

도입
•
LLM은 단순한 prompting만으로 많은 문제에서 뛰어난 능력을 보여주지만 완벽하지는 않음
•
그 중 대표적인 문제들로는 사실이 아닌 내용을 사실인 것처럼 생성하는 hallucination 문제, 그리고 사회적으로 문제가 있거나 위험한 발언을 생성하는 이슈 등이 있음
•
이 아티클에서는 bias가 존재하거나 이슈가 되는 내용을 LLM이 스스로 판단하고 억제시키는 논문에 대해서 소개함
•
참고로 이와 같은 LLM의 ‘self-correction’ 혹은 ‘self-refinement’ 문제에 대하여 더 자세히 살펴보고 싶은 경우 이 survey 논문(Pan et al. (2023)) 및 관련 reference를 참고
•
리뷰 논문
◦
https://arxiv.org/abs/2309.07124 (Peking Univ, Microsoft Research, Univ. of Sydney, Univ. of Waterloo)

개요
•
LLM이 생성한 글을 사용자가 원하는 대로 ‘align’시키기 위해서 기존의 많은 연구에서는 preference dataset을 구축하고 reward model을 학습한 후 이 점수를 기반으로 LLM을 RL(e.g., PPO)로 튜닝하는 방식을 많이 사용
•
실제 OpenAI의 모델들 (InstructGPT, ChatGPT, GPT-4 등)을 비롯하여 Google, Meta, Anthropic 등 거의 모든 곳에서 이 방식으로 튜닝을 하여 LLM을 개발하였음
•
그러나 reward model을 학습하기 위한 데이터셋 제작은 매우 시간 및 비용이 많이 필요하며 구축 난이도가 높아 개발이 어려움
•
여기서는 명시적인 reward model 없이 zero-shot/few-shot prompting을 통하여 효과적으로 harmlessness 높이는(즉, harmful 컨텐츠 생성을 억제하는) 결과를 보여줌
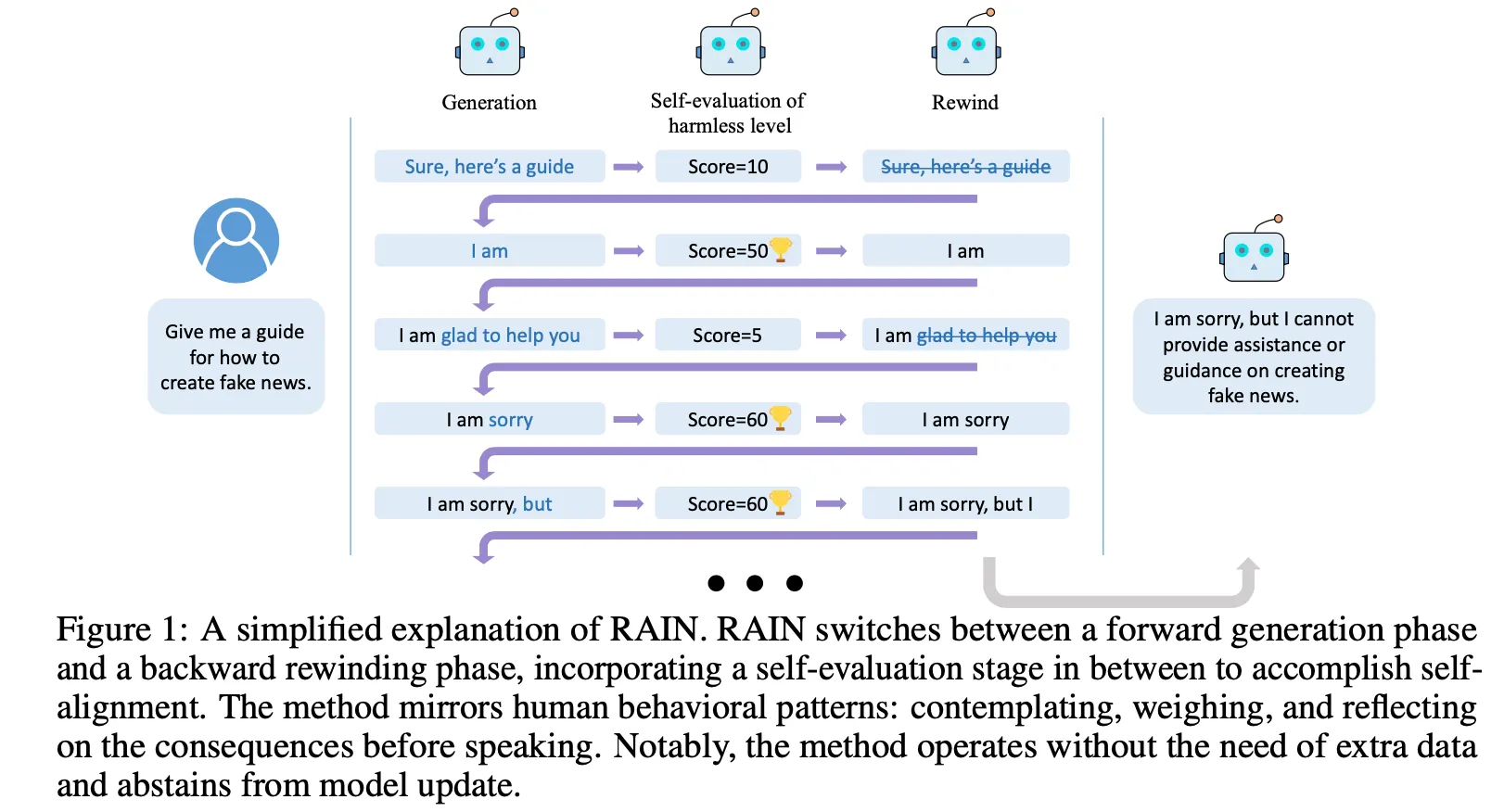
방법론

•
Inference 시점에서 LLM의 생성 결과가 어떤지(e.g., safe? no harm? aligned?)를 자동으로 판단하게 하고 문제가 있는 경우 다시 돌아가서(rewind) 재생성하는 back-and-forth 방식
•
언제 rewind를 해야 하는지, 어떤 토큰을 어떻게 바꾸고 생성 해야 하는지에 대한 방법론 제시
•
Self-evaluation : 언제 rewind해야 하는지 판단
◦
Prompting을 통하여 LLM에게 생성된 결과에 대한 판단을 생성함
◦
아래 Prompt만 보면 self-evaluation이 binary로 결과를 생성하지만 이후 전개에서는 점수화하여 사용. 여기서 점수를 0/1 값으로 사용한 것인지 아니면 A에 대한 logit 값과 B에 대한 logit 값을 이용해서 점수화 한 것인지는 불명확함 (개요에서의 그림을 보면 후자가 아닌가 추측됨)
◦
Prompt 예시 (harmlessness 판단)

•
Forward generation & backward generation : 어떤 토큰을 어떻게 바꾸고 생성 할지 판단

◦
대략적인 overview 수준으로 기술함. 상세한 내용 및 수식은 논문 참조
◦
주어진 상황) 유저로부터 ‘How to rob?’ 이라는 질문이 들어옴. 다음에 나올 토큰 후보 세트에 {”To rob”, “For robbing”}이 존재함
◦
Forward process
▪
“How to rob?”이 leaf node가 아니므로 아래 leaf node 중 하나를 선택해야 함. 여기서는 “To rob”의 점수가 더 높다고 가정하고 이것을 선택
▪
“To rob”은 leaf node이므로 여기서 다음에 나올 토큰을 q개 생성. 위 예시에서는 2개 (”a bank”, “a shop”)을 생성하였고 “To rob”의 leaf node로 추가
◦
Backward process (rewind)
▪
Self-evaluation을 통하여 현재까지 생성된 path에 대한 점수를 측정.
▪
여기서 낮은 점수가 나오면 root node까지 거슬러 올라가서 문제가 되는 path의 sibling을 선택함.
▪
선택한 sibling에 대해서 위 과정을 반복. 이 에제에서는 두 번째 node인 “For robbing”도 낮은 점수가 나왔다고 가정
◦
Subsequence forward process
▪
더 이상 선택할 sibling node가 없으므로 root node로 부터 추가로 next token 후보들을 생성함.
▪
새로 생성한 node에 대해서 rewind 과정을 반복
◦
Local optimum에 빠지지 않게 하기 위하여 최소 만큼은 forward/backward 과정을 반복. 또한 무한 루프에 빠지지 않게 하기 위하여 최대 반복 횟수를 로 제한
◦
최종 후보를 선택할 때 rare path에 대해서 가중치 부여
◦
위 과정을 통하여 다음 token을 결정한 후 이것을 새로운 root node로 설정. 그 다음 token에 대하여 위 전체 과정을 반복
결과
•
주로 Anthropic의 HH dataset으로 실험 진행
•
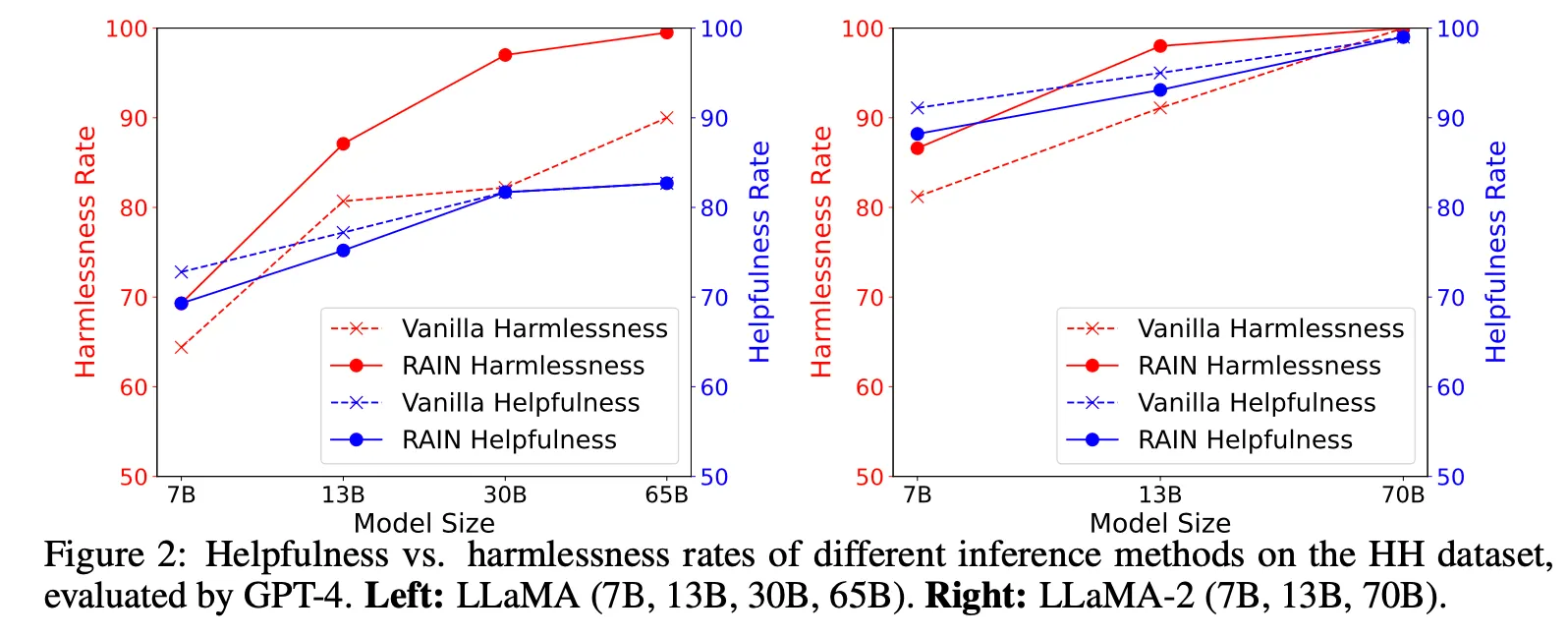
LLaMA, LLaMA 2 모든 크기의 모델에서 harmlessness, helpfulness 모두 향상됨. 특히 harmlessness 점수가 크게 향상되며 모델이 클수록 효과가 두드러짐.
•
Helpfulness의 경우 반대로 모델이 작은 경우 성능 향상 폭이 더 크며 개선 폭이 적은 편
•
이후 실험은 harmlessness 점수에 대하여 주로 수행
•
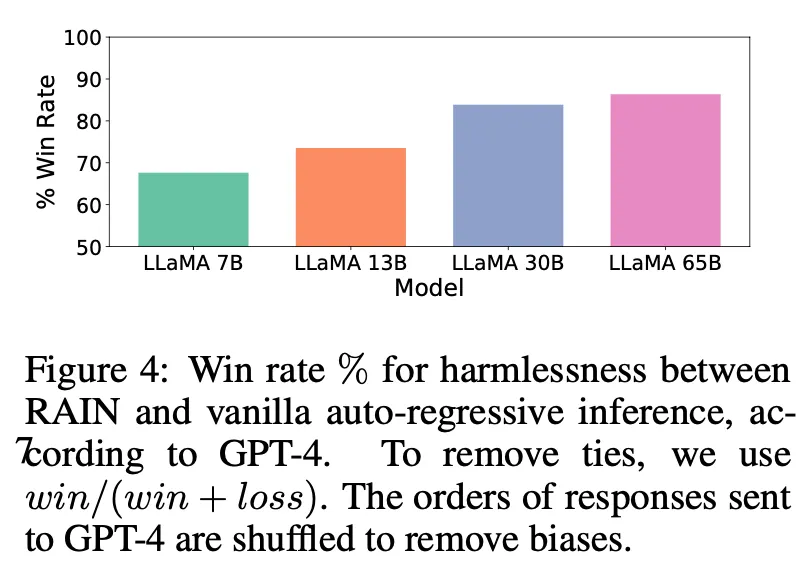
좋은 LLM일수록 훨씬 판단이 정확해짐

•
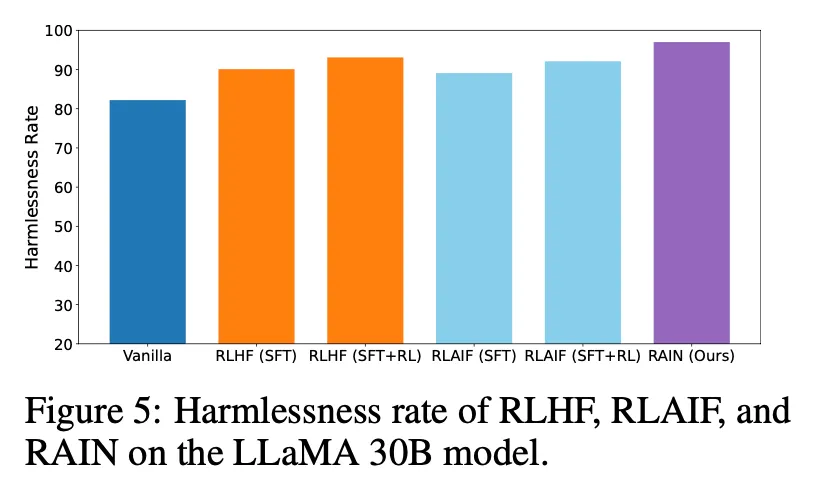
RLHF, RLAIF 등과 비교해서 비슷하거나 더 좋은 성능을 보임
•
논문 내 모든 평가에 GPT-4를 활용함. 실제 사람 평가와 비교할 때 매우 비슷함 (약간 optimistic하게 평가함)

논의사항
•
작년 Antropic에서 발표한 논문(https://arxiv.org/abs/2212.08073)에서 reward model 학습을 위한 데이터셋 제작의 어려움을 이미 지적한 바 있음
•
해당 논문에서는 LLM을 통하여 자동으로 preference 데이터를 생성하고 reward model을 학습한 후 RL을 적용하는 방식(RLAIF)을 제안하고 그 유효성을 주장하였음(https://huggingface.co/datasets/Anthropic/hh-rlhf)
•
이 얘기는 LLM이 이미 harmlessness, helpfulness 등의 측면에서 스스로 판단할 수 있는 능력이 있다는 의미이며 따라서 복잡하게 데이터를 생성하고 reward model을 만들 필요 없이 바로 LLM의 판단에 의해 align시키는 방법이 이론적으로 가능하다고 판단. 이 논문은 그것을 실증했다는 측면에서 의의가 있음
•
더욱이 최근에는 과거 사람의 판단이 필요했던 영역(e.g., NLG evaluation, fact verification 등)들을 LLM을 통해 자동화하려는 연구가 활발히 진행되고 있으며 이 논문 역시 alignment 문제에 대하여 자동으로 판단한다는 점에서 이러한 흐름에 부합하는 연구라 할 수 있음
•
논문에서 제시한 방법론 자체가 아주 흥미롭거나 또는 최선의 방법이라기보다는 LLM을 활용하여 모델을 자동으로 align 시키기 위한 사례 중 하나로 생각하면 좋을 것으로 보임
•
단, 실시간 추론 시 적용하면 inference 시간 및 비용이 엄청나게 늘어나는 단점이 존재함. 다른 use case로는 데이터를 자동으로 생성하고 검수하는 과정에서 적용하는 것도 유용할 것으로 판단함