
개요
•
LLM의 alignment를 학습시키는 효과적인 방법으로 human feedback(or preference data)를 활용하여 reinforcement learning (RLHF)을 수행하는 것이 일반적
•
특히 DPO의 경우 기존 방식과는 다르게 별도의 Reward Model을 만들 필요 없이 바로 학습할 수 있는 방법으로 최근 alignment learning에 널리 사용되고 있음
•
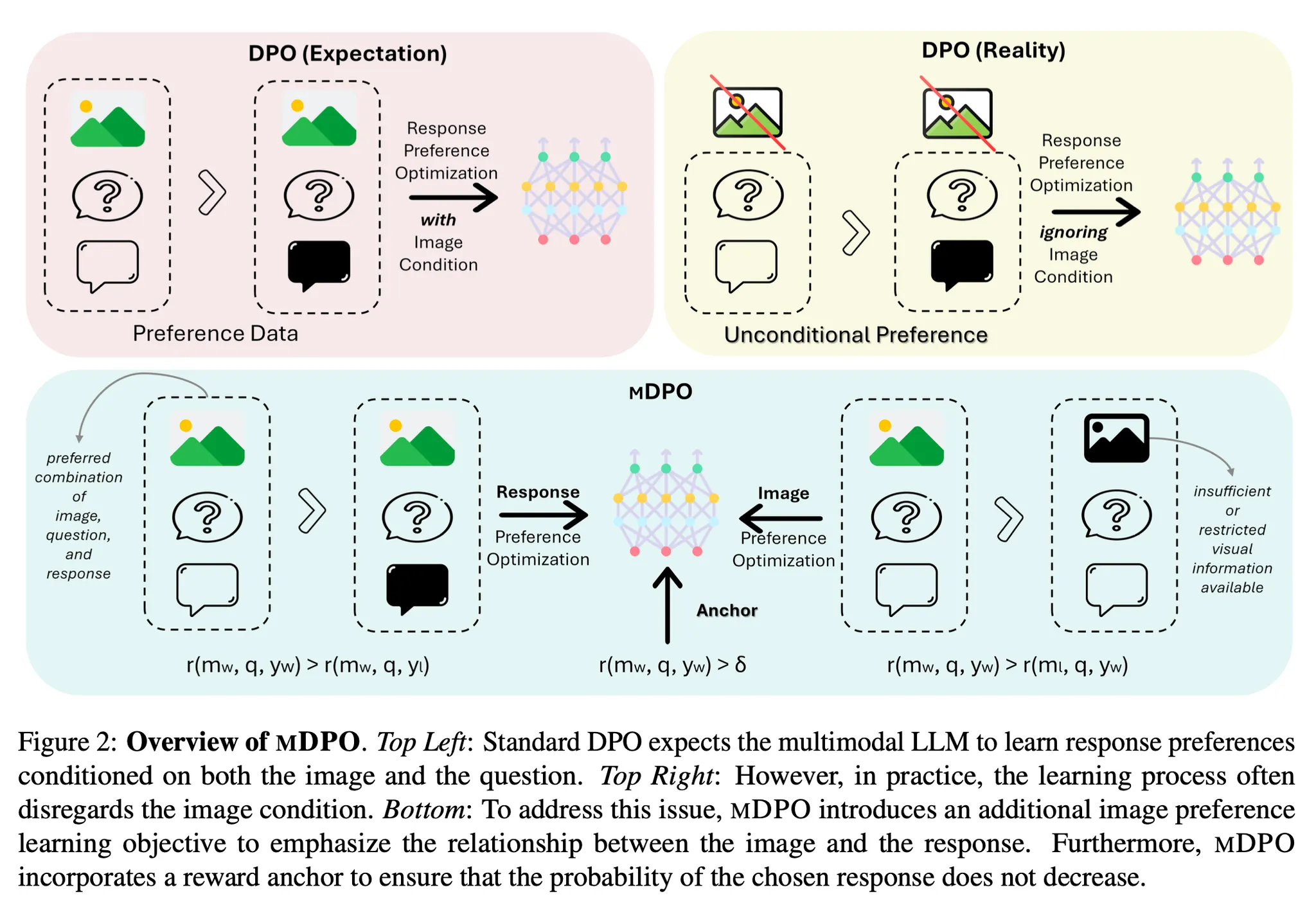
그렇지만 DPO를 multimodal 상황에 그대로 적용했을 때 의도한 만큼의 성능 향상을 얻지 못하는 경우가 종종 발생
•
이 논문에서는 multimodal 상황에서 기존의 DPO가 의도한 효과를 보이지 못하는 unconditional preference problem에 대하여 분석하고, 이것을 개선할 수 있는 multimodal DPO를 제안함
•
Method
•
제안 방법 이름 : mDPO(multimodal DPO)
•
DPO : winning reward와 rejected reward 사이의 차이를 maximize하는 방식으로 preference data를 직접 학습하는 기법
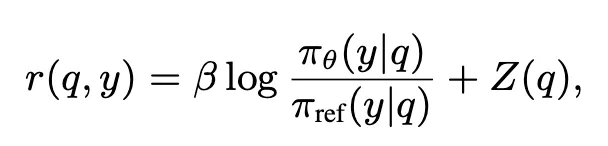
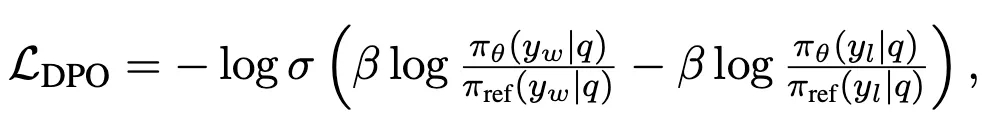
•
DPO를 multi-modal LLM에 적용하는 경우 종종 기대했던 성능 향상이 나타나지 않는 경우가 발생하며, 주로 preference data의 품질 이슈로 인한 현상이라 의심해 왔음
•
그러나 실제로 분석한 결과 preference data 중 visual input을 제대로 활용하지 못하는 'unconditional preference' 현상(preference data 중 보다 쉬운 텍스트 신호를 중심으로 학습하고 보다 어려운 이미지 신호를 무시하는 현상)이 나타남
•
2가지 제안 방법 : Conditional Preference Optimization, Anchored Preference Optimization
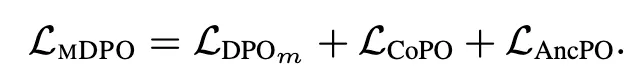
◦
CPO : winning data에서 이미지 일부를 제거(20% 이하로 cropping)한 형태의 rejected data를 생성하여 preference dataset을 구성하고 학습에 활용. 해당 objective를 추가
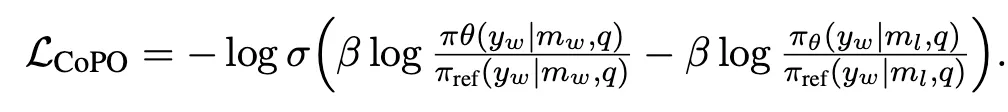
◦
APO : 기존 DPO의 경우 relative preference만 학습하기 떄문에 간혹 선택된 답변의 likelihood가 낮은 경우가 존재. 이것을 보완하기 위하여 적어도 선택된 답변의 likelihood가 특정 anchor value 보다는 높은 값을 갖도록 유도하기 위한 objective 추가
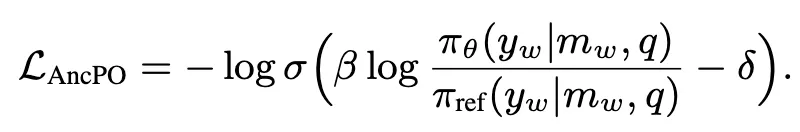
Results
•
사용 모델 : Bunny-v1.0-3B, LLAVA-v1.5-7B
•
Preference dataset : Silkie 데이터 중 10K
•
Evaluation dataset : MMHalBench, Object HalBench, AMBER
•
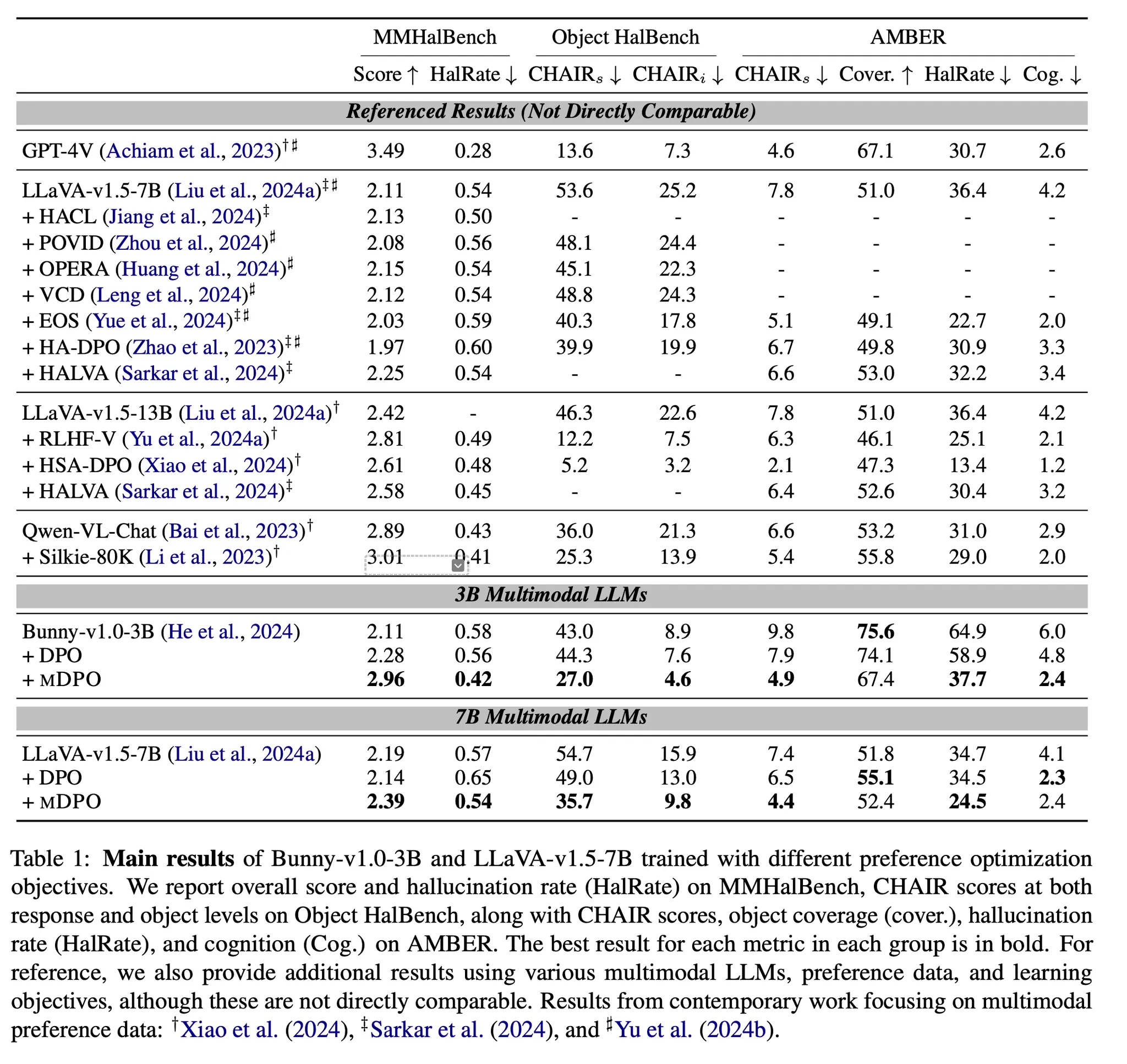
Main results
◦
DPO를 적용한 경우 Bunny는 전반적으로 향상되었으나 LLaVA는 MMHalBench 등에서는 오히려 성능이 하락하기도 함
◦
mDPO는 일관적으로 성능 향상이 관찰되며, DPO대비 더 뛰어남. Coverage는 다소 감소하는 경향이 있지만 특히 hallucination 감소에 효과가 두드러짐
◦
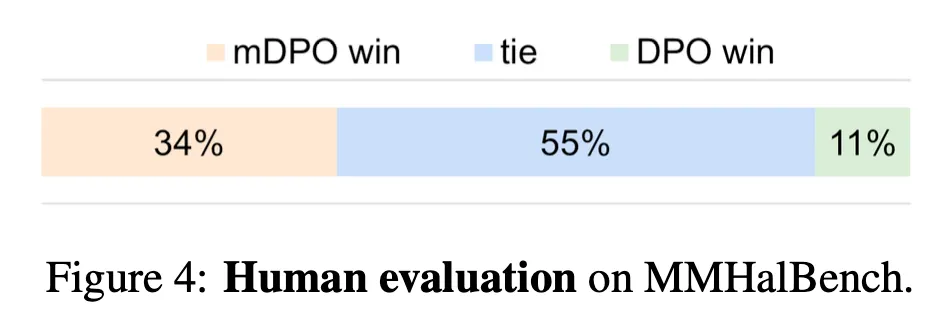
사람 평가에서도 DPO 대비 더 우수함
•
Examples

Further Analysis
•
다양한 크기의 preference data에서 모두 효과적이며 특히 데이터가 많을수록 효과가 두드러짐

•
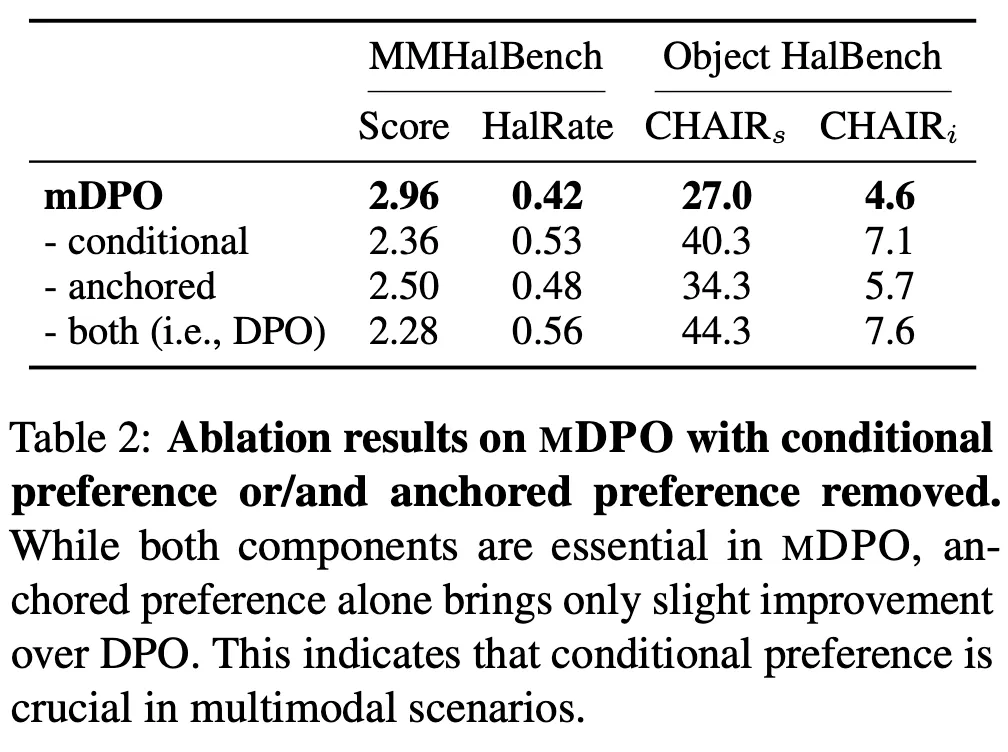
CPO 및 APO 모두 긍정적인 영향을 미치며, 둘 중에서는 CPO가 더 큰 효과를 보임 (tab2)
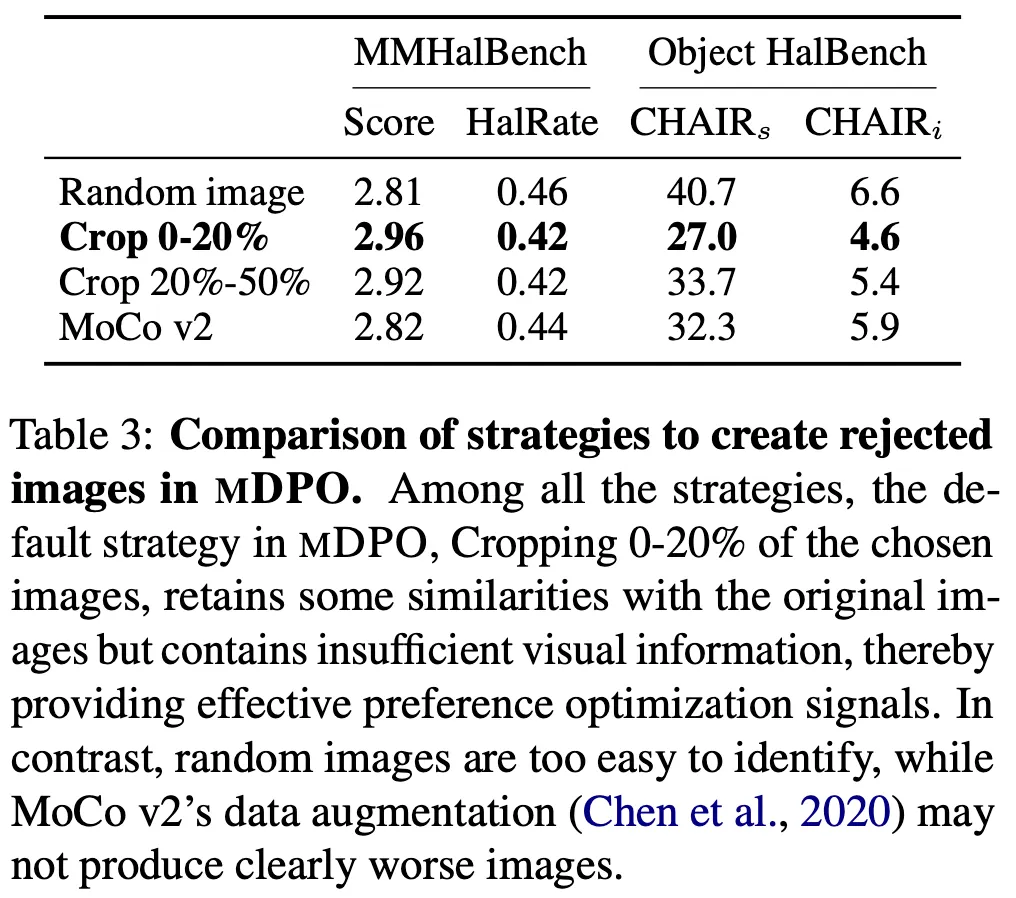
•
CPO 데이터셋을 만드는 전략에 따른 성능 비교. 아예 랜덤 이미지를 사용하거나 너무 많이 cropping하면 변별력이 낮은 데이터가 되기 때문에 0-20%가 가장 높은 성능인 것으로 보임
•
기존의 winning result, y_w 뿐 아니라 y_l, m_l 등에 대해서 추가 anchor를 도입해도 크게 도움이 되진 않음. 즉, y_w에 대한 ancher만으로 충분함
