


도입
•
LLM은 복잡한 추론 능력이 필요하거나 다양한 맥락을 이해하여 처리해야 하는 어려운 task에서도 매우 뛰어난 모습을 보여주고 있음
•
LLM의 이러한 능력을 모델이 생성한 답변을 스스로 평가하고 오류를 수정함으로써 성능을 향상시키고 hallucination을 줄여주는 ‘self-correction 방법론’에 대한 연구가 최근 활발하게 진행되고 있음
•
이 아티클에서는 self-correction 과정을 2단계로 세분화하고 최신의 LLM이 각각의 단계에서 어떠한 모습을 보여주는지에 대한 실험을 수행
•
•
BIG-Bench Mistake 데이터 세트 : https://github.com/WHGTyen/BIG-Bench-Mistake
개요
•
한줄 요약 : 현재의 LLM은 추론 과정 중 정확히 어디에서 논리적인 오류가 발생했는지를 찾는 능력은 떨어지나 적당한 수준의 피드백을 받으면 답변을 수정하는 능력은 있음
•
최근 LLM 기반의 self-correction 방법론은 AI 기술이 생성한 결과의 품질을 향상하고 안정성을 높이는 전략으로 큰 관심을 모으고 있음
•
그렇지만 특히 추론이나 논리적 오류를 수정하는 task들에서 종종 정답을 오답으로 바꾸어 성능이 오히려 하락하는 현상이 자주 보고되고 있음
•
이 논문에서는 self-correction 문제를 1) 오류를 찾고(mistake finding) 2) 결과를 수정(output correction) 하는 2가지 sub-task로 분리하고 각각의 문제에 대한 LLM의 능력을 측정
◦
BIG-Bench 데이터 세트를 기반으로 CoT 추론 과정에서의 논리적 오류를 검출하는 BIG-Bench Mistake 데이터 세트를 구축하고 공개. 다양한 LLM에 대한 성능을 측정
◦
오류에 대한 정보가 주어졌을 때 효과적으로 역추적하여 답변을 수정하는 방법론을 제안
BIG-Bench Mistake 데이터 세트
•
PaLM 2-L-Unicorn 모델로 Temperature=0으로 설정하여 생성한 총 2186개의 CoT 형식의 추론 trace로 구성
•
첫 번째 오류가 발생한 정보가 표시되어 있음

•
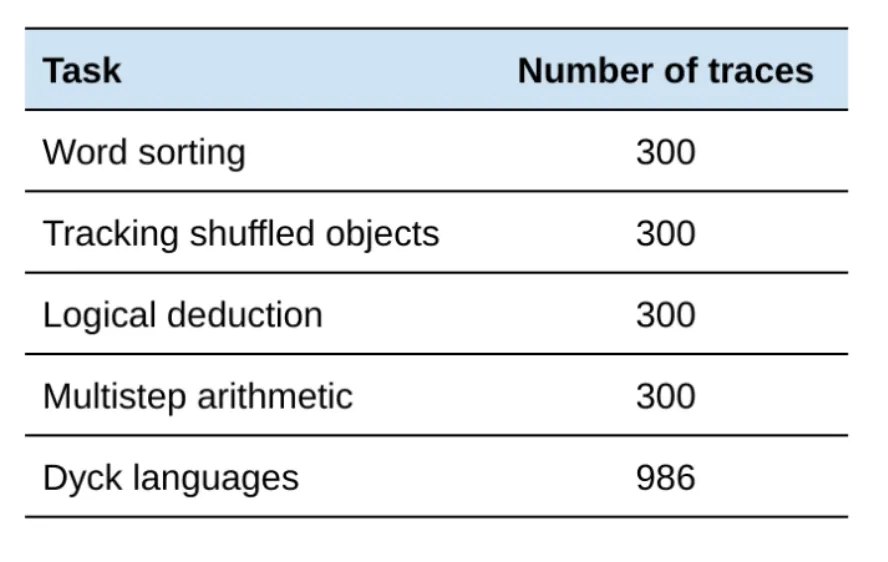
총 5가지 task에 대하여 구성 : word sorting, tracking shuffled objects, logical deduction, multi-step arithmetic, Dyck languages
•
Dyck languages를 제외한 4가지 task는 답변이 틀린 것 85%(255개)과 맞은 것 15%(45개)를 샘플링한 후 사람이 일일히 검수하여 어떤 step에서 오류가 발생하였는지 annotation을 수행
•
하나의 샘플에 대하여 최소 3명의 작업자가 작업을 수행
•
Dyck languages는 패턴 매칭을 기반으로 자동으로 annotation을 수행
LLM의 오류 검출 능력 실험
•
CoT 형태의 reasoning에서 logical error를 검출할 수 있는가?
◦
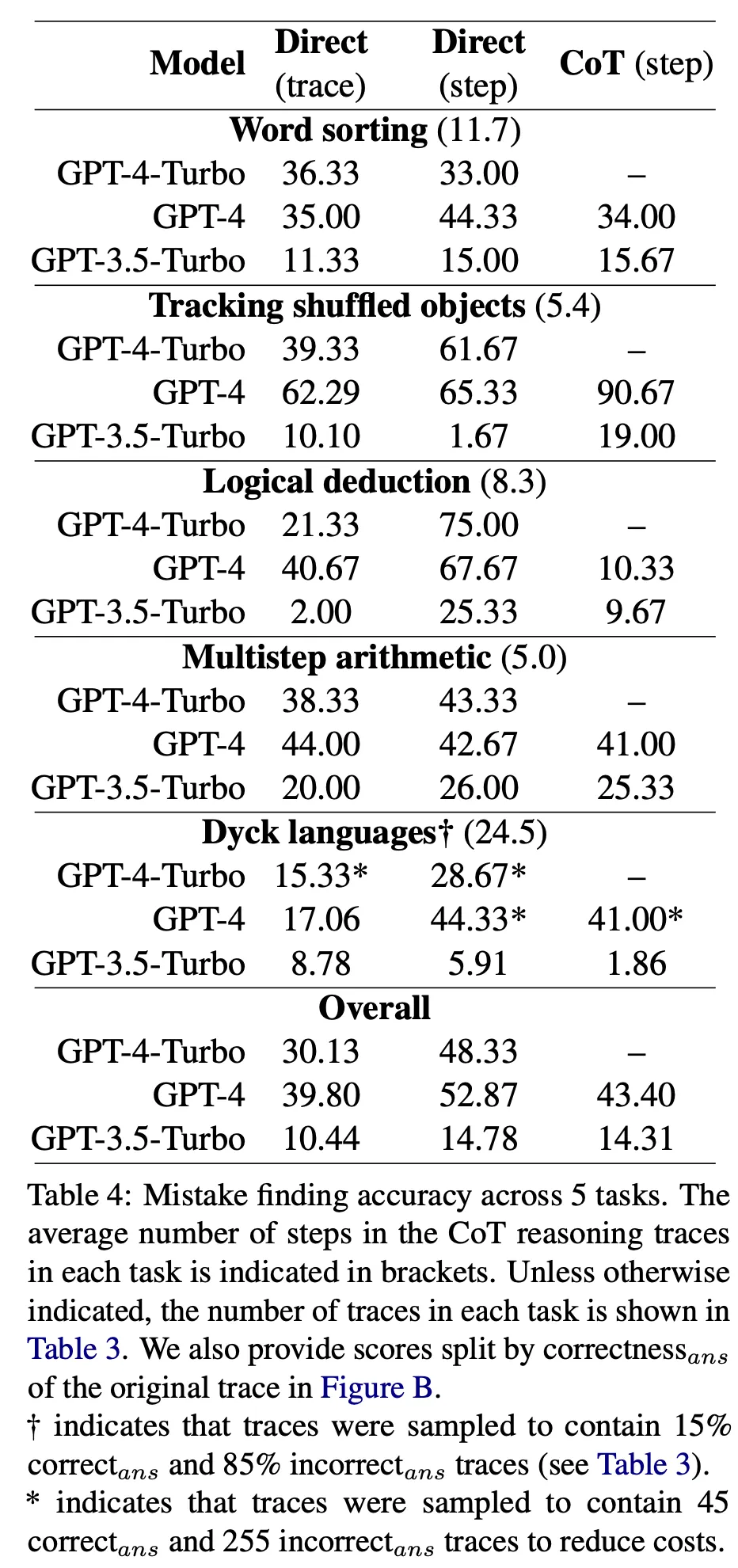
3가지 종류의 prompt를 사용 : direct trace-level, direct step-level, CoT step-level

◦
GPT-4가 평균적으로 가장 좋은 점수를 얻었으나 52.87점에 그침.
◦
LLM이 스스로 추론 과정의 오류를 검출하는 능력은 떨어진다는 것을 확인
◦
따라서 자동으로 수정하게 하는 것은 정답을 오답으로 잘못 수정할 위험이 존재하여 오히려 전체 성능이 떨어지는 경우가 발생할 수 있음
◦
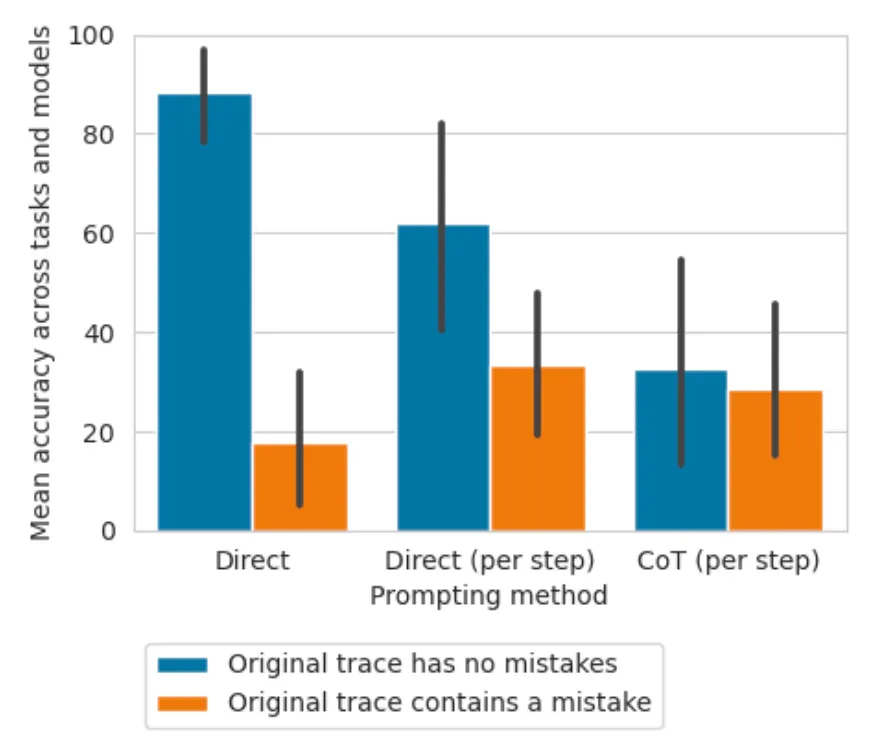
prompting 방법에 따른 성능 차이
◦
task 및 모델별 오류 검출 성능
•
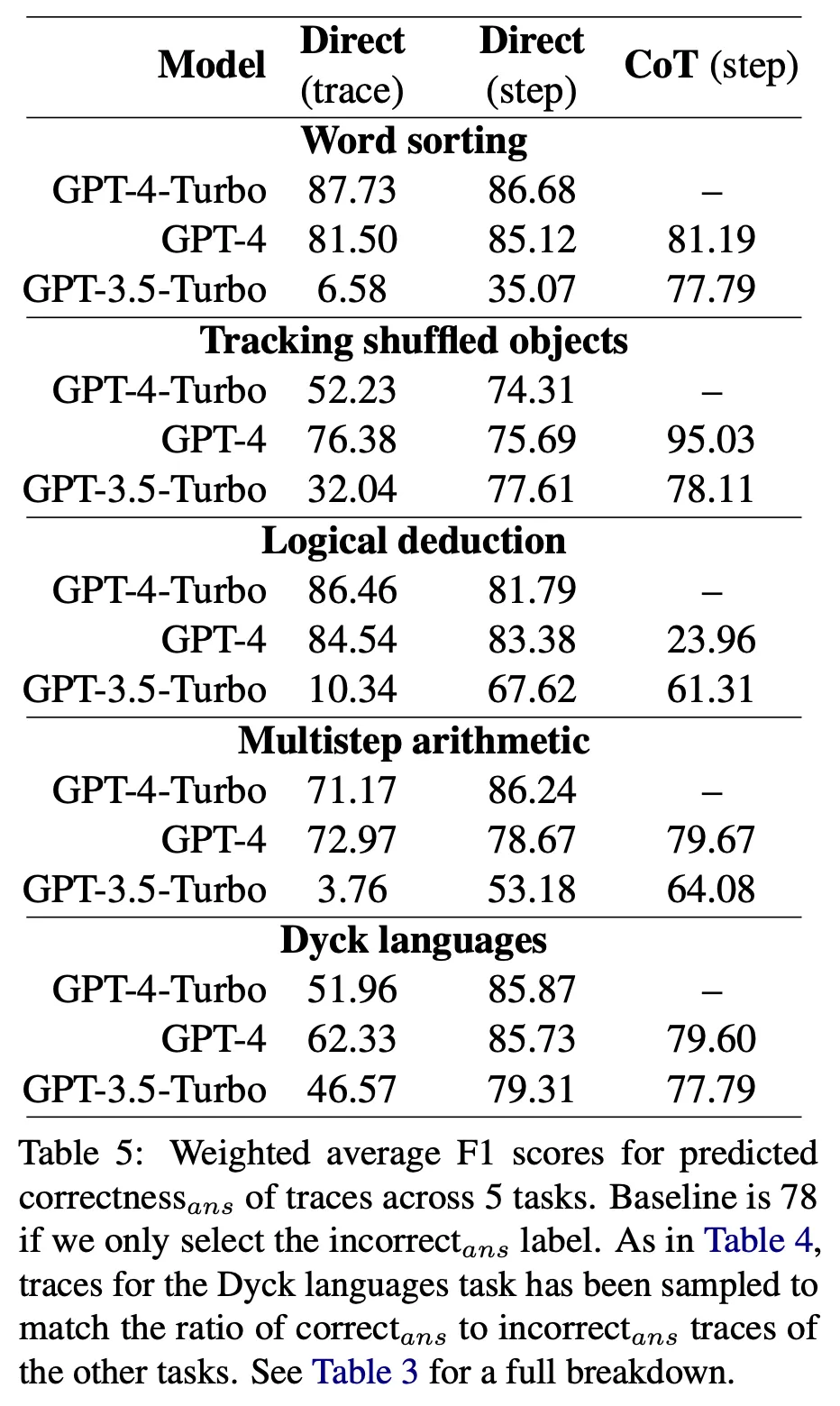
오류가 발생한 정확한 위치 대신 오답 여부를 판단할 수 있는가?
◦
각 label이 나타난 횟수에 기반하여 weighted F1 점수로 측정. 전부 틀렸다고 판단하면 78점임 (random baseline)
◦
가장 좋은 모델이 대부분 task에서 random baseline 대비 약간 더 좋은 정도로 신뢰할만한 성능을 보인다고 하기 어려움
LLM의 답변 수정 능력 실험
•
Backtrace 방법론
◦
Temperature를 0으로 설정하고 LLM이 CoT reasoning path를 생성
◦
어떤 step에서 오류가 발생했는지 판단
◦
오류가 발생한 step 직전까지의 내용을 입력으로 하고 temperature를 1로 조정하여 8개의 output을 다시 생성
◦
그 중 기존에 오류라고 이미 판단된 결과는 제거한 후 남은 것 중 가장 확률이 높은 것을 새로운 path로 선택
◦
새로 선택한 path 이후로는 다시 temperature를 0으로 설정하고 나머지 내용을 생성. 이 과정을 매 reasoning step마다 반복
•
LLM은 어디가 문제인지 알면 역추적하여 정답으로 수정할 수 있는가?
◦
제안한 backtrace 방법론이 유효한지에 대한 검증 목적
◦
Random location을 주입했을때 대비 훨씬 성능이 향상되며 전체 답변 품질도 향상. 즉, 효과가 있음
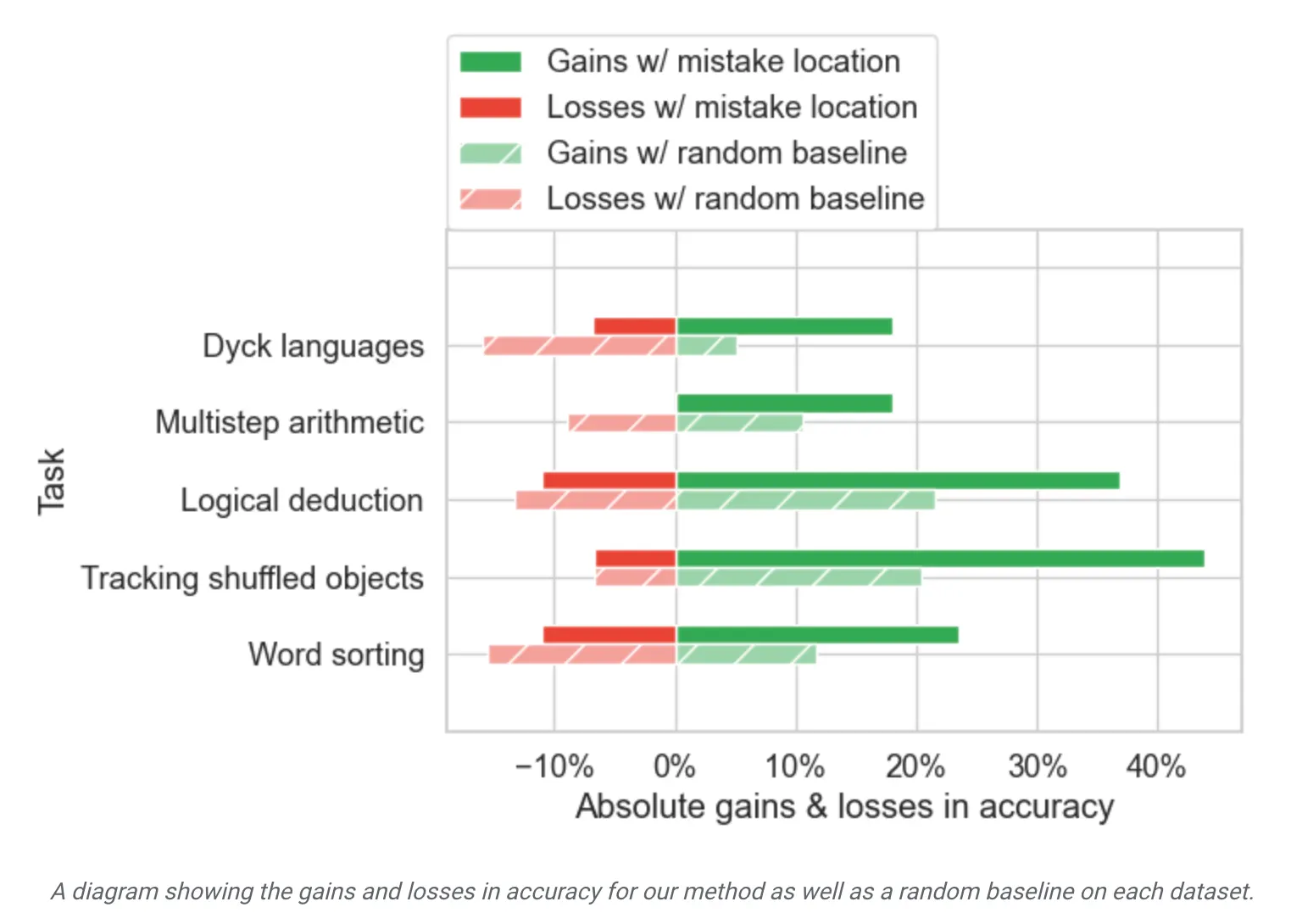
•
Oracle feedback이 없는 경우 얼마나 정확한 판단 모델이 있어야 효과가 있는가?
◦
일반적으로 위와 같은 oracle feedback은 얻을 수 없음. 따라서 오류 존재 여부를 판단할 수 있는 별도의 모듈이 필요함
◦
임의로 X% 정확도를 갖는 모델이 존재한다 가정하고 시뮬레이션.
◦
대략 60-70% 수준 이상부터는 모든 task에서 효과가 존재함
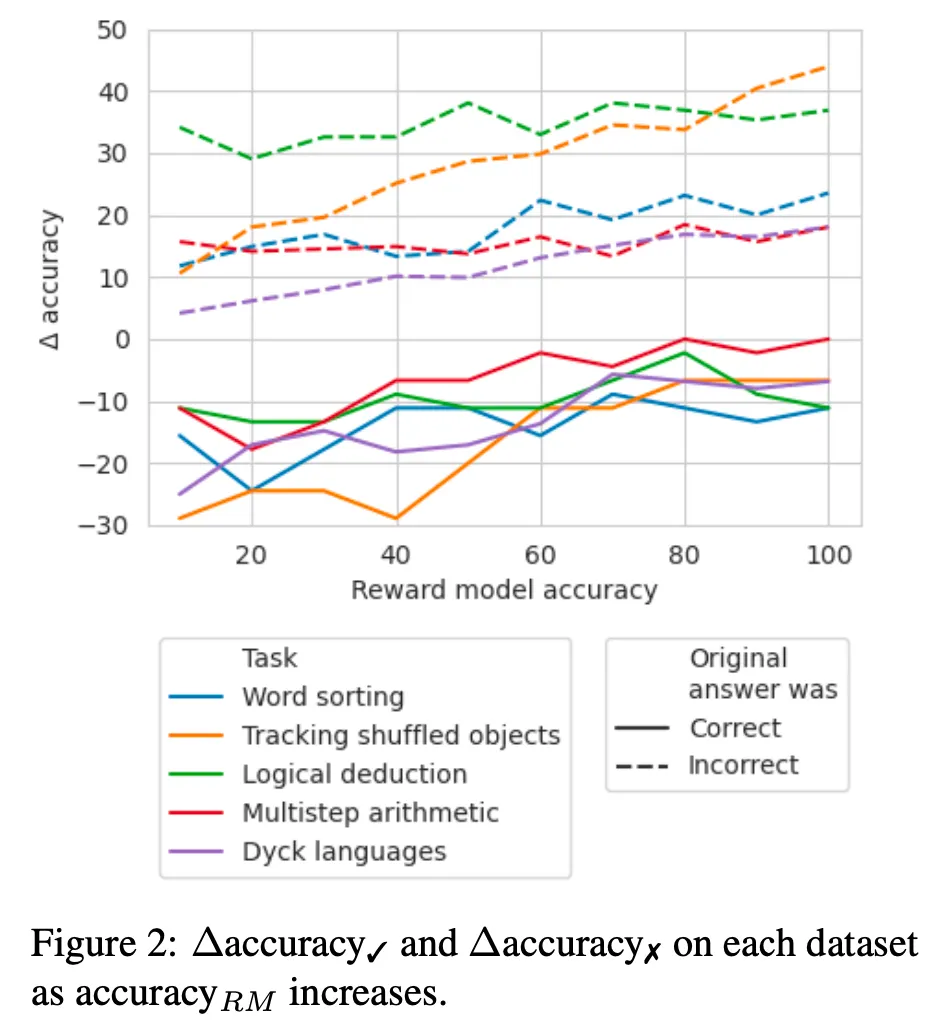
•
실수를 찾는 것은 일반화될 수 있는가?
◦
학습 시 보지 못한 task에서도 얼마나 정확히 오류를 판단하는지 확인 목적
◦
사용 모델 : PaLM 2-XS-Otter with finetuning
◦
비교 대상 모델 : PaLM 2-L-Unicorn with zero-shot prompting
◦
5개 task 중 하나씩 제외하고 학습한 후 나머지 task에 대하여 성능 측정
◦
logical deduction을 제외하고 모두 비교적 큰 폭의 개선이 존재
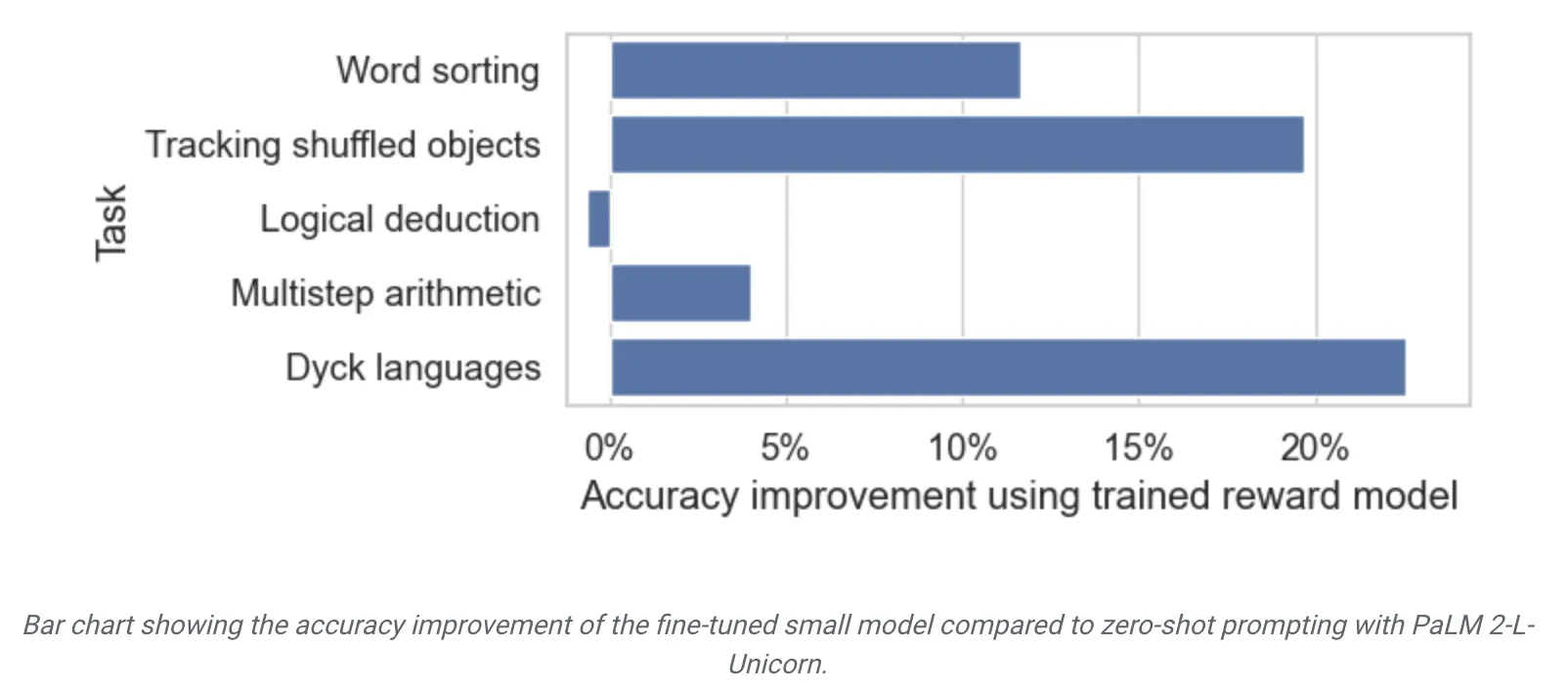
◦
즉, 자신이 학습하지 않은 task에 대해서도 어느 정도 generalization 능력이 있으며 LLM prompting 보다는 fine-tuning한 전용 모델이 더 잘 동작함
Discussion
•
AI 모델이 주어진 기준에 의거하여 생성한 글을 자동으로 판단하는 것은 여전히 해결하지 못한 과제로, 최근에는 LLM을 활용하여 자동으로 평가하고, 수정하여 성능을 높이려는 연구가 활발하게 진행되고 있음
•
그렇지만 이 논문에 따르면 현재의 LLM 기술은 추론 과정에서 논리적인 오류를 정확히 검출하는 능력은 아직 부족하다는 것을 알 수 있음. 이 문제는 사람에게도 쉬운 난이도의 문제가 아니며 따라서 LLM도 비슷하게 어려움을 겪는다고 볼 수 있음
•
다만 fine-tuning을 통하여 평가 전용 모델을 만들면 보다 높은 수준의 피드백을 얻을 수 있으며 적절한 수준(60-70% 정확도 수준)의 피드백만 있어도 교정 효과가 나타난 점은 모델을 통한 self-correction에 대한 희망을 볼 수 있었음