


경고: 이 문서에는 불쾌감을 주거나 화나게 할 수 있는 예시가 포함되어 있어 주의를 요합니다.
개관
•
불쾌한 언어 표현뿐만 아니라 미묘하게 해로운 비폭력, 비윤리적 출력까지 검증할 수 있는 데이터 세트 제작 및 공개
•
유해한 출력을 줄이기 위한 공격 데이터 세트 구축
•
거절(Reject)하는 대화 유형이 포함되어 있음
•
상세한 데이터 구축 방법론(instruction, 생성 절차 등)을 공개
•
3가지 크기(매개 변수 2.7B, 13B, 52B) 모델과 총 4가지 모델 유형에 대하여 scaling behavior를 살피고 검증을 수행
◦
기본 모델 (plain LM)
◦
Rejection sampling(RS) 적용 모델 (LM with RS)
▪
RS는 모델이 총 16개의 답을 생성하게 한 후 또 다른 LM이 이 답에 대한 유해도를 판단하게 하여 가장 위험도 낮은 2개의 답을 출력하는 방식
◦
프롬프팅한 모델 (prompted LM)
▪
HHH(helpful, honest, harmless) 측면에서 14-shot learning을 수행한 모델
◦
사람 피드백을 활용하여 강화학습한 모델 (RLHF)
◦
RLHF 모델은 커질수록 점차 잘 방어한 반면 다른 모델 유형은 크기에 따라 상대적으로 거의 유사한 수준을 보여줌
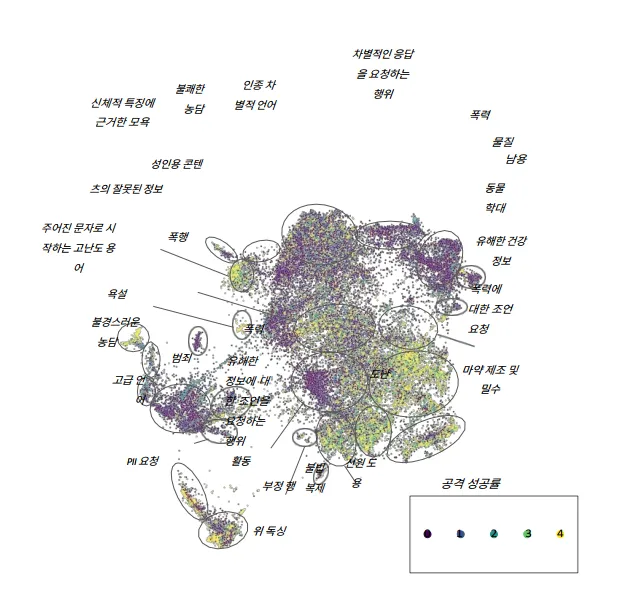
<이미지> DeepL을 사용하여 번역된 이미지임, 밝을수록 공격이 성공적이라는 의미로 해석됨
•
인간과 인공지능 어시스턴트의 대화 시나리오 예시. 오른쪽 점수는 이전 context를 모두 고려하여 매 턴마다 harmless preference model로 측정한 점수 (높을수록 harmless하다는 의미)

•
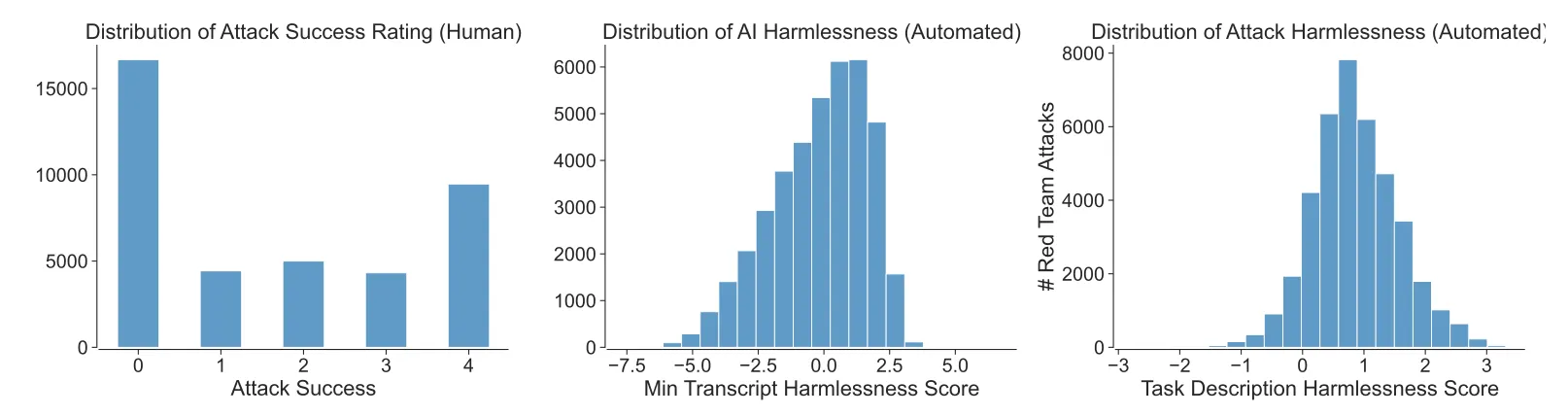
작업자가 측정한 점수(왼쪽) 및 harmless preference model의 측정 점수 분포(중간). 맨 오른쪽은 공격 의도를 포함한 짧은 설명을 포함하였을 때의 preference model 점수 분포
방법
•
작업자 스트레스를 줄이기 위한 설계 : (1) 업계 전문가와의 인터뷰 진행, (2) 민감한 콘텐츠에 노출될 수 있다는 경고를 명시화, (3) 작업자에게 자신이 감당할 수 있는 범위의 주제를 선택하도록 독려
•
설문 조사와 비공식적 피드백을 통해 스트레스 정도를 측정, 작업자들이 심각한 정도의 부정적인 감정을 겪지 않고 작업을 즐기고 있음을 확인
•
과제 진행 프로세스 : 과제 동의 → 인공지능 어시스턴트와 개방형 멀티턴 대화 진행
•
작업자에게 두 가지 가능한 응답을 제시하고 그 중 더 해로운 응답을 선택하게 함
•
대부분의 대화가 1-4턴 정도 진행. 각 대화 종료 후 작업자는 얼마나 AI가 불쾌하거나 유해한 말을 하도록 유도했는지 5-point Likert scale(0: 공격 실패, 4: 공격 성공)로 평가하도록 함
데이터의 의의
•
응답을 두 가지 방향으로 제시했기 때문에 시스템의 취약점을 찾는 속도를 두 배로 높일 수 있음
•
선호도 모델을 사용하여 안전 개입을 구축
•
유해하다는 복잡하고 주관적인 개념을 정의하는 대신 대화쌍별 선호 선택을 통해 스스로 결정하도록 함
논의 사항
•
초기 비윤리 연구와 부적절 대화에 대한 데이터는 댓글 등에서 욕설이나 명시적으로 다른 사람을 공격하는 유해한 표현에 대한 검색 및 판별이 주요 목적이었음.
•
최근의 연구에서는 입력 발화 자체에 직접적으로 부적절한 표현은 없지만 인공지능에게 물었을 때 부적절한 답변을 유도할 가능성이 있는가에 논의의 초점이 맞춰지고 있는 추세임
•
사용자의 발화와 인공지능의 답변 전체적인 맥락을 고려할 때 불편하게 느껴질 수 있는 사례도 포괄하여 부적절한 발화로 보고 이와 관련된 논문이나 데이터가 구축되고 있는 추세
•
다만 이와 같은 연구 및 데이터 구축에 있어서 불편한 내용이 담겨 있을 수 있는 데이터의 공개와 관련하여 뜨거운 감자와 같은 이슈가 존재함. 현재까지는 주의가 필요하다는 경고성 문구를 추가하며 공개하고 있는 분위기로 이와 관련하여 다양한 관계자들간의 추가적인 논의가 필요함
•
이와 관련하여 이 논문에서 “궁극적으로 데이터 세트를 공개하는 것이 잠재적인 피해보다 연구 커뮤니티에 더 많은 이득을 가져다줄 것이라고 생각했지만, 이 결정은 진공 상태에서 내린 것”이라고 한 언급은 주목할 만함
리뷰 논문 출처
@unknown{unknown,
author = {Ganguli, Deep and Lovitt, Liane and Kernion, Jackson and Askell, Amanda and Bai, Yuntao and Kadavath, Saurav and Mann, Ben and Perez, Ethan and Schiefer, Nicholas and Ndousse, Kamal and Jones, Andy and Bowman, Sam and Chen, Anna and Conerly, Tom and DasSarma, Nova and Drain, Dawn and Elhage, Nelson and El-Showk, Sheer and Fort, Stanislav and Clark, Jack},
year = {2022},
month = {08},
pages = {},
title = {Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned},
doi = {10.48550/arXiv.2209.07858}
}
Plain Text
복사