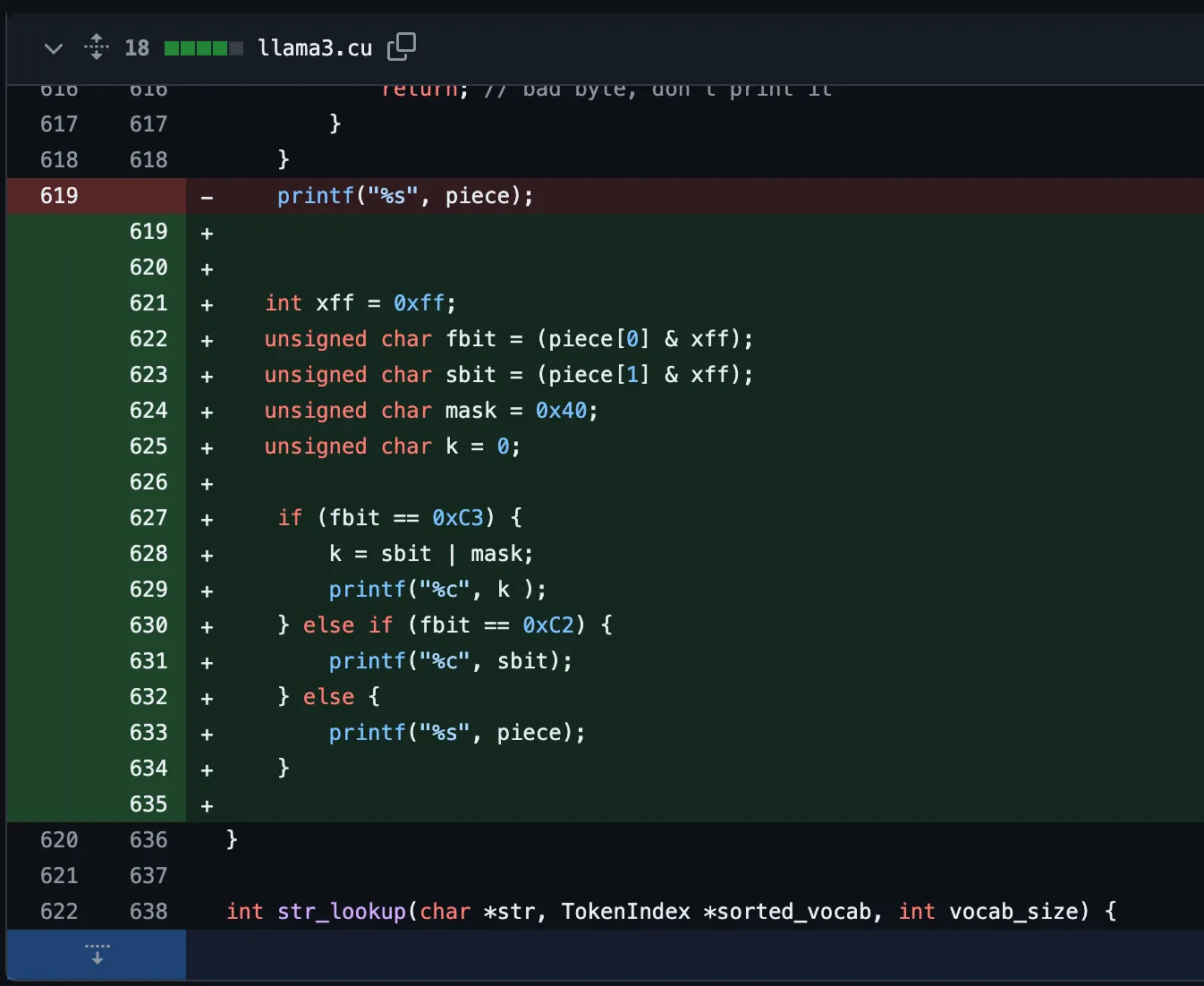
위와 같은 구현들은 표준 구성이 아닌 역공학 관점에서 최소한의 구현을 사용하기 때문에 예기치 않은 문제가 발생할 수 있습니다.
하지만 cuda 혹은 저수준의 언어에서 최소한의 구현과 디바이스 수준의 영역에서 바이트 스트림을 제어하고 토큰 단위의 생성 전략을 구현하며 완전히 이해할 수 있기 때문에 가치가 높습니다.
일부 룰은 쿼리문으로도 작성될 수도 있기 때문에 다양한 환경에서 근본적인 수준에서 LM을 이해하고 사용할 수 있습니다.
Out of Vocabulary(OoV) OoV의 문제점은 모델이 해당 단어에 대한 사전 지식이 없기 때문에 해당 문맥을 해석하는 데 어려움 겪는 것 입니다.
학습과정에서 보지 못하였거나 단어 사전을 최적화 하기위해서 성능을 위해 의도적으로 제거되는 경우 발생됩니다.
이런 현상은 모델이 언어를 이해하고 생성하는 데 잠재적인 부정확성이 발생할 수 있으며. OoV 단어를 이해하지 못한채 생성한 문장은 의미를 정확히 파악하기 어렵거나, 정확도가 떨어지거나, 심각한 오류가 발생할 수 있습니다.
C3, C2의 경우 멀티바이트 UTF-8 문자의 시작을 알려주는, 즉 OOV 로 처리되는 멀티바이트의 시작을 의미합니다. 따라서 이 문자열에 패턴을 이용하여 간단하게 한글이 처리되지 않는 문제를 해결할 수 있었습니다.