

도입
•
LLM은 zero/few-shot prompting 만으로도 많은 task에서 뛰어난 성능을 보이지만 결과가 입력한 prompt에 매우 민감함
•
그렇지만 task에 맞게 사람이 직접 최적의 prompt를 만드는 것은 매우 어렵고, 시간과 비용이 많이 소요되는 작업이며, 또한 prompt가 얼마나 잘 동작할지 사전에 확인하는 것이 쉽지 않음
•
이 아티클에서는 위 문제에 대한 대안으로 LLM을 활용하여 최적의 prompt를 자동으로 생성하는 최신 연구와 관련 reference에 대하여 소개함
•
리뷰 논문
◦
Automatic Prompt Engineer (APE) : https://arxiv.org/abs/2211.01910 (by Univ. of Toronto, Vector Institute, Univ. of Waterloo)
◦
◦
◦

(이미지 출처) 프레젠테이션의 ‘Designer’ 기능을 사용하여 이미지 자동 생성
개요
•
Prompt를 자동으로 생성하기 위해서는 아래와 같은 문제들이 존재함
◦
Instruction Generation : 주어진 task에 맞는 instruction을 자동으로 생성
◦
Instruction Ranking : 얼마나 좋은 prompt인지 성능 예측
•
요약
Stage | Features | APE | iPrompt | Auto Instruct | BPO |
Instruction Generation | 백본 모델 | InstructGPT | GPT-J | ChatGPT
GPT-4 | llama2-7b-chat |
방식 | prompting | prompting | prompting | tuning | |
상세 | 3가지 고정 meta prompt로 여러 개 생성 | 학습 데이터를 입력으로 여러 개 생성 | 7가지 고정 meta prompt로 각 3개씩 총 21개 생성 | simple prompt를 입력으로 하여 optimized prompt를 생성하도록 학습 | |
Instruction Ranking | 백본 모델 | InstructGPT | GPT-J
GPT-3 | FLAN-T5-Large | 없음 |
방식 | prompting | prompting | tuning | ||
상세 | 생성한 prompt를 입력으로 LLM 결과 예측
(accuracy & log prob. 기반) | 생성한 prompt를 입력으로 LLM 결과 예측
(log prob. 기반) | LLM 생성 결과와 정답 간 점수의 분포와 ranker에서 ‘yes’ token의 확률 분포를 일치하도록 학습 |
방법론 상세
•
APE
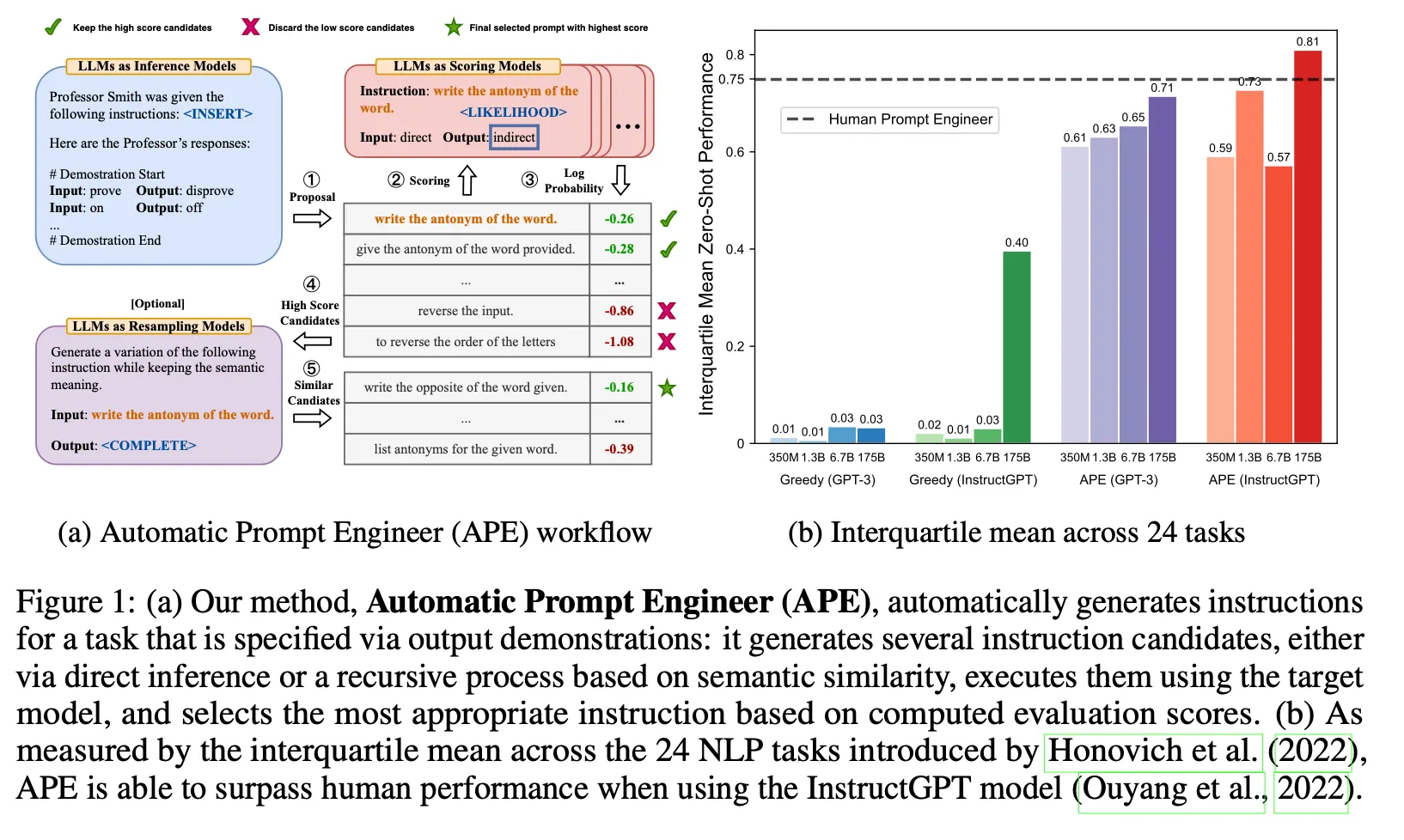
◦
3 종류의 meta prompt (forward mode, reverse mode, customized prompt)에 학습데이터(input, output)를 넣고 m개의 instruction을 생성

◦
생성한 instruction에 training 데이터 세트에서 random sampling한 example들을 넣고 답변을 예측. 예측한 결과와 실제 정답을 비교하여 instruction에 대한 점수를 측정
▪
execution accuracy : 각 example에 대하여 정답이 맞았는지 아닌지를 0-1 loss로 평가
▪
log probability : 정답 text에 대한 LLM의 log probability 값을 점수로 사용
◦
측정한 점수를 기반으로 top k instruction을 선택함
◦
(Optional) top k instruction으로 비슷한 의미를 갖는 변형 instruction을 LLM을 통하여 추가 생성하여 평가 대상 instruction set에 추가. 위 과정을 반복

◦
알고리즘

•
iPrompt
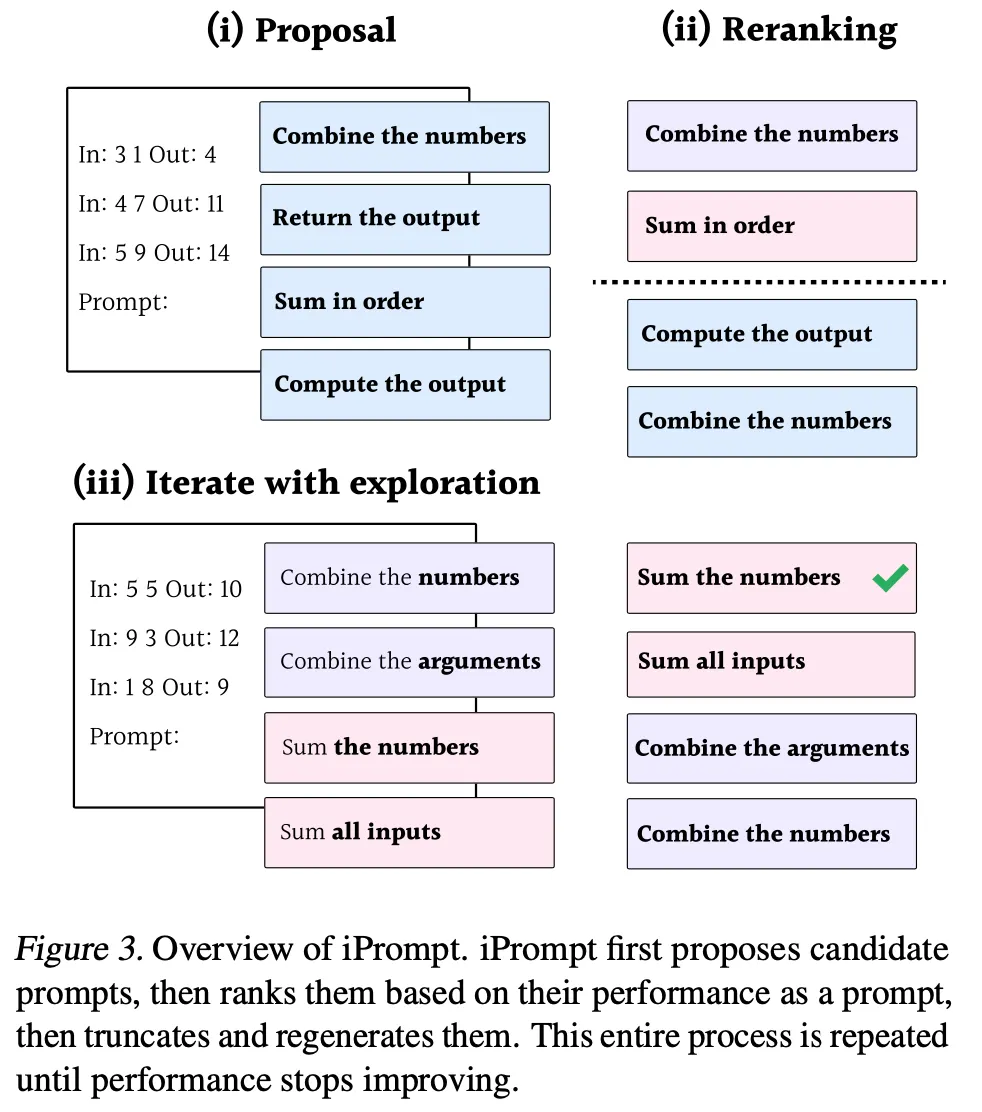
◦
학습 데이터(input, output)들만 사용하여 zero-shot으로 candidate prompt들을 생성
▪
instruction 생성 용 meta prompt에 대한 자세한 언급이 없음.
▪
간단한 instruction과 예제 데이터 정도의 기본적인 형태일 것으로 예상
◦
생성한 instruction에 training 데이터 세트에서 random sampling한 예제들을 넣고 LLM으로 답변 생성. 정답 text에 대한 log probability를 점수로 사용
◦
측정한 점수를 기반으로 top k instruction을 선택함
◦
선택된 instruction에서 임의의 위치를 기준으로 뒤쪽을 잘라낸 후 해당 부분을 LLM으로 다시 생성하여 새로운 prompt 후보를 만들어 냄. 위 과정을 반복
•
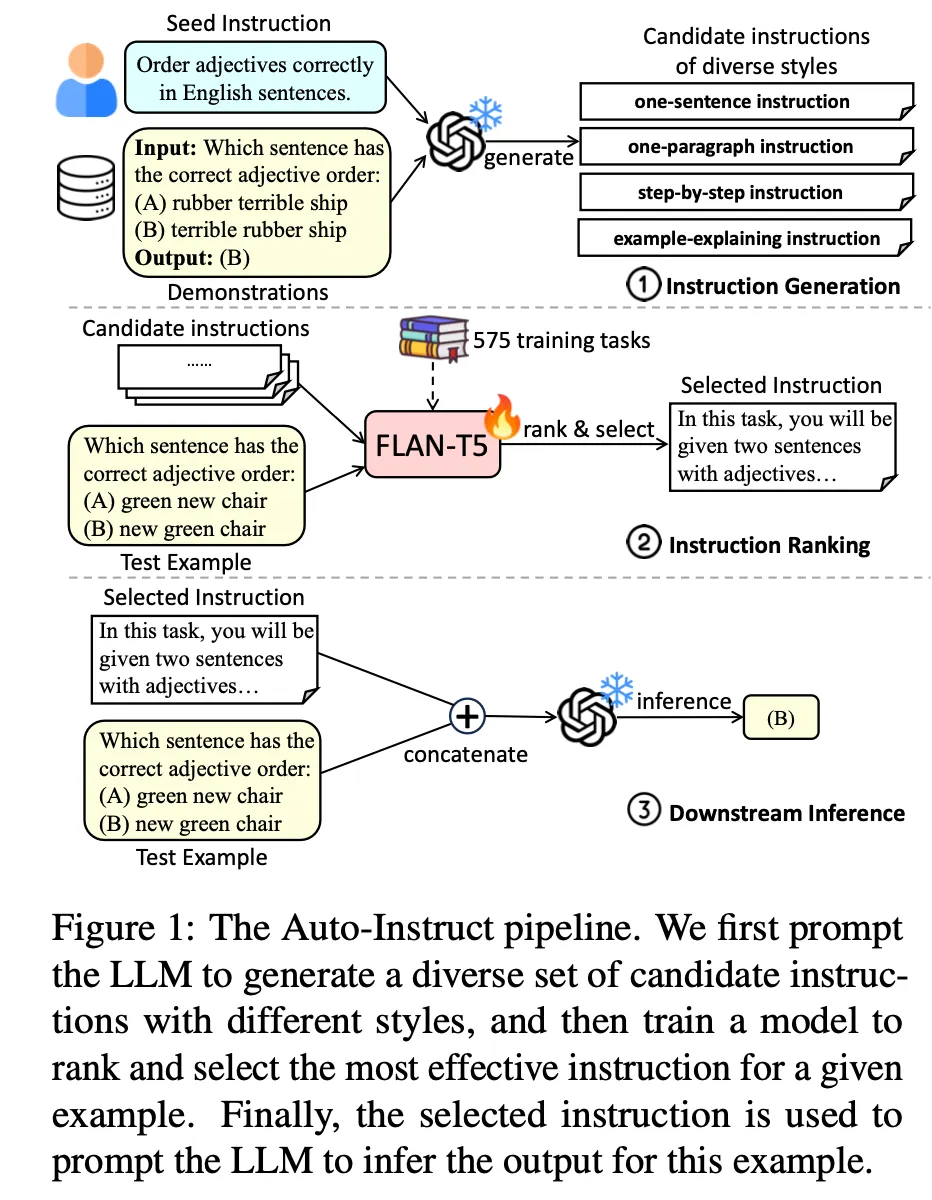
Auto Instruct
◦
다음 3 단계로 이루어짐
◦
Instruction 생성
▪
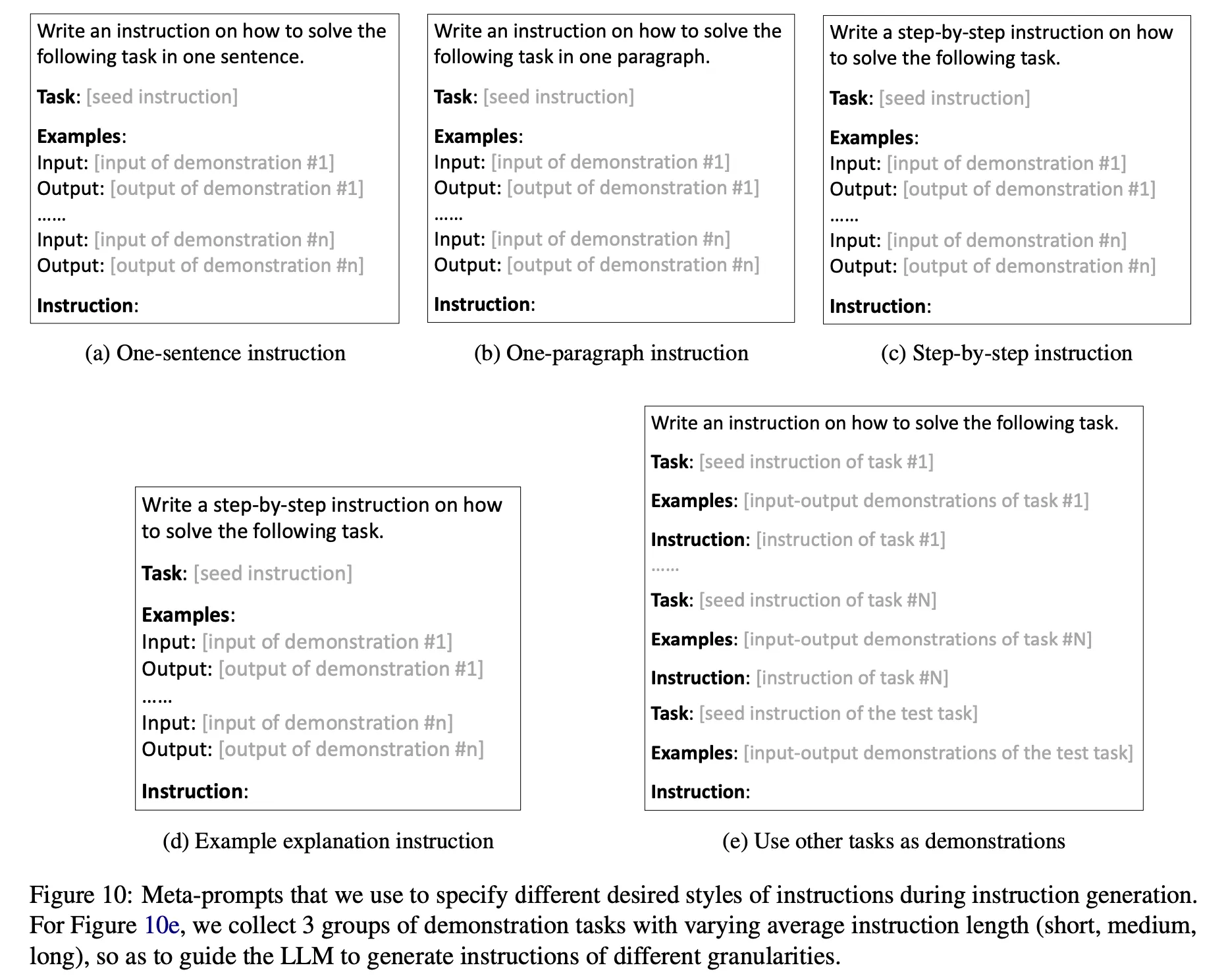
Instruction을 생성하는 meta prompt를 7가지 다른 형식으로 구성하고 각각 3개씩 생성 (총 21개)
•
다음과 같이 4가지 다른 style로 생성하라고 명시적으로 지시(위 그림에서 (a)-(d)) : 'one sentence', 'one paragraph', 'step-by-step', 'explanations of the given examples' (예제 그림에서 (d)의 instruction이 잘못되었음. ‘explanations of …’로 바뀌어야 함)
•
기본 instruction(위 그림에서 (e))에 3가지 종류의 다른 예제를 넣어서 생성 : 여기서 예제에 들어가는 데이터는 SuperNI 에서 추출. SuperNI 데이터를 instruction 길이 기준으로 3개의 그룹으로 clustering한 후 같은 cluster의 데이터로 meta prompt를 생성
◦
Instruction ranking & 선택
▪
FLAN-T5-Large 모델을 튜닝하여 사용
▪
SuperNI 데이터 세트에서 영어 데이터만 추출한 후 task type(e.g., QA, sentimental analysis, etc.)에 따라 분류
▪
Input 에 대하여 평가하고자 하는 instruction 로 아래에서 보는 바와 같이 prompt를 구성하여 ranking model에 입력으로 넣음. 이 때 모델에서 생성하는 'yes' 토큰의 logit값이 instruction 의 점수가 되도록 학습
▪
이를 위하여 정답 와 입력한 instruction으로 생성한 답변 사이의 ROUGE-L 점수(아래 수식에서 )의 분포(softmax over all candidates)와 'yes' 토큰의 확률 분포를 최대한 일치하도록 학습함 (두 분포 사이의 KL divergence 최소화)
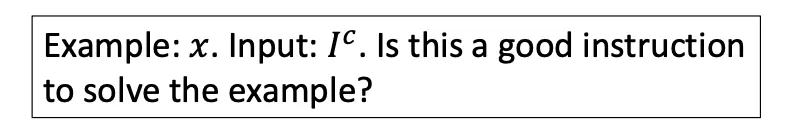
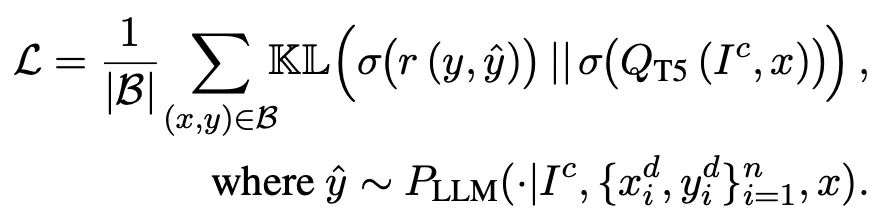
▪
사용한 task 종류 : 575(train), 91(test)
▪
한 task 당 각각 최대 400개까지 예제를 sampling --> 총 122k 구축
◦
선택한 instruction으로 최종 결과 생성
•
BPO
◦
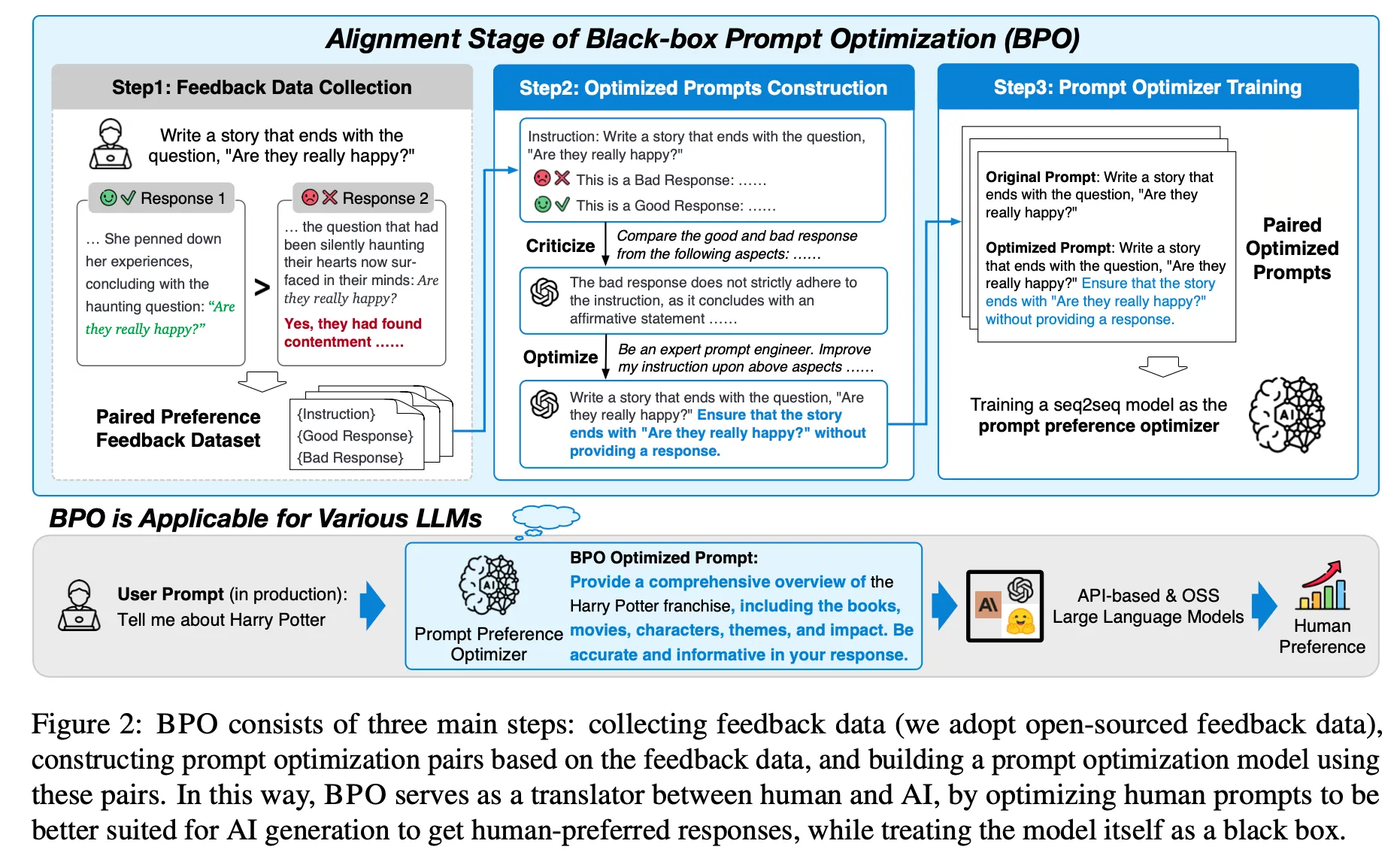
학습 데이터 세트 구축
▪
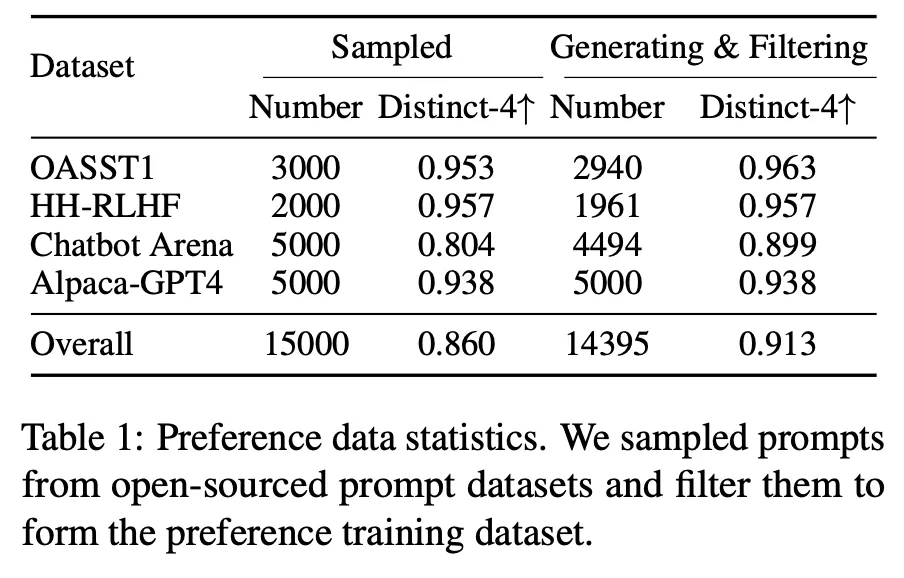
4가지 데이터 세트(OASST1, HH-RLHF, Chatbot Arena, Alpaca-GPT4)으로부터 (user input, good response, bad response) triplet을 추출
▪
추출한 정보를 바탕으로 아래의 프롬프트를 구성하고 ChatGPT를 통하여 더 좋은 instruction을 생성. 총 14,395 pairs

◦
Prompt 생성 모델 학습
▪
(user input, optimized input)의 pair 데이터를 활용하여 아래 objective function으로 PLM을 튜닝하여 최적화된 instruction을 생성할 수 있는 모델을 학습. 논문에서는 llama2-7b-chat 모델을 백본으로 사용하였음
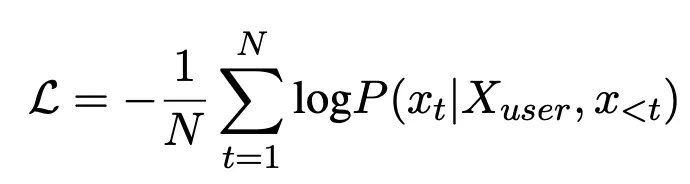
결과
•
APE
◦
Instruction Induction tasks, BIG-Bench 실험
◦
Greedy prompt 및 human prompt 대비 성능 향상 관찰
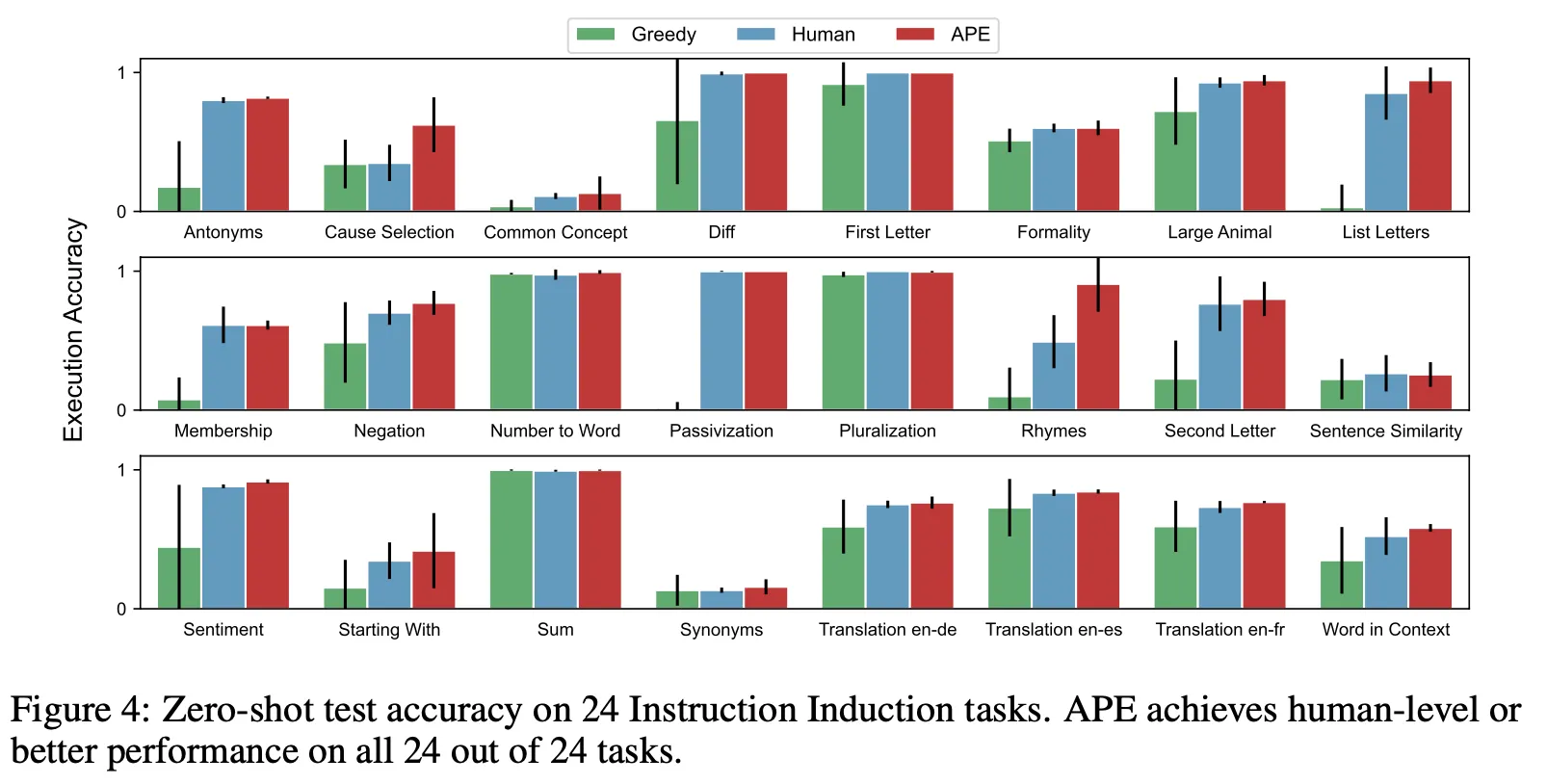
•
iPrompt
◦
FFB, Rotten Tomatoes, SST-2, IMDB 실험
◦
Human prompt 및 비교 대상인 AutoPrompt 대비 성능 향상 관찰
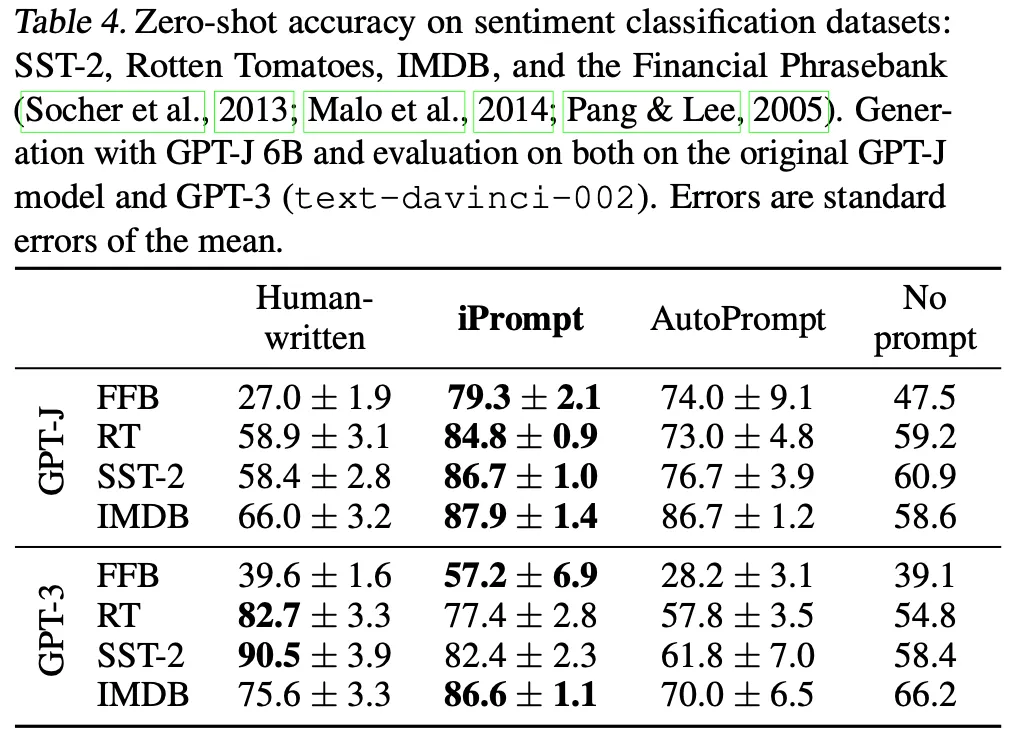
•
Auto Instruct
◦
LLM이 좋은 instruction을 생성할 능력을 가지고 있음. 그렇지만 적절한 ranking은 필수
▪
아래 표에서 empty instruction, human instruction, on-the-fly generation 비교
▪
LLM이 생성하는 방법론들이 human instruction 및 empty instruction 점수를 넘는 경우가 존재
▪
그렇지만 잘못 선택할 경우 성능이 더 낮아지기도 함
◦
Instruction의 품질을 판단하기에 제안한 ranking model이 가장 효과적
▪
Random Selection, iPrompt, iPrompt+, Cross-Validation, LM Selection, Auto-Instruct 비교
▪
생성한 instruction을 LLM을 통해 판단하거나 validation data를 활용하여 선택하는 것(iPrompt, cross-validation)은 오히려 random selection보다 더 낮은 성능을 보이기도 하는 등 reliable하지 않음
▪
반면 제안한 방법은 모든 경우에서 가장 좋은 성능을 달성
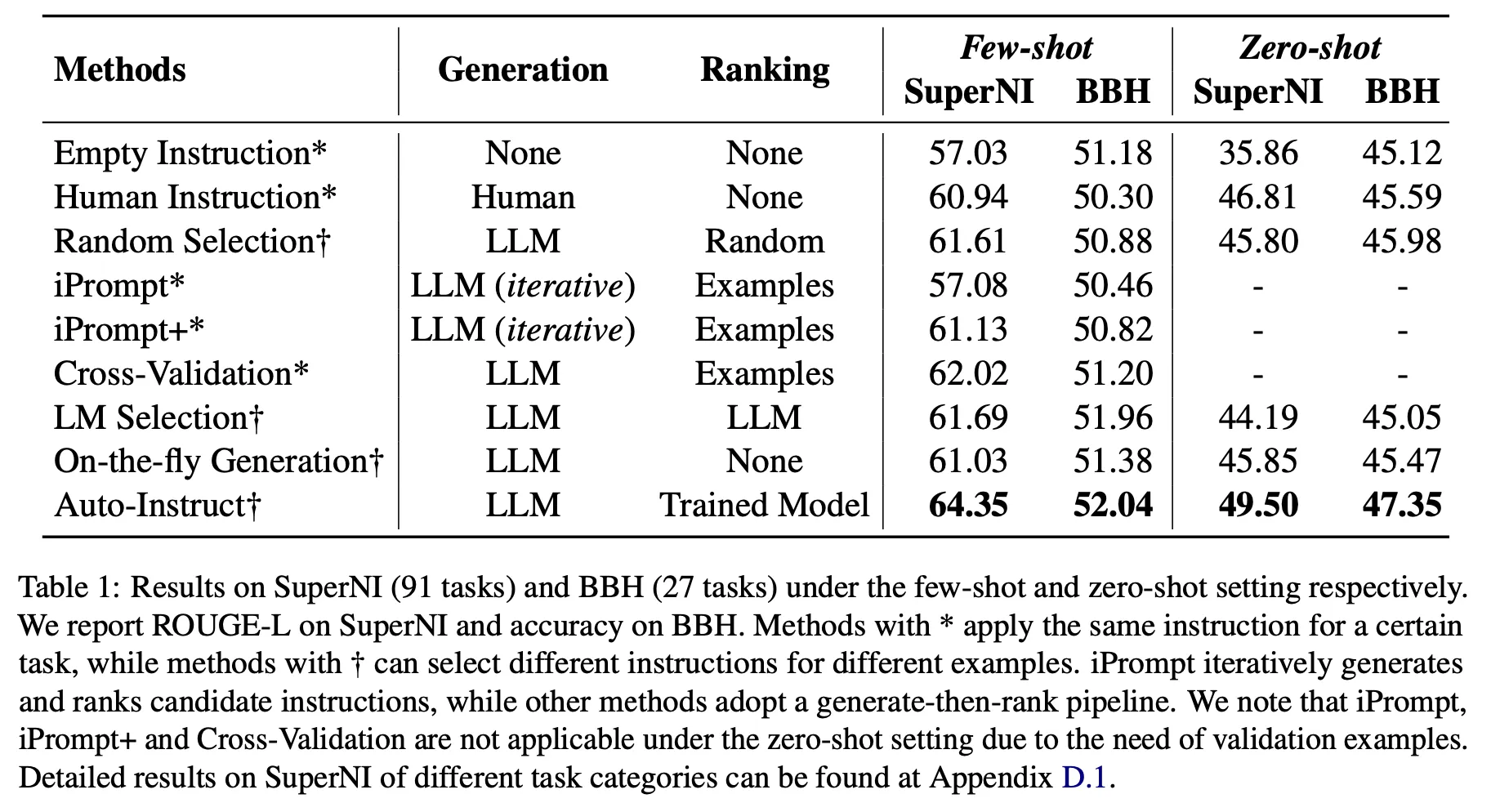
•
BPO
◦
실험한 공개 LLM API에서 모두 향상 효과가 있음
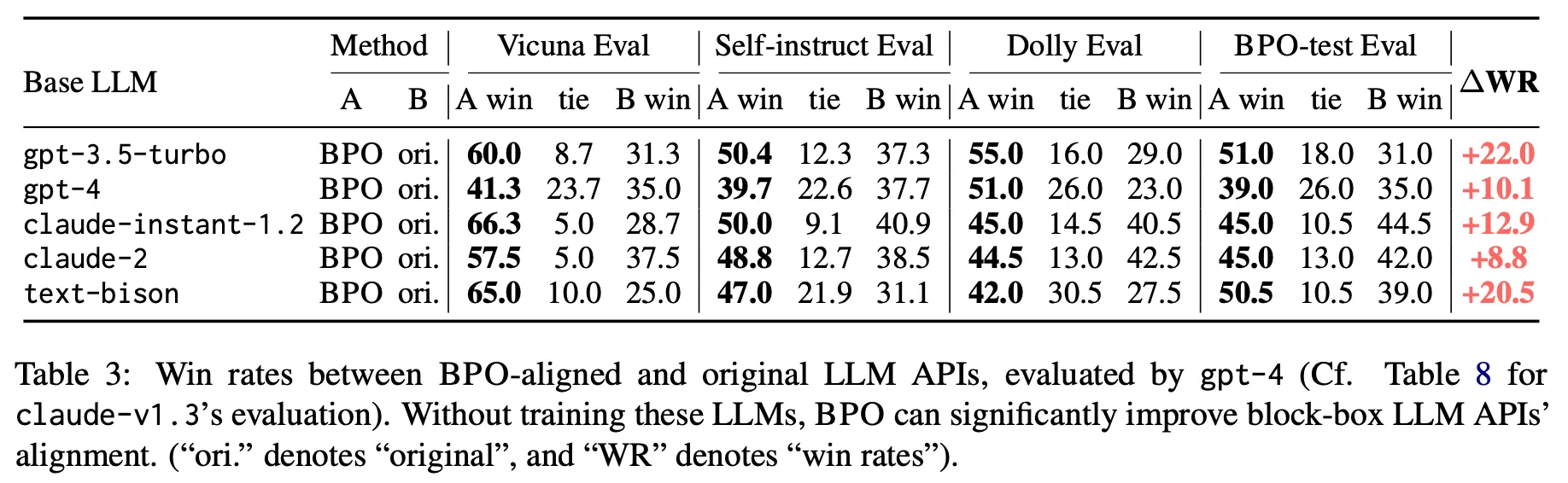
◦
LLaMA 2와 Vicuna 에서 모두 향상 효과가 있음. 특히 13B+BPO가 70B original 보다 모든 케이스에서 모두 성능이 좋다는 점은 주목할만 함. 즉, Prompt 최적화를 통하여 기대할 수 있는 개선 폭이 꽤 크다는 것을 알 수 있음
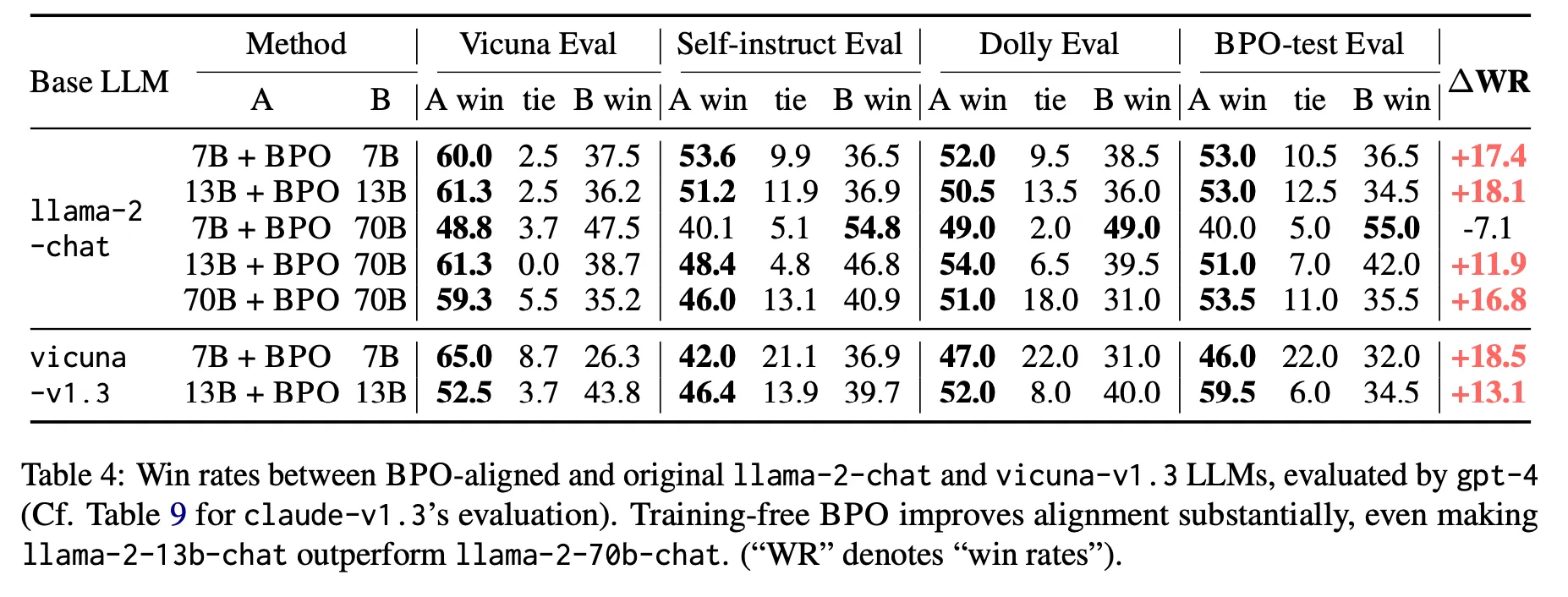
◦
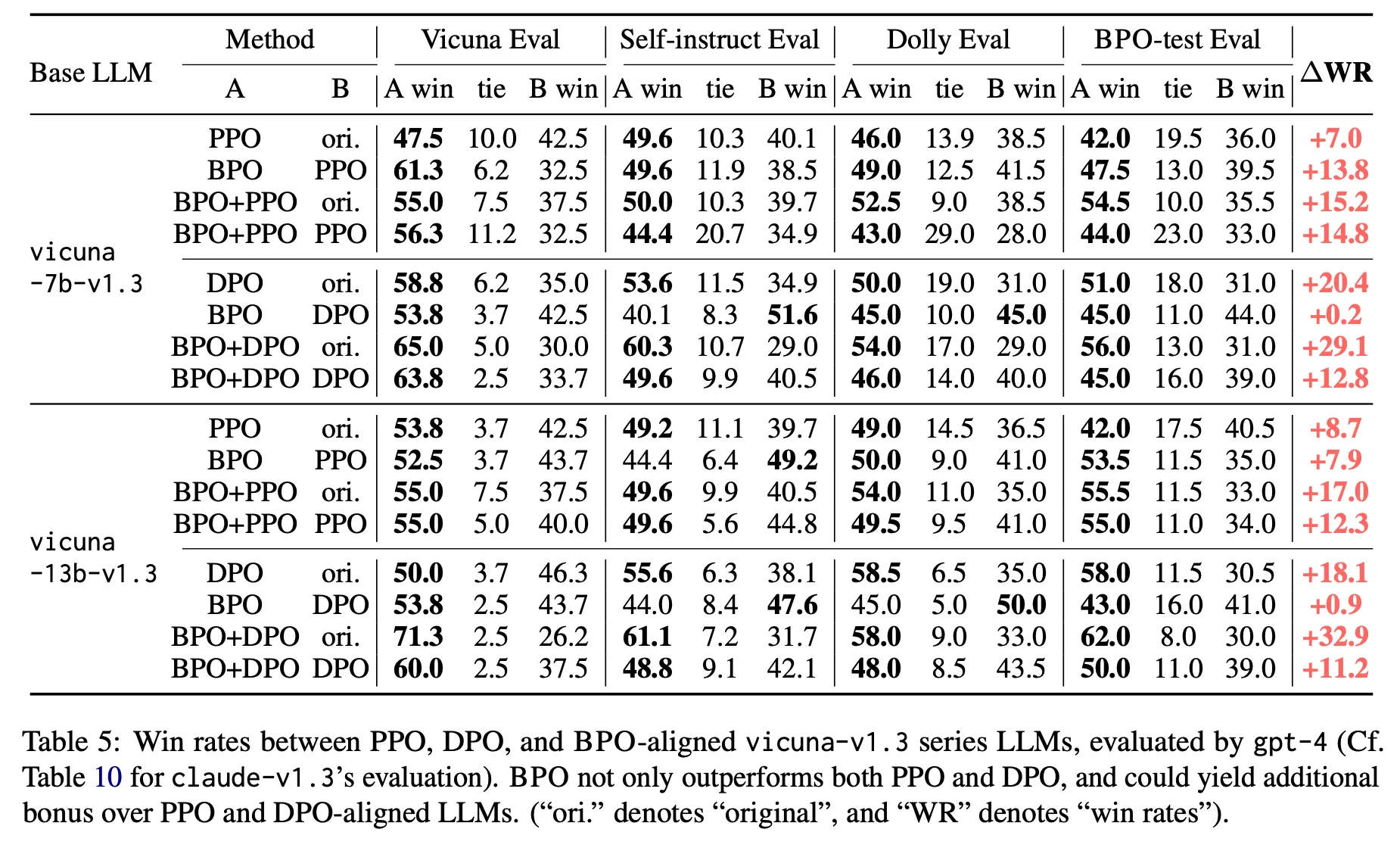
PPO 및 DPO 등과 비교했을 때 보다 더 좋은 성능을 보이며 이것과 조합했을 때 추가적인 개선이 있음
논의사항
•
사실 특정 task에서 잘 동작하는 프롬프트를 만드는 것은 매우 막막하고 어려운 문제로 위 방법론 모두 task에 맞는 최적의 prompt를 자동으로 생성하는 것이 목적
•
APE & iPrompt
◦
비슷한 시기에 공개된 거의 동일한 접근 방법. 새로운 프롬프트 후보를 생성하는 방식에서 약간의 차이가 존재
◦
특별히 tuning 과정 없이 prompt 생성 및 성능 예측 모두 LLM의 ICL 능력을 활용하는 간단한 방법
◦
다만 Auto Instruct에서 지적하였듯이 단순한 meta prompt로 여러개 instruction을 생성할 때 다양성이 떨어질 수 있는 이슈는 있음
◦
또한 iPrompt의 경우 초기 논문임을 감안하더라고 prompt 생성에 GPT-J를 사용한 부분은 아쉬움
◦
LLM을 통한 prompt 자동 생성의 초기 연구로 LLM을 통하여 적어도 적당한 수준의 human prompt 혹은 그 이상의 성능을 얻을 수 있음을 보여줬다는 것에 의의가 있음
•
Auto Instruct
◦
주어진 task에 대하여 어떤 instruction이 효과가 있을지 판단하는 instruction ranking 모델을 제안하고 유효성을 입증한 것이 가장 인상적
◦
다만 이 모델이 일반화될 수 있는지 여부가 이슈. 만약 다른 언어와 unseen task에 대하여 일반화된다면 매우 유용할 것으로 판단
•
BPO
◦
Task description수준의 간단한 input을 최적의 prompt로 자동으로 생성하는 모델이 key contribution이라 판단
◦
특히 13B+BPO로 70B 성능을 뛰어넘은 점, BPO가 PPO 대비 성능이 더 좋다는 점 등이 인상적
◦
다만 별도의 instruction ranking 단계 없이 ChatGPT가 생성한 instruction을 거의 무조건 optimized prompt로 간주하는 것 같은데 이 과정이 얼마나 reliable할지 의문