
도입
•
챗봇, 요약, 기계 번역 등 많은 자연어 생성 AI의 개발에 있어서 정확한 평가(evaluation)는 매우 중요하나 고통스러운 과정임
•
LLM은 prompting만으로 여러 종류의 문제에서 좋은 성능을 보여주고 있으며 최근 논문에서는 GPT-4를 통하여 evaluation을 자동으로 수행하는 등 사람의 판단이 필요한 영역에서 활용하는 사례가 점차 증가하고 있음
•
이 아티클에서는 LLM을 활용하여 사실 검증(fact verification)을 수행하고 스스로 잘못된 정보를 수정하여 환각(hallucination)을 낮추는 논문에 대하여 소개함
•
리뷰 논문
◦
https://arxiv.org/abs/2309.11495 (by Meta AI)

개요
•
질문에 대해서 바로 답변을 생성하기보다는 중간 풀이 과정을 LLM이 스스로 추론의 과정을 생성하게 하면 성능이 더 높아진다는 현상은 여러 논문에서 관찰 (CoT)
•
이 논문에서는 답변 초안을 생성한 후 자체적으로 답변의 신뢰도를 검증할 수 있는 질문을 생성하여 확인한 후 최종 답변을 생성하는 Chain-of-Verification(CoVe) 방법을 제안
•
List-based question과 long-form text generation 문제에서 hallucination이 감소하고 성능이 더 향상되는 결과를 관찰

방법론
•
아래의 단계를 거치며 유저 질문에 대한 답변을 생성함
•
답변 초안을 생성
◦
주어진 질문에 대하여 LLM으로부터 답변을 생성
◦
Prompt 예시

•
Verification question을 생성
◦
질문과 생성한 답변을 보고 확인이 필요한 내용에 대한 verification question을 생성
◦
Prompt 예시

•
각 verification question에 대한 답변을 생성
◦
생성한 verification 질문에 대하여 답변을 생성하는 방식에 따라 크게 4가지로 나눔 (joint, 2-step, factored, factor+revise)
◦
Joint : verification 질문 생성 및 답변을 하나의 프롬프트로 동시에 수행
◦
2-step : verification 질문 생성과 답변을 분리하여 수행. 생성한 질문만 모아서 LLM으로부터 답변을 생성함
◦
Factored : verification 질문에 대한 답변을 생성할 때 질문 하나에 하나씩 별도로 LLM을 호출하여 생성
◦
Factor+Revise : 처음 답변과 verification 결과가 서로 일치하는지 아닌지를 별도의 Prompt를 통해 명시적으로 확인하는 과정을 추가
◦
Prompt 예시


•
위 내용을 종합하여 최종 답변 생성
◦
Prompt 예시

결과
•
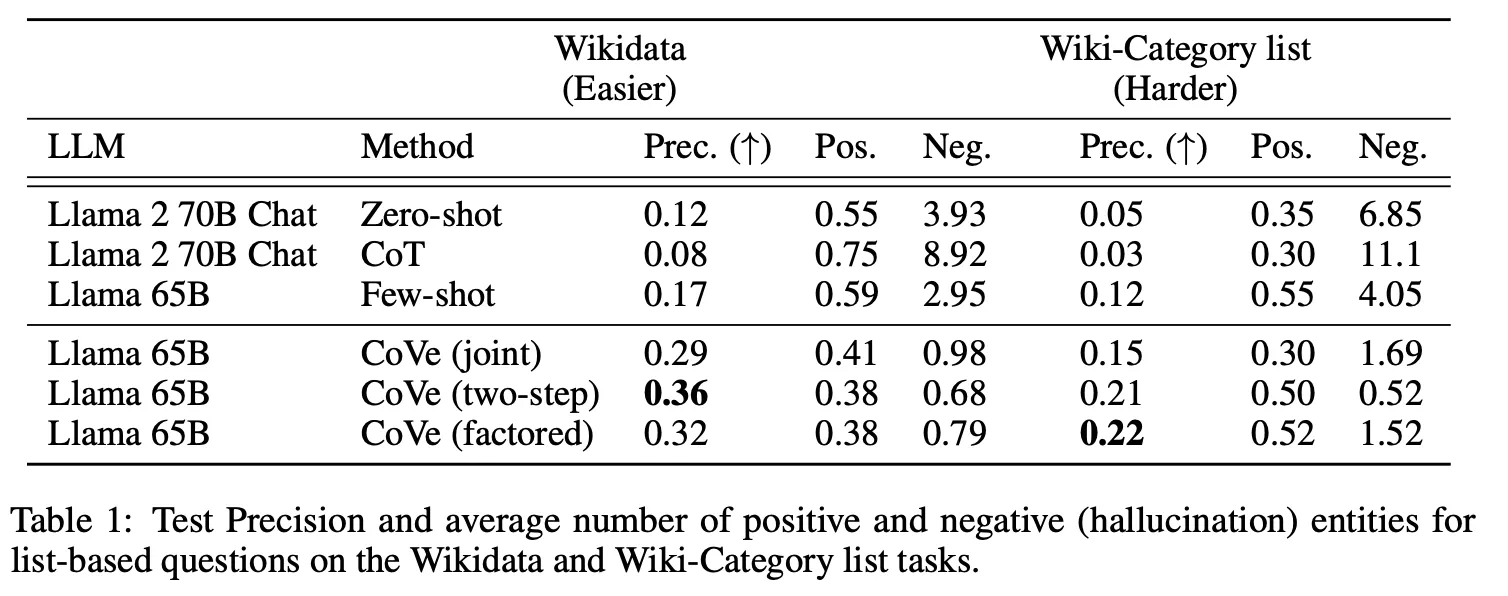
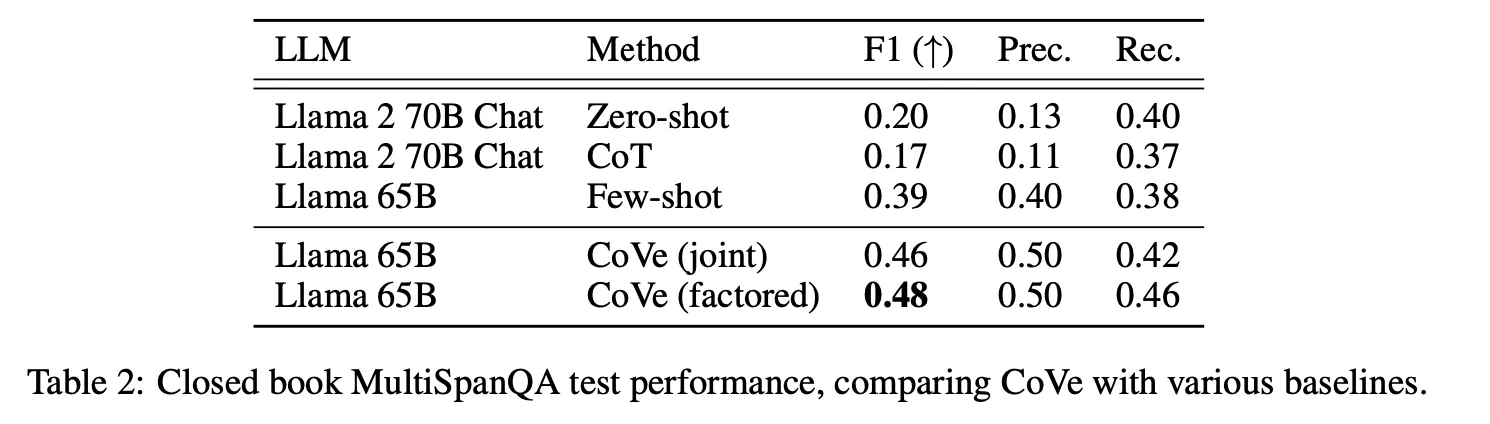
Few-shot 대비 list-based tasks (Wikidata, Wiki-Category) 및 Closed-book QA(MultiSpanQA)에서 큰 폭의 성능 향상 관찰
•
해당 task에서 CoT가 zero-shot 보다 모두 성능이 떨어지는 것으로 나온 부분은 의아함
•
Joint의 경우 처음 LLM이 생성한 답변에 잘못된 정보가 있는 경우 verification 과정에서 noise로 작용할 수 있기 때문에 일반적으로 2-step이나 factored 보다 성능이 떨어짐
논의사항
•
Zero-shot/few-shot prompt을 통하여 LLM이 사실을 검증하고 판단할 수 있다는 것을 보여주었다는 측면에서 의의가 있음
•
제안한 방법은 LLM이 가진 fact verification 능력으로 추론의 정확도를 높이는 것으로 넓게 보면 CoT의 변형이라고도 생각할 수 있음
◦
즉, 주어진 문제 상황에 보다 적합한 reasoning chain을 세밀하게 설계하여 효과를 높임
•
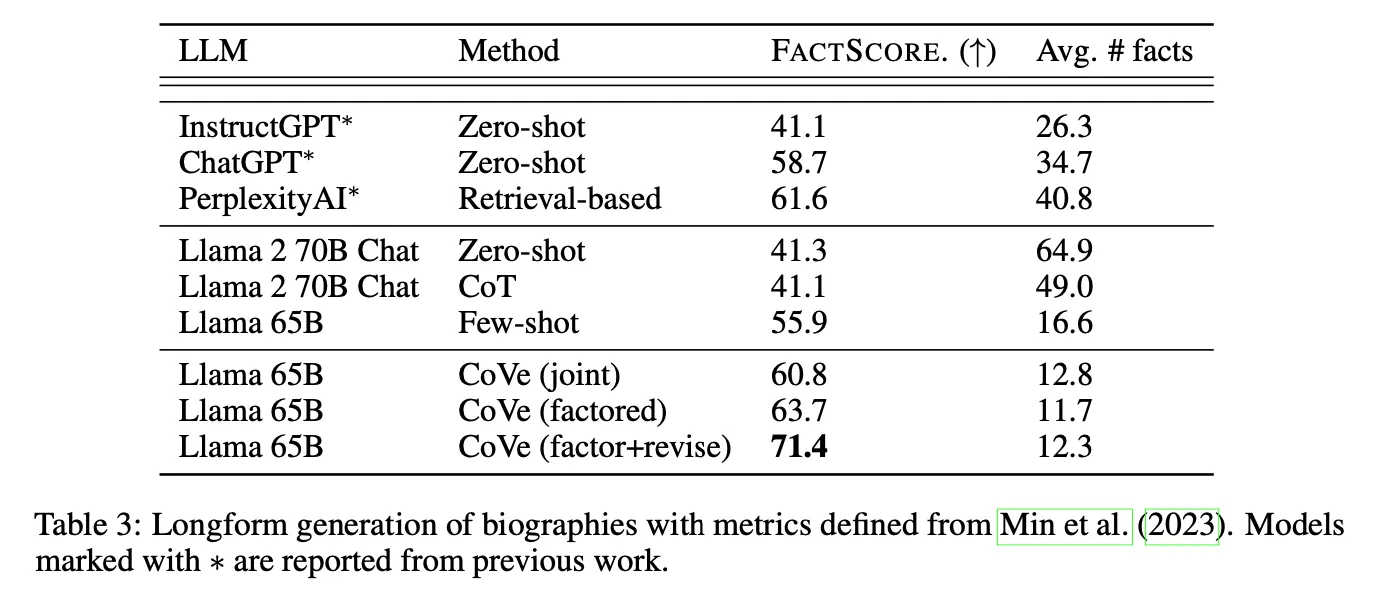
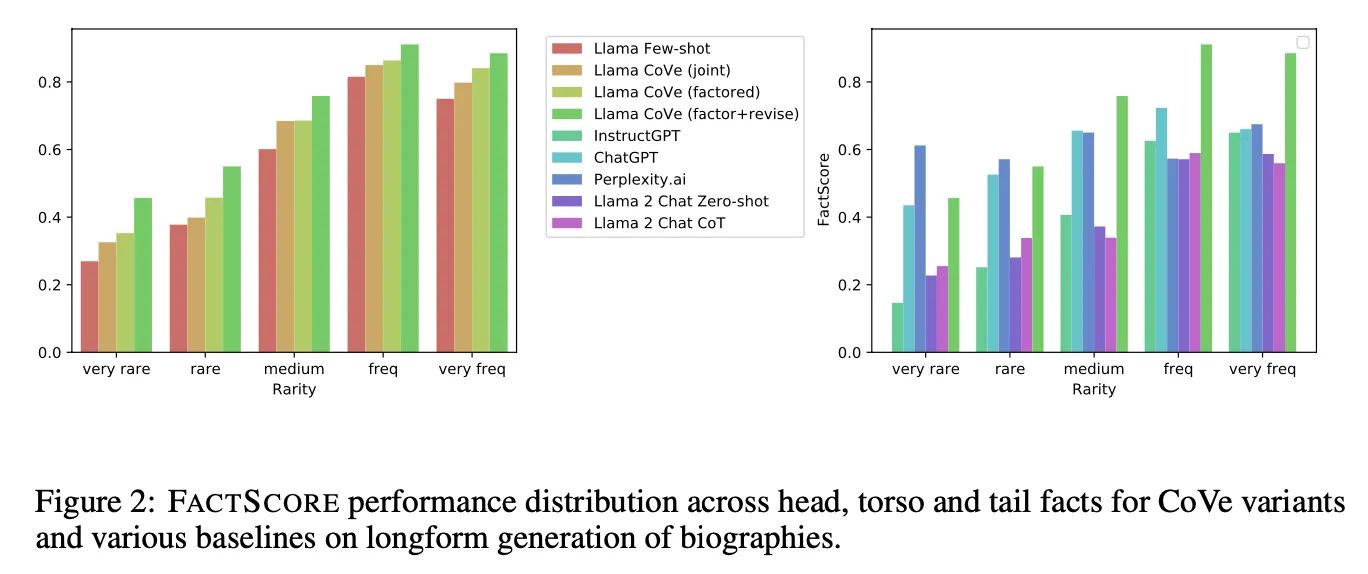
비록 동일 백본이 아니라 fair 한 비교는 아니지만 외부 지식을 활용하지 않고 LLM이 가진 지식과 능력만으로 외부 지식을 참조하는 retrieval-based의 PerplexityAI 보다도 더 높은 성능을 보이는 점은 인상적. 그렇지만 rare fact의 경우에는 Perplexity AI가 더 높은 성능을 보임
•
이 현상은 널리 알려진 지식 관련 task는 이미 LLM이 충분히 학습하였으므로 CoVe 기법으로 그것을 제대로 활용하기만 해도 좋은 성능을 가질 수 있기 때문으로 판단. 그렇지만 상대적으로 널리 알려지지 않은 지식일수록 retrieval을 통하여 외부 지식을 적절히 주입해 주는 것이 절대적으로 중요하다는 것을 알 수 있음