

표 데이터의 역할
•
표 데이터 역사
(1) 특정 도메인과 관련된 데이터들이 주로 구축되었는데 농구와 관련된 Rotowire(Wiseman 외, 2017) 데이터 세트, 생물학과 관련된 KBGen(Banik 외, 2013) Wikibio(Lebret 외, 2016) 데이터 세트. 식당 예약 등과 관련된 E2E(Novikova 외, 2016, 2017)등이 그 예이다. (2) 표를 통한 문장 생성과 관련하여서는 Puduppully,R.(2018), Ankur Parikh 외(2020), Jonathan 외(2020) 등이 있다. 이 아티클에서는 그 중에서 ToTTo:A Controlled Table-To-Text Generation Dataset 에 대해서 다룬다.

ToTTo 에서 표 기반 문장 생성 데이터를 만든 프로세스
•
(1) 다양한 형태의 포맷으로부터 타이틀, 서브 타이틀, 표 정보를 추출한 후 주요 표 정보에 노락색으로 강조 표시(highlight) 를 한다.
•
(2) 표와 함께 수집한 문장(아래 이미지에서 Original text)] 에서 표의 내용과 관련이 없는 것은 삭제(text after deletion) 한 후 최종 문장을 만들어서 문장 생성의 정확도를 높였다.
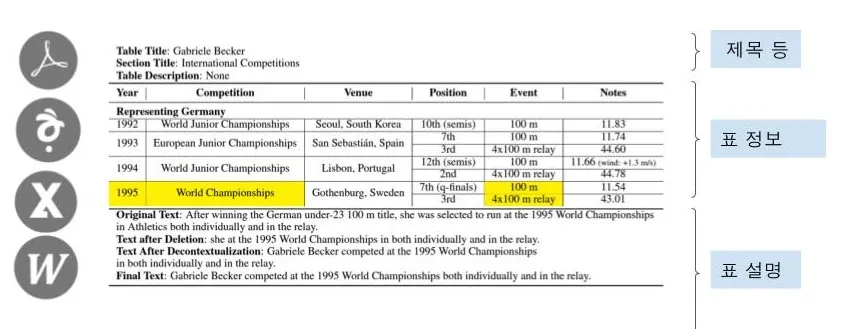
위의 이미지에서 알 수 있는 것처럼 다양한 형태의 포맷에서 데이터를 추출하기 때문에 데이터 입력에도 많은 시간과 비용이 든다. 또한 표에서 꼭 필요한 정보를 추출하는 것과 이를 통해 추론 가능한 문장을 만들어 내는 것이 표 기반 문장 생성의 목표이면서 어려운 점이다.
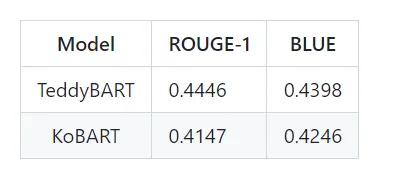
korean_T2T_baseline에서 확인할 수 있다. 2022년 기준 모델 성능은 다음표와 같다.
논의사항
•
위의 표에서 확인할 수 있는 것처럼 50%에도 미치지 못하여 아직 개선할 부분이 많음을 짐작할 수 있다.
•
표 기분 정보 추출에서 중요한 정보를 요약하고 기초 통계를 제시하는 것은 현 단계에서 중요한 과제일 수 있다.
•
입력 데이터의 다양한 포멧, 조직도와 같이 중요 정보와 보조적 정보를 구분할 필요가 없는 형식 등을 고려할 필요가 있다.
최근 동향을 반영한 글들
•
•
2D 관계형 테이블 이해를 위한 자료 링크 : Paper page - Table-GPT: Table-tuned GPT for Diverse Table Tasks (huggingface.co)
참고문헌
Ankur Parikh, Xuezhi Wang, Sebastian Gehrmann, Manaal Faruqui, Bhuwan Dhingra, Diyi Yang, and Dipanjan Das. 2020. ToTTo: A Controlled Table-To-Text Generation Dataset. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1173–1186, Online. Association for Computational Linguistics.
Chin-Yew Lin, 2004, ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
Eva Banik, Claire Gardent, and Eric Kow. 2013. The kbgen challenge. In Proc. of European Workshop on NLG.
Jekaterina Novikova, Ondˇrej Duˇsek, and Verena Rieser. 2017. The E2E dataset: New challenges for end-toend generation. In Proc. of SIGDIAL.
Sam Wiseman, Stuart M Shieber, and Alexander M Rush. 2017. Challenges in data-to-document generation. In Proc. of EMNLP.
Rémi Lebret, David Grangier, and Michael Auli. 2016. Neural text generation from structured data with application to the biography domain. In Proc. of EMNLP.
Sebastian Gehrmann, Tosin P. Adewumi, Karmanya Aggarwal, et al(2021), “The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics”, In Proceedings of the 1st Workshop on Natural Language Generation, Evaluation, and Metrics, Online. Association for Computational Linguistics.