

이 아티클의 전반부는 Super-NaturalInstructions(SuperNI) 논문을 개괄적으로 살펴본 후 후반부에서는 SuperNI에 포함된 데이터 세트 중에서 한국어로 되어 있거나 흥미로운 주제를 담고 있는 데이터 세트를 다룸.
논문 소개
개요
•
SuperNI는 Allen Institute for AI, University of Washington, Arizona State University를 비롯한 총 21개 기관 소속의 연구자들이 참여하여 1,600 여개의 NLP instruction 데이터를 제작하고 공개한 프로젝트
◦
github 주소 : https://github.com/allenai/natural-instructions
◦
•
https://arxiv.org/abs/2104.08773 에서 61개 task에 대한 데이터를 공개하는 것으로 시작
•
총 88명의 contributor들이 기존에 공개된 NLP 데이터를 활용하고 crowdsourcing 하는 등의 방법으로 작업
•
Tk-Instruct(영어) 및 mTk-Instruct(다국어) 모델 개발
◦
각각 T5 및 mT5 모델을 SuperNI 데이터로 fine-tuning
◦
119가지 영어 task에서 InstructGPT 대비 ROUGE-L 점수 기준 9.9점 향상
◦
35가지 영어가 아닌 언어 task에서 InstructGPT 대비 13.3점 향상
방법론 상세
•
데이터 구조
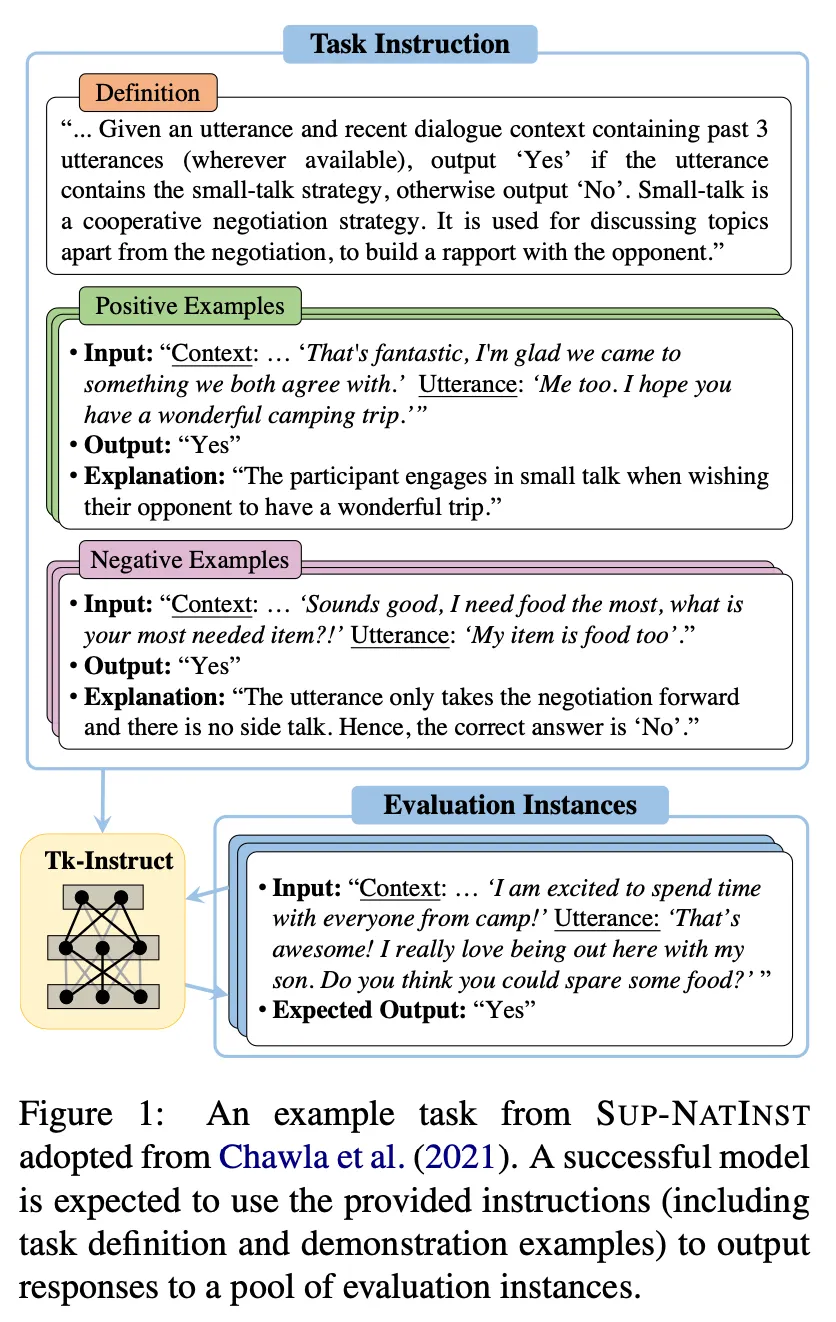
◦
Definition : task 수행을 위한 instruction
◦
Positive examples : input / correct output / 관련 설명으로 구성
◦
Negative examples : input / incorrect output / 관련 설명으로 구성
◦
Evaluation instances : Tk-Instruct 및 mTk-Instruct 모델 학습에는 사용하지 않고 evaluation에만 사용하는 테스트 데이터. Task별 밸런스를 맞추기 위하여 최대 6500개로 제한
•
SuperNI 데이터 세트의 간단한 통계 분석
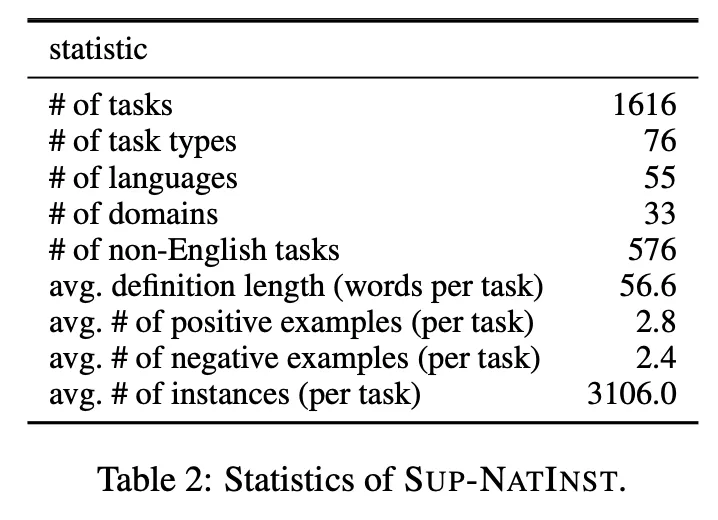
•
SuperNI에 포함된 Task의 종류 및 다른 instruction 데이터 세트와 비교
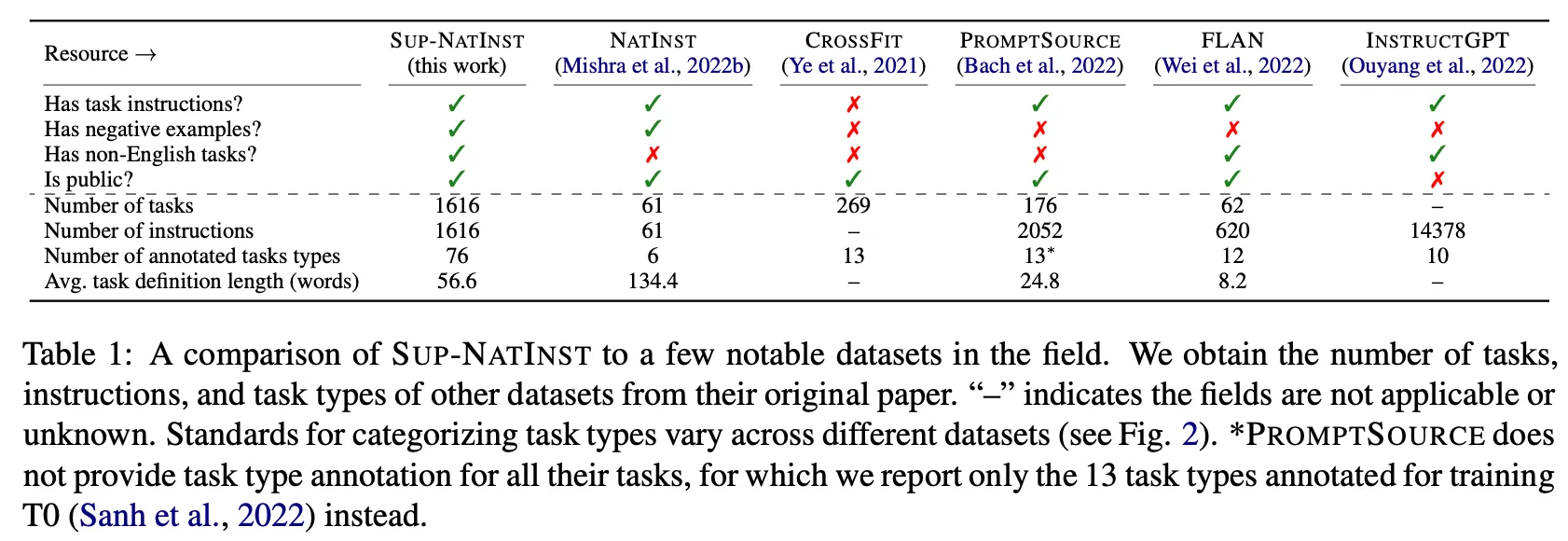
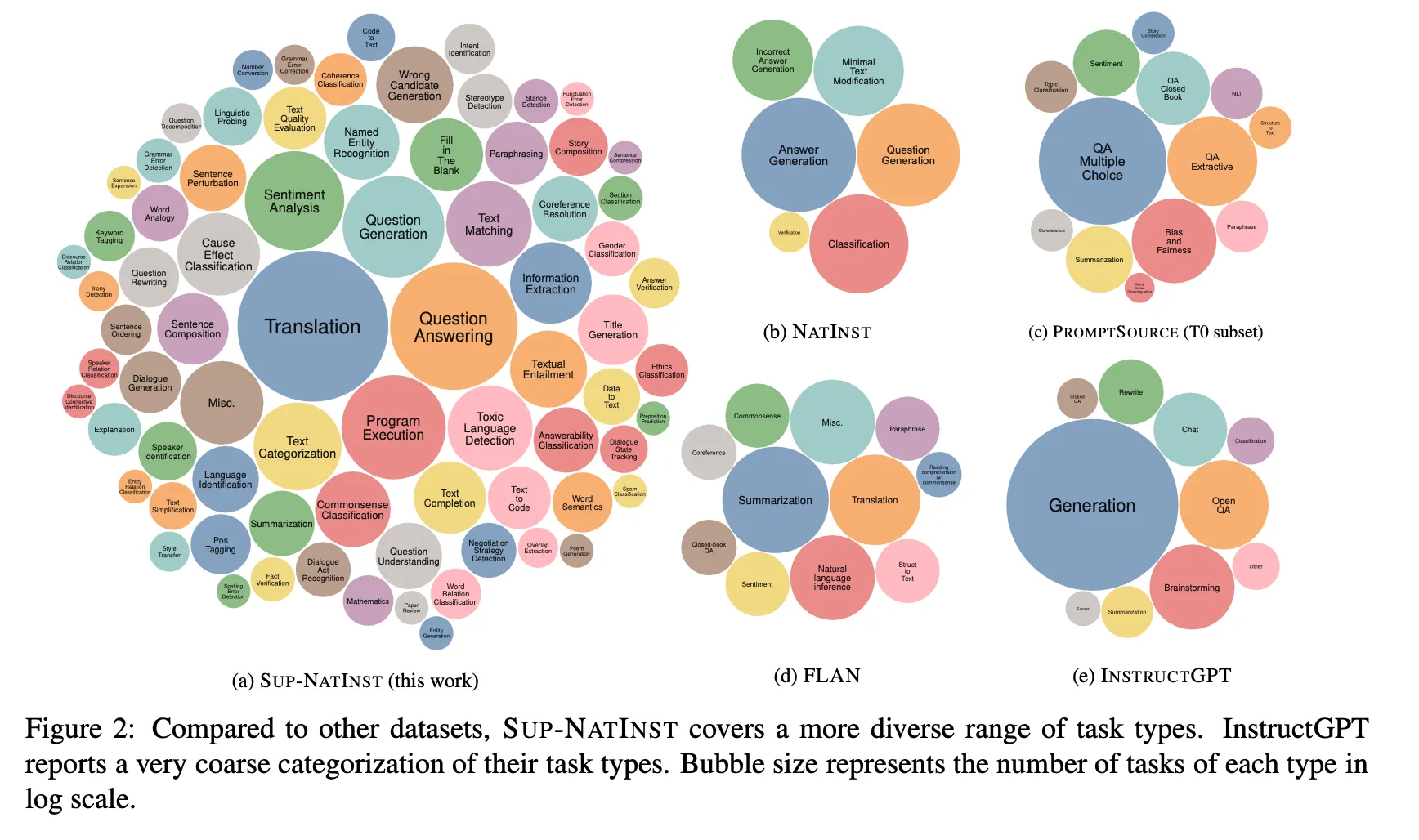
Results
•
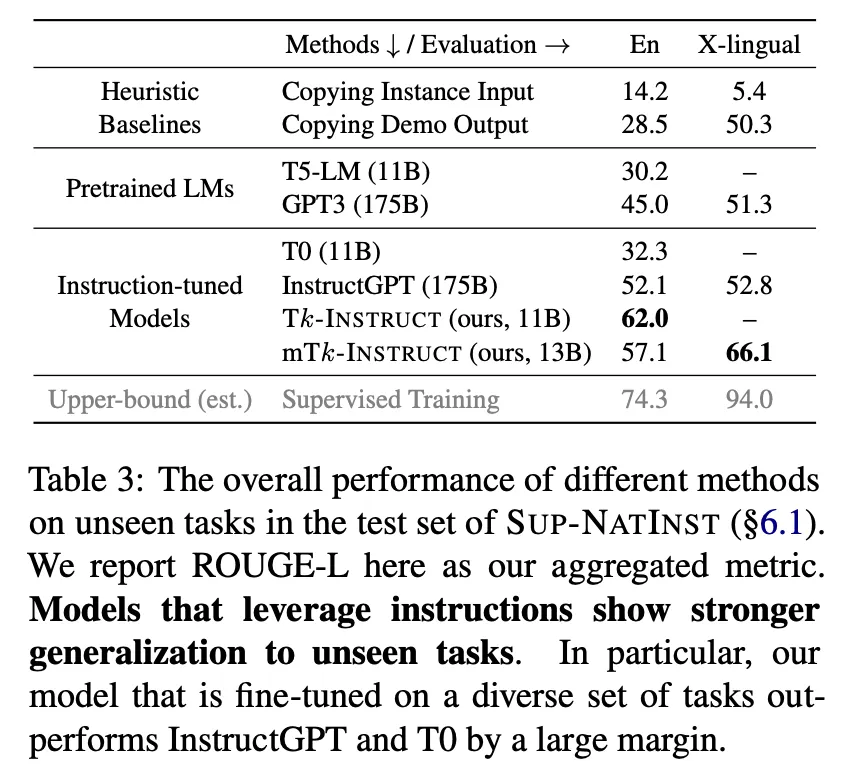
전체 결과 summary
◦
영어 : 발표 당시 기준 InstructGPT 대비 ROUGE-L 점수 기준 9.9점 높음 (52.1 vs 66.0)
◦
다국어 : 발표 당시 기준 InstructGPT 대비 ROUGE-L 점수 기준 13.3점 높음 (52.8 vs 66.1)
•
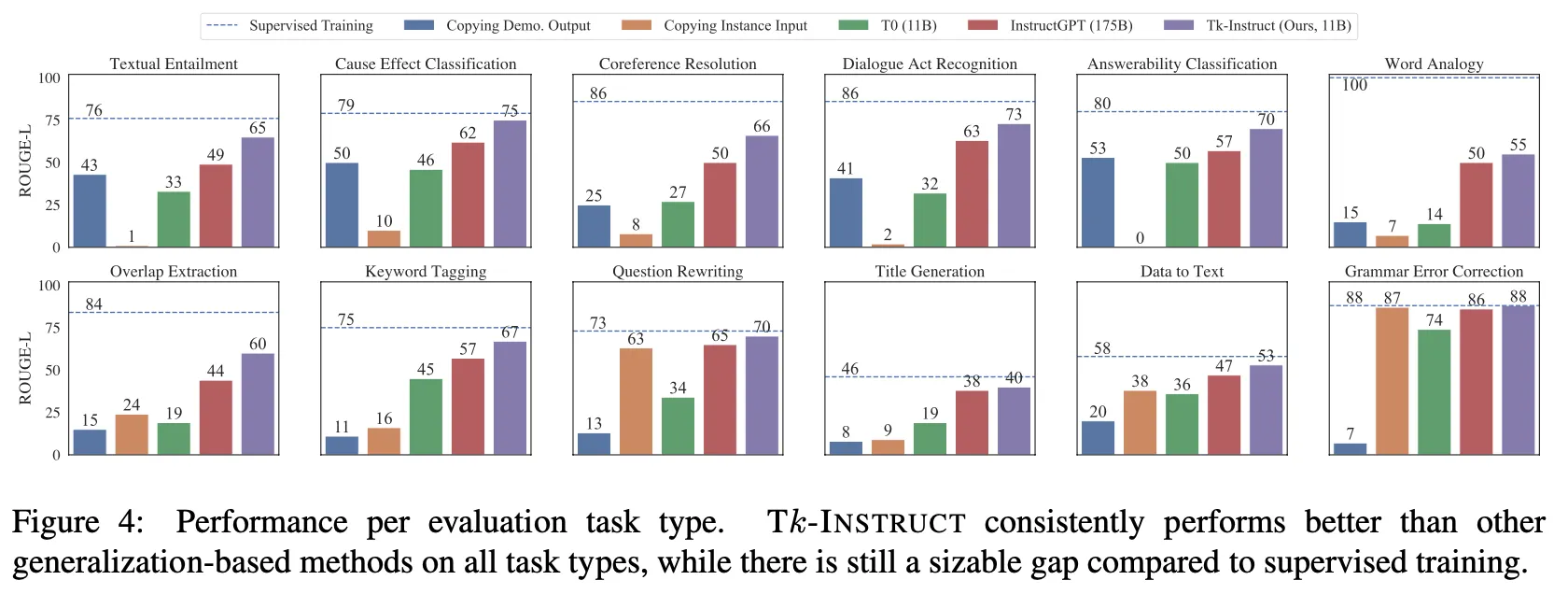
Task 유형별 성능 비교
◦
모든 유형에서 InstructGPT보다 더 좋으며 일부 유형에서는 supervised SOTA 성능과 거의 유사한 수준

주요 데이터 소개
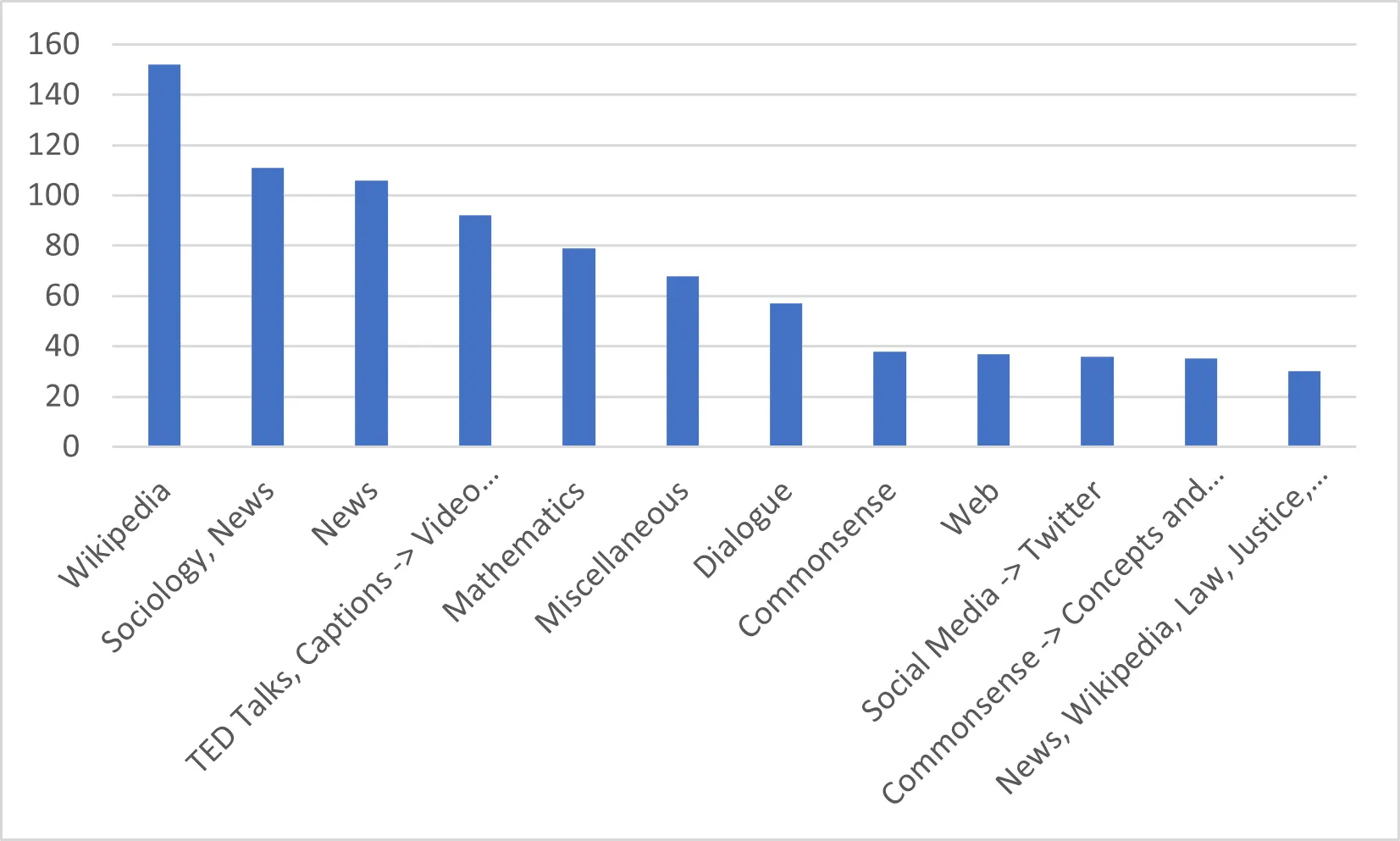
데이터에 가장 많이 포함된 범주
•
상위 범주를 살펴보면 위의 논문 리뷰에서 알 수 있는 것처럼 번역에 해당하는 과제가 가장 많고 번역 외에도 질의 응답, 프로그램 실행( “Generating text that follows simple logical operations such as "repeat", "before", "after" etc.” 등의 과제), 질의문 자동 생성, 감성 분석, 범주 분석, 문장 유사성 평가. 민감한 주제 탐지, 인과 관계 분류, 정보 추출 등이 많음
•
원천 데이터로 가장 많이 사용된 데이터를 살펴 보면 다음 표에서 확인할 수 있는 것처럼 위키피디아임을 알 수 있음
•
그 외에도 뉴스나 위키피디아와 뉴스를 같이 쓰는 경우가 많고 수학식, 대화, 일반상식, SNS 데이터 등이 많이 사용되었음
사용 언어
사용 언어 | 데이터 개수 | 사용 언어 | 데이터 개수 | 사용 언어 | 데이터 개수 |
English | 1243 | Urdu | 10 | Assamese | 1 |
Spanish | 27 | Galician | 9 | Burmese | 1 |
Japanese | 25 | Hebrew | 9 | Czech | 1 |
Persian | 24 | Catalan | 7 | Dutch | 1 |
Hindi | 20 | Korean | 7 | Greek | 1 |
Chinese | 15 | Dutch, English | 4 | Igbo | 1 |
Gujarati | 15 | Bulgarian | 3 | Kannada | 1 |
Telugu | 14 | Croatian | 3 | Kurdish | 1 |
Arabic | 12 | Swedish | 3 | Lithuanian | 1 |
Bengali | 12 | Turkish | 3 | Malay | 1 |
French | 12 | Central Khmer | 2 | Nepali | 1 |
Marathi | 12 | Filipino | 2 | Norwegian | 1 |
Italian | 11 | Finnish | 2 | Romanian | 1 |
Malayalam | 11 | Indonesian | 2 | Sinhala | 1 |
Oriya | 11 | Lao | 2 | Slovak | 1 |
Panjabi | 11 | Russian | 2 | Somali | 1 |
Polish | 11 | Thai | 2 | Tagalog | 1 |
Portuguese | 11 | Vietnamese | 2 | Xhosa | 1 |
Tamil | 11 | Yoruba | 2 | Zhuang | 1 |
German | 10 | 총합계 | 1613 |
•
영어 데이터가 가장 많고 출력 형식이 한국어인 데이터는 모두 7개임.
•
출력만 한국어인 데이터는 모두 번역용 데이터이고 입출력이 모두 한국어인 데이터는 Pawsx( https://github.com/google-research-datasets/paws/tree/master/pawsx) 1개뿐임. Pawsx 데이터 세트는 프랑스어, 스페인어, 독일어, 중국어, 일본어, 한국어 등 유형적으로 구별되는 6개 언어를 사람이 번역한 PAWS 평가 쌍 23,659개와 기계 번역된 훈련 쌍 296,406개가 포함되어 있음. 번역은 PAWS-Wiki 에서 확인 가능 .
Name | Summary | Category | Domain | Input Language | Output Language |
task771_pawsx_korean_text_modification | Given a sentence in Korean, provide an equivalent paraphrase in said language | Paraphrasing | Wikipedia | Korean | Korean |
task777_pawsx_english_korean_translation | Given a sentence in English, provide an equivalent translation to Korean | Translation | Wikipedia | English | Korean |
task790_pawsx_french_korean_translation | Given a sentence in French, provide an equivalent translation to Korean | Translation | Wikipedia | French | Korean |
task796_pawsx_spanish_korean_translation | Given a sentence in Spanish, provide an equivalent translation to Korean | Translation | Wikipedia | Spanish | Korean |
task802_pawsx_german_korean_translation | Given a sentence in German, provide an equivalent translation to Korean | Translation | Wikipedia | German | Korean |
task808_pawsx_chinese_korean_translation | Given a sentence in Chinese, provide an equivalent translation to Korean | Translation | Wikipedia | Chinese | Korean |
task814_pawsx_japanese_korean_translation | Given a sentence in Japanese, provide an equivalent translation to Korean | Translation | Wikipedia | Japanese | Korean |
구체적인 예시는 다음과 같으며 레이블 0과 1은 문장의 관계가 같음(1로 표시)과 다름(0으로 표시)을 의미함
id | sentence1 | sentence2 | label |
10 | 2005년과 2009년 사이 그가 스웨덴 Carlstad United BK, 세르비아 FK Borac Čačak, 러시아 FC Terek Grozny에서 뛰었던 것은 제외됩니다. | 2005년 후반에서 2009년 사이 그가 스웨덴 Carlstad United BK, 세르비아 FK Borac Čačak, 러시아 FC Terek Grozny에서 뛰었던 기간은 제외입니다. | 1 |
12 | 타바시 강은 루마니아 류드라 강의 지류이다. | Leurda강은 루마니아에 있는 Tabaci강의 지류입니다. | 0 |
•
특징적으로 개체명에 해당하는 사람 이름이나 회사 이름 등은 모두 번역하지 않고 그대로 두었음. 또한 원천 데이터로 모두 Wikipedia를 사용했다는 특징이 있음.
참고
• Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, Eshaan Pathak, Giannis Karamanolakis, Haizhi Lai, Ishan Purohit, Ishani Mondal, Jacob Anderson, Kirby Kuznia, Krima Doshi, Kuntal Kumar Pal, et al.. 2022. Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5085–5109, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
•
관련 깃허브 링크 :
•
Yinfei Yang, Yuan Zhang, Chris Tar, and Jason Baldridge. 2019. PAWS-X: A Cross-lingual Adversarial Dataset for Paraphrase Identification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3687–3692, Hong Kong, China. Association for Computational Linguistics.
•
데이터 분석에 사용한 원천 데이터