

배경
드라마 ‘스타트업’에서는 눈이 보이지 않게 된 어머니를 위해 전경을 설명해 주는 AI가 등장한다. 이미지 캡셔닝(Image Captioning)은 이와 비슷하게 입력으로 사진이 들어가면 출력으로 그 사진에 있는 이미지를 바탕으로 자연어 문장을 생성하는 작업을 의미한다.
주요 데이터
1.
MS COCO (Microsoft Common Objects in Context)
•
약 33만 개의 이미지와 5개의 캡션이 제공되고 이미지 캡셔닝 연구에 가장 널리 사용되는 데이터 세트이다.
2.
Flickr30k 및 Flickr8k
•
Flickr30k는 31,000개, Flickr8k는 8,000개의 Flickr에서 수집한 이미지와 각 이미지당 5개의 캡션이 제공된다.
3.
Visual Genome
•
이미지의 안에 있는 세부 객체 간의 관계와 속성 정보가 제공된다.
4.
•
시각 장애인들이 촬영한 약 39,000개의 이미지로 구성되어 있으며, 각 이미지에 5개의 캡션이 제공된다.
5.
•
웹에서 수집한 대규모 이미지-캡션 쌍으로 구성된 데이터 세트이다.
주요 과제와 입출력 형식
이미지가 사용되기 때문에 이미지의 해상도와 이미지 내에 있는 정보의 구조적 전달을 위한 언어 모델의 성능이 모두 중요한 과제라고 할 수 있다. 최근 CVPR 2024 NICE 이미지 캡셔닝 챌린지에서는 Shutterstock의 이미지를 대상으로 EVA-CLIP 모델과 Adaption Re-ranking 방법을 사용하여 이미지-캡션 쌍의 품질을 향상시킨 결과를 보고하기도 했다.
한국어에서 문자가 포함된 이미지 기반 문장 생성(이미지 캡셔닝) 과제
사람의 눈과 같은 역할을 한 비전 모델이 이미지의 주요 정보를 읽어 오면 언어 모델은 이미지의 내용을 설명하게 된다. 다음은 (주)teddysum에서 공개한 이미지에 대한 예시이다.

"output": [
"2인승이라고 적혀 있는 하늘색 테두리 안내판 옆에는 다양한 색깔의 우산들이 띄워져 있다.",
"다양한 색깔의 우산들이 띄워져 있는 곳 옆에는 2인승이라고 쓰인 하늘색 테두리 안내판이 있다,",
"다양한 색깔의 우산이 띄워진 곳 옆에 있는 하늘색 테두리 안내판에는 2인승이라고 적혀 있다.",
"하늘색 테두리 안내판에는 2인승이라고 적혀 있는데, 그 옆에 띄워져 있는 것은 다양한 색깔의 우산들이다.",
"안내판은 하늘색 테두리에 2인승이라고 적혀 있으며, 그 옆에 띄워져 있는 것은 다양한 색의 우산들이다."
Plain Text
복사
위의 예에서 볼 수 있는 것처럼 이미자와 문자를 모두 이해하고 이 둘을 연결하여 자연스러운 문장을 생성하는 것이 특징이다. 따라서 국립국어원에서 진행 중인 경진대회 중에서도 도전적인 과제에 포함된다.
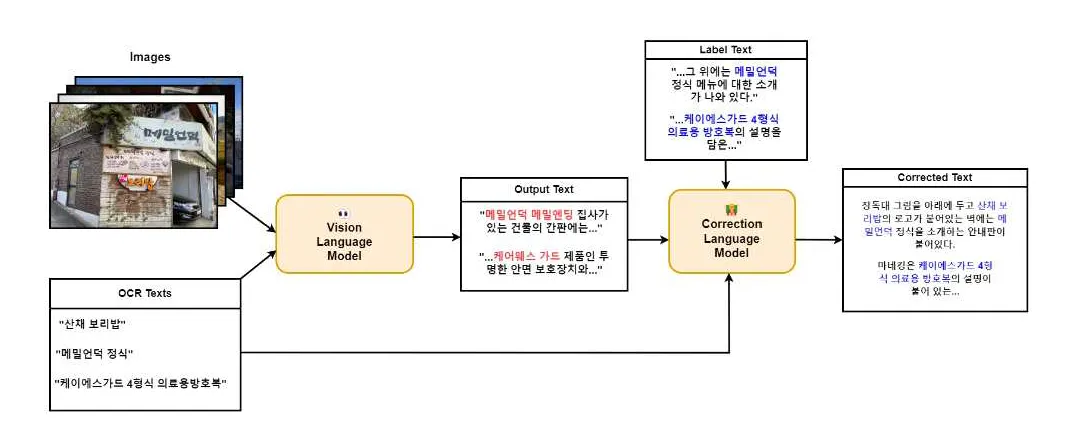
대회에 참여한 유용상, 이기훈 ,임형준(2024), 한국어 이미지 캡셔닝 향상을 위한 유창성 개선 모듈, 한글 및 한국어 정보처리 & 한국코퍼스언어학회에서는 멀티 모델을 시각 인식 단계, 비전 언어 통합 단계, 정밀 보정 단계로 분할하여 단계별로 성능 향상을 꾀하고 있다. 다음은 유용상 외(2024)에서 제안한 모듈이다.
위의 모델 외에도 알려진 모델로는 다음과 같은 것들이 있다.
멀티모달 모델
•
KoLLaVA : 한국어 시각 인스트럭션 데이터셋으로 학습된 CLIP(ViT-14)의 시각 인코더에 LLM(KoVicuna)을 결합한 대규모 다중모드 모델(LMM), 한국어 이미지 캡셔닝에 특화
•
•
•
InstructBLIP : BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models 에서 발전한 오픈소스 모델로 사전 훈련된 BLIP-2 모델을 기반으로 시각 언어 명령어 튜닝을 한 모델
•
•
MiniGPT-4 : King Abdullah University of Science and Technology에서 오픈소스로 공개, BLIP-2의 시각 인코더와 Vicuna라는 오픈소스 LLM을 결합한 멀티모달 모델
•
CLIP :OpenAI에서 개발한 모델로 Image Encoder와 Text Encoder를 Contrastive Learning 방법과 제로 샷 방식으로 임의의 이미지 분류 작업에 일반화할 수 있는 모델의 능력을 테스트하기 위해 개발되었다고 한다.
Further Analysis
문자가 포함된 이미지 기반 문장 생성은 발전하고 있는 분야인 만큼 협업을 해야할 과제들이 많이 남아 있다. 가령, 모델 성능 향상에서도 OCR, 이미지 인식, 프롬프트 튜닝 기술을 포함하는 자연어 생성 능력 등이 세부적으로 발전하여야 하며, 언어권별로 문화적 특성이 반영되어야 할 것이다. 이미지는 텍스트에 비해서 용량이 크기 때문에 실시간 처리를 위한 기술 등도 추가로 고려되어야 한다.
참고 링크
2024년 진행 중 문자가 포함된 그림(사진) 기반 문장 생성
2023년 그림(사진) 기반 문장 생성 과제