
.png&blockId=1d583ee8-1821-428d-a3a1-42cd81e80e10&width=3600)

도입
•
추론이란 이미 알려진 사실을 근거로 새로운 판단 또는 결론을 이끌어 내는 것으로 지적 활동을 하는데 있어서 꼭 필요한 능력
•
따라서 LLM이 어떤 추론 능력을 보이는지 여부는 AI가 진정으로 '지능'을 가지고 있다고 사람들이 체감하는데 중요한 요소라 볼 수 있음
•
Scratchpads, Chain of Thoughts 등을 시작으로 LLM이 가진 추론 능력을 최대한 끌어내기 위한 연구가 지속적으로 활발하게 이루어 지고 있음
•
이 아티클에서는 추론을 보다 효율적으로 잘 수행하기 위하여 2단계로 나누어 접근한 Self-Discover라는 방법을 소개함
•
개요
•
한줄 요약 : 주어진 Task에 맞게 상세 풀이 방법을 설계하고, 각 instance 별로는 설계한 추론 방법을 기반으로 풀면 효과가 좋다는 내용
•
사람이 보통 문제를 풀 때 문제 유형에 따라 구체적인 추론 방법을 설계하고, 그 후 실제 풀이를 하는 단계를 거친다는 것을 LLM에 적용한 방식
•
여러 LLM, 여러 task에서 전반적으로 성능 향상 효과가 존재
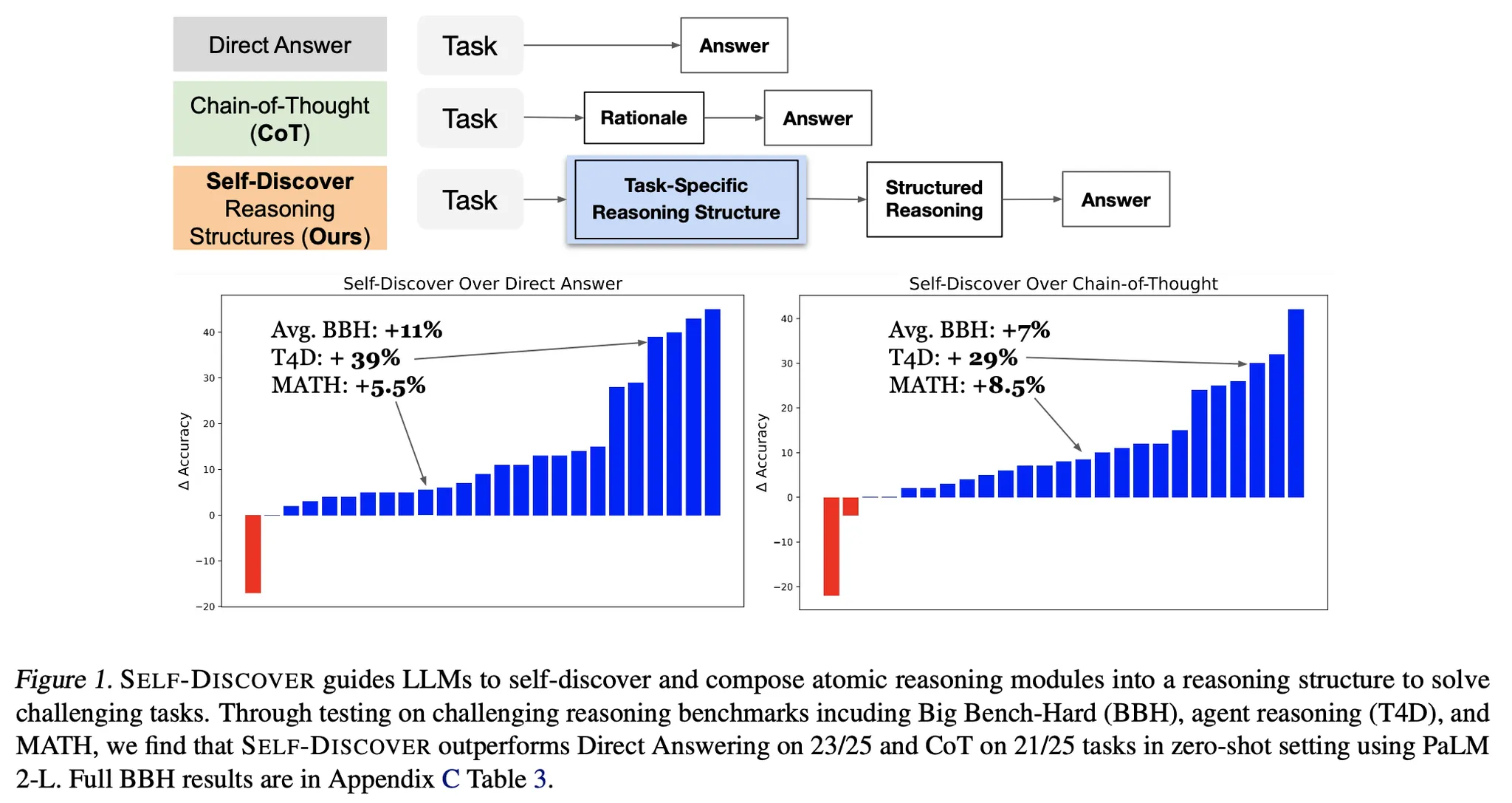
방법론 상세
•
추론 문제를 다음의 2가지 단계에 걸쳐서 접근
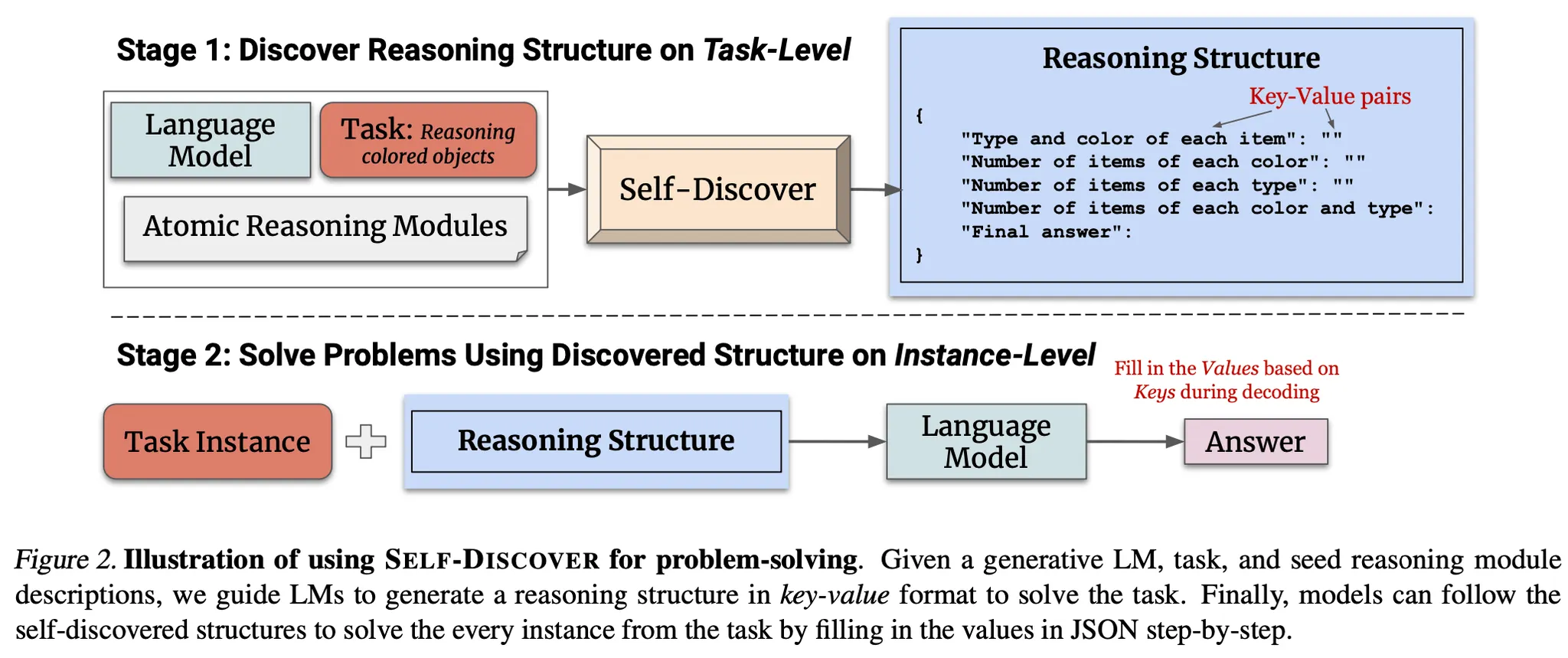
•
Stage 1 : Self-discover task-specific structures
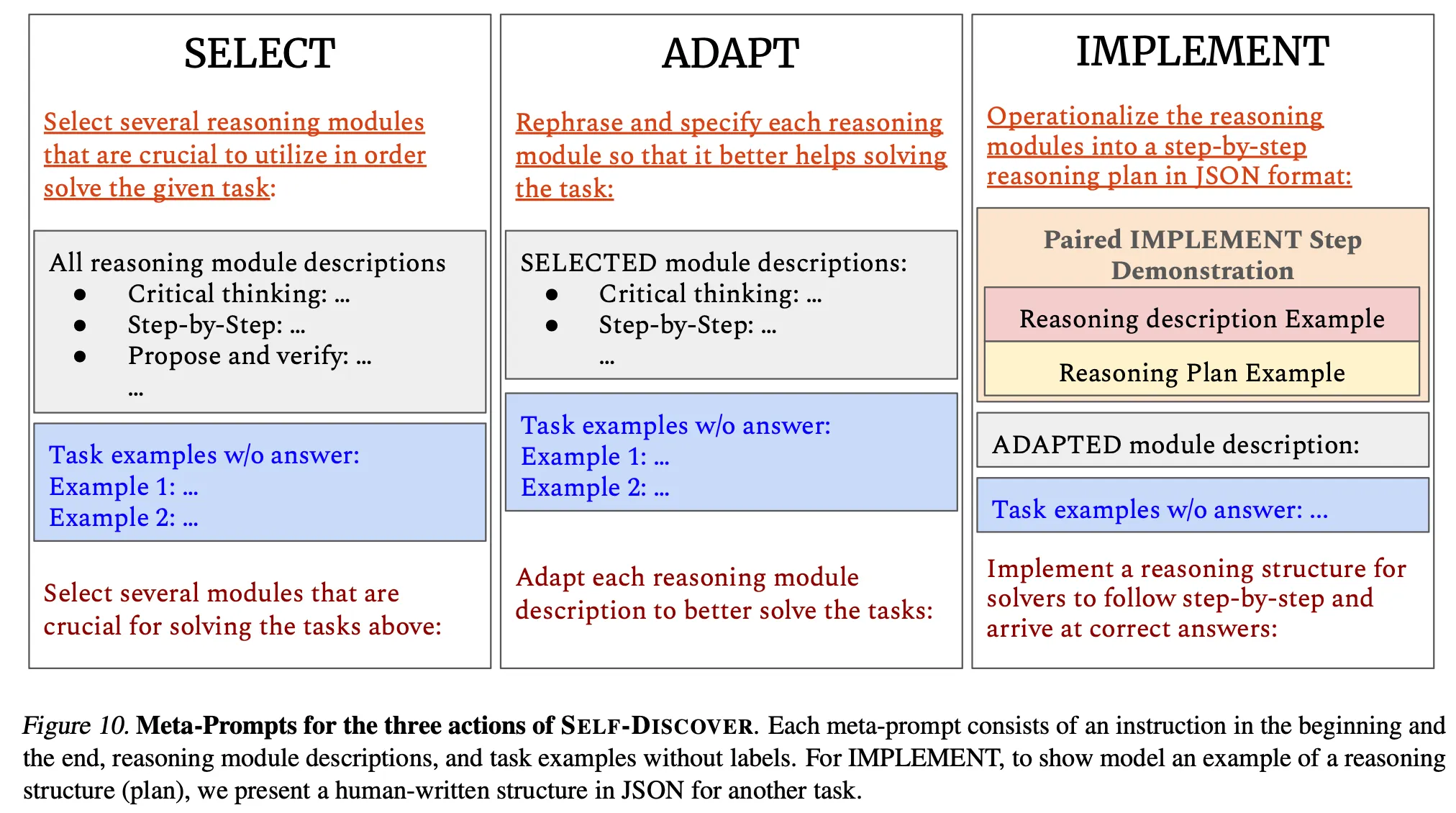
◦
Stage 1은 다음의 3가지 단계를 통하여 진행
◦
Select : Label이 붙어 있지 않은 예제 데이터를 보고 사전에 정의한 총 39가지의 reasoning module(아래 그림 참고) 중에서 적합한 모듈들을 고르는 단계.
예시) 소설 생성하기 -> "creative thinking"

◦
Adapt : 앞선 select 단계에서 선택한 reasoning module들을 각각 task에 맞는 상세한 description으로 다시 작성하는 단계
예시) 계산 문제 : "break the problem into sub-problems" -> "calculate each arithmetic operation in order"
◦
Implement : 앞선 adapt 단계에서 생성한 상세 description을 기반으로 실제 문제 풀이시 사용할 key-value pair 형식의 상세한 reasoning structure를 생성하는 단계. 이 단계의 prompt에는 다른 task에 대하여 사람이 작성한 상세 reasoning structure 예시 데이터를 넣어줌
•
Stage 2 : Tackle tasks using discovered structures

◦
Stage 1에서 최종 생성한 reasoning structure를 입력으로 각 instance들을 실제로 추론하는 단계.
◦
Reasoning structure의 각 key(추론 sub-step)에 해당하는 value를 생성하여 최종 답을 도출함
결과
•
사용 LLM : GPT-4, PaLM 2-L
•
Tasks
◦
◦
◦
•
Baseline 1(기본 방법론과 비교) : Direct prompting, CoT, plan-and-solve
◦
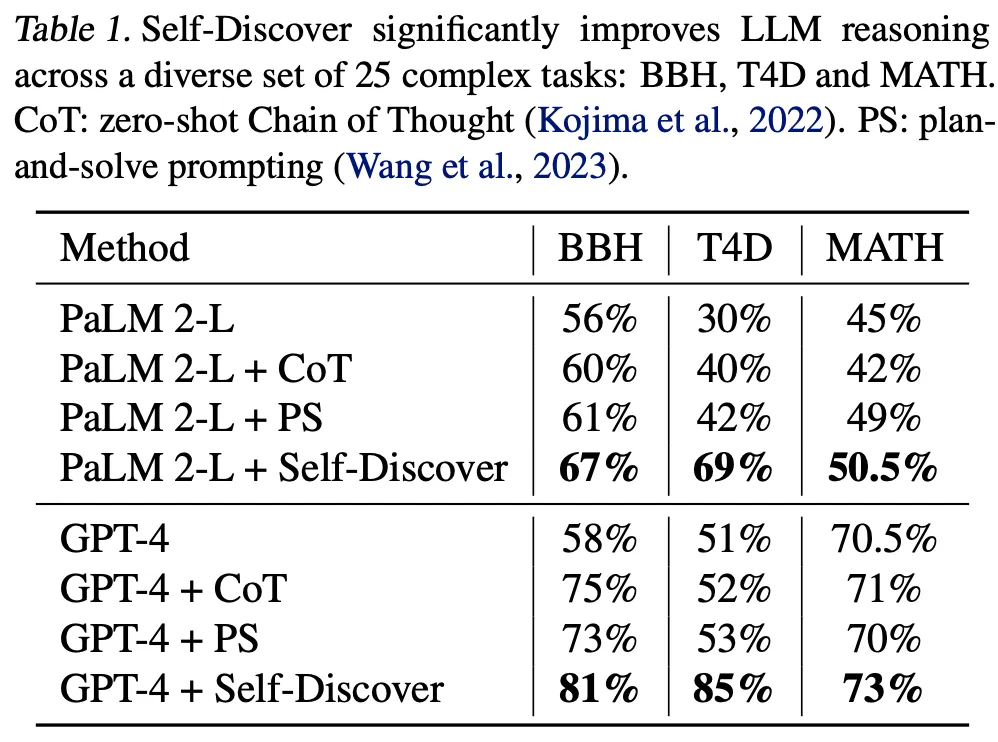
기본 방법론들 대비 모든 케이스에서 성능 향상 관찰
◦
특히 다양한 world knowledge가 필요한 문제에서 향상이 두드러짐
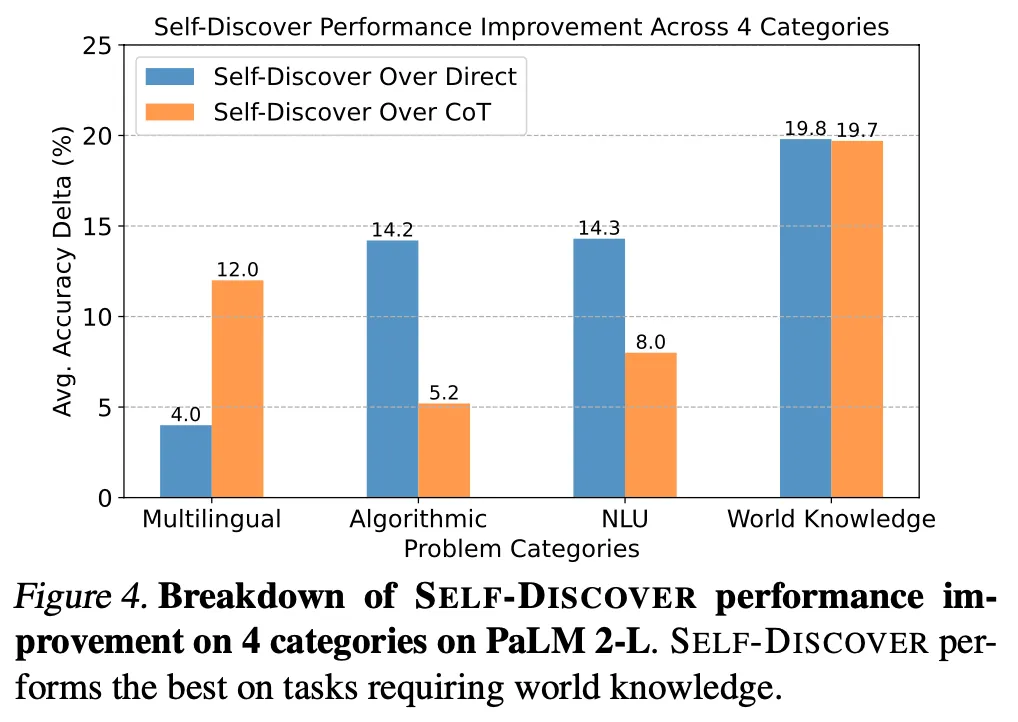
•
Baseline 2(사전에 정의한 reasoning module을 활용하는 방법들과 비교) : CoT-SC, Majority voting, Best of each RM
◦
더 적은 inference 횟수로 더 뛰어난 성능을 달성
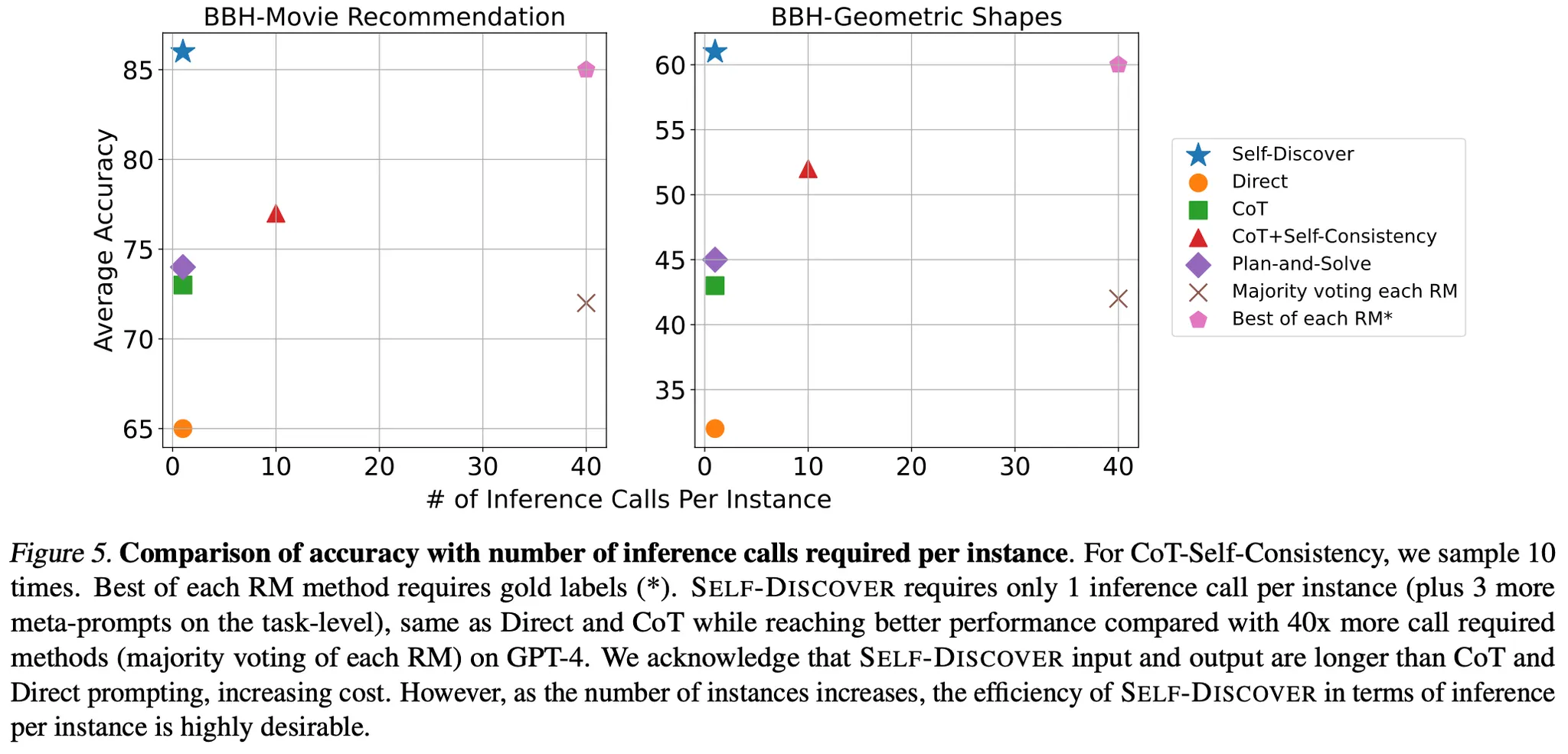
추가 분석
•
Stage 1의 3단계는 모두 효과가 있음
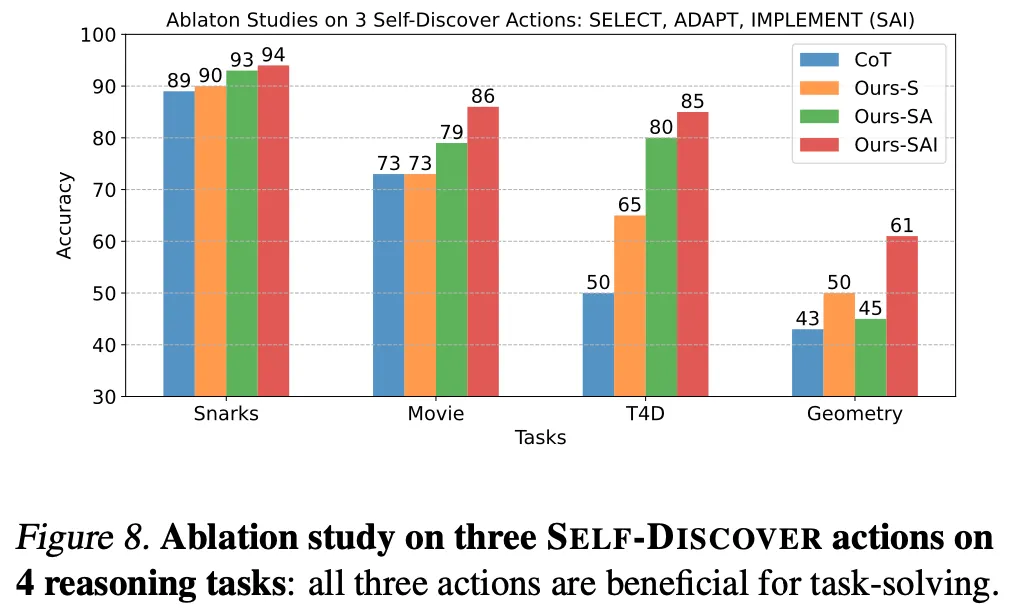
•
Stage 1을 통하여 생성한 prompt가 LLM간 transferrability가 존재함
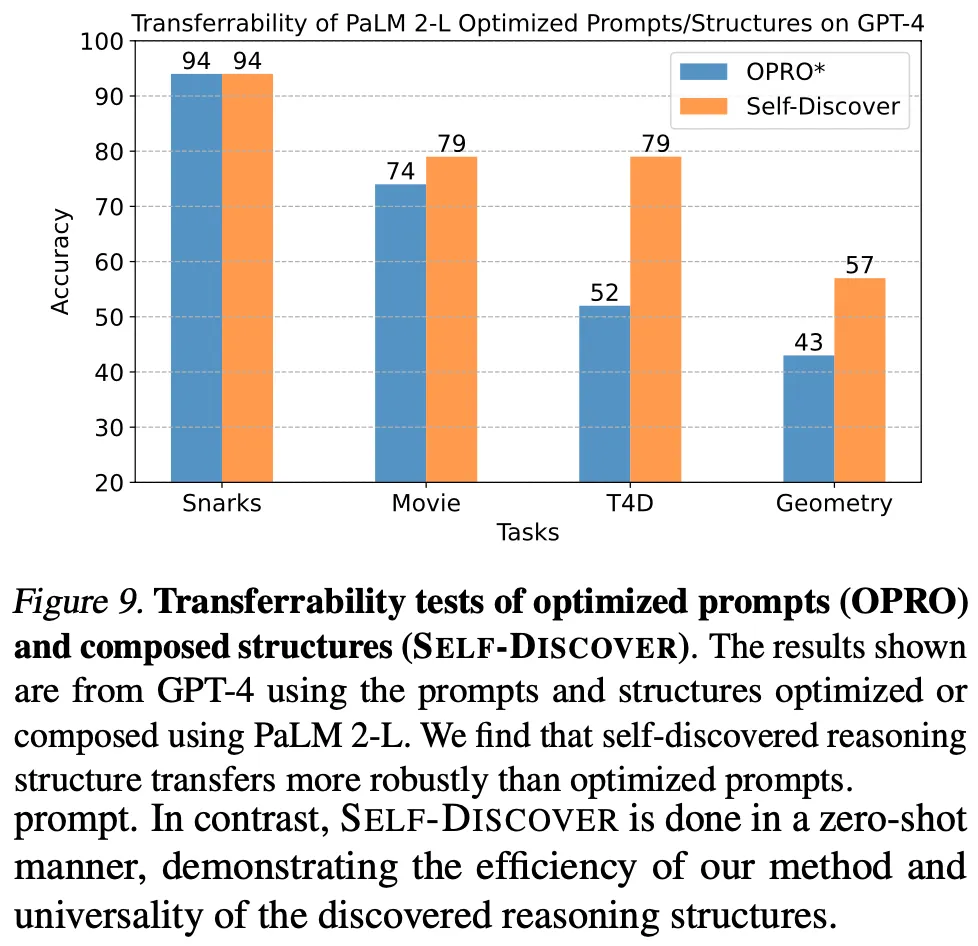
◦
PaLM 2-L 에서 생성한 프롬프트를 GPT-4에 적용하여 추론 수행
◦
비교 대상 방법인 OPRO는 20%의 데이터를 활용한 방법인데도 zero-shot으로 생성한 self discover가 더 좋음. 단, GPT-4로 생성하고 추론한 경우 보다는 약간 떨어짐 (T4D에서 85% vs 79%)
◦
GPT-4를 통하여 생성한 프롬프트를 작은 모델에 적용한 경우 CoT 대비 성능이 더 좋음 : BBH 성능에서 GPT-3.5-turbo(51% → 56%), LLaMA 2 70B(42% → 52%)
논의사항
•
AI의 추론 능력은 LLM이 등장하면서 비로소 의미 있는 수준으로 발현되기 시작하였음.
•
최근의 연구는 주로 사람이 문제를 풀 때 접근하는 방식들을 적용하는 시도하여 효과를 본 사례가 다수 존재하며 이 논문도 그 중 하나로 볼 수 있음