

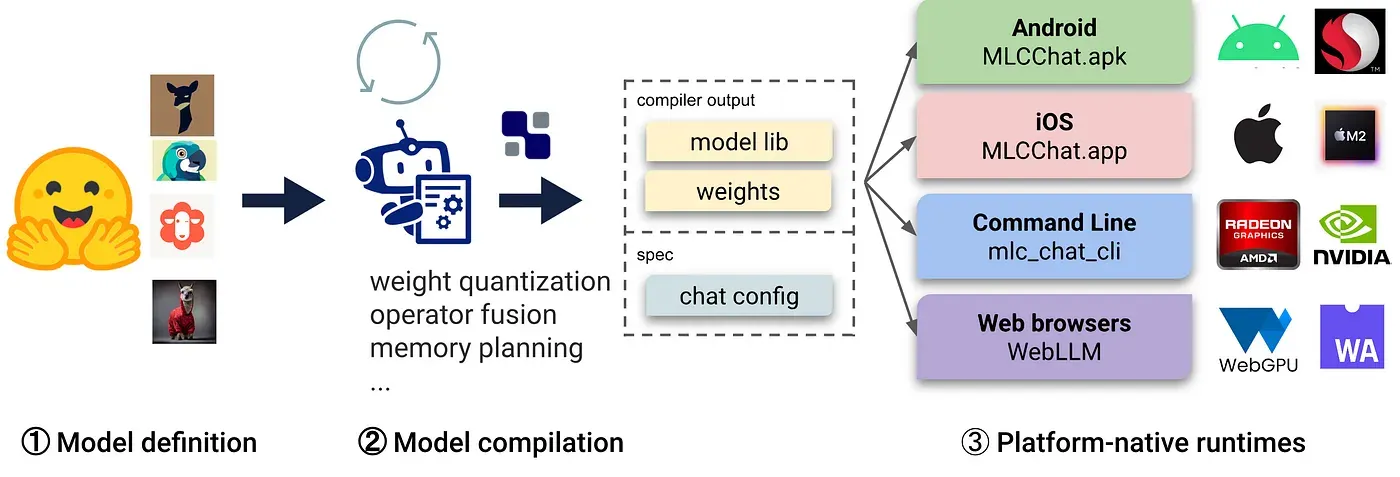
LLM Compile Process Overview
지난 글 지극히 사적인 나만의 LLM, 가칠 수 있을까? [1편 - 파인튜닝] 에서는 대규모 모델 구축의 난이도와 파괴적 망각 현상 등에 대한 대안으로 등장한 Retriever Augmented Generation(RAG) 방법을 살펴 보았습니다. RAG는 LLM의 강력한 텍스트 생성 능력을 기반으로 하며, 사용자 쿼리에 맞는 필요한 문서 스니펫을 적절하게 가져와서 모델에 프롬프트를 통해 응답하는 방식입니다. 사용자가 개인화된 LLM을 구축하고 특정 목적에 맞게 조정하는 방법은 다양한 곳에서 유용하게 사용될 수 있습니다.

이번에는 MLC-LLM 패키지를 활용한 WebGPU Build & Run 가이드를 공유합니다. 이를 통해 대규모 언어 모델(LLM)을 WebGPU를 활용하여 빌드하고 실행하는 과정을 통해 나만의 데이터로 대규모 언어 모델을 구축하고 실행할 수 있을 것입니다.
Prerequisites
LLM 빌드를 위한 요구사항
•
python3 보편적으로 많이 사용하는 Conda 환경에서 python 언어를 사용하여 진행
•
conda: Python 패키지 충돌을 방지하기 위해 환경 분리 시 필요함.
•
Git LFS: weight file 등 대용량 파일을 pulling하기 위해 필요.
•
TVM Compiler: 오픈소스 딥러닝 컴파일러
WebAssembly 빌드를 위한 요구사항
•
Emscripten: LLVM을 사용하는 언어(C/C++)를 WebAssembly로 컴파일할 수 있도록 제공하는 툴 체인.
Build

환경설정 → mlc-llm 패키지 설치 → WebGPU LLM 컴파일
환경설정
LLM을 원활하게 컴파일하고 실행하기 위해서는 다음의 패키지가 필요합니다. 환경 설정은 패키지 설치와 개발 환경을 설정하는 과정으로 이루어집니다.
python3, Git LFS
공식 설치 가이드에 따라 설치를 수행합니다.
conda
TVM Compiler
Emscripten
mlc-llm 패키지 설치
# clone the repository
git clone https://github.com/mlc-ai/mlc-llm.git --recursive
# enter to root directory of the repo
cd mlc-llm
# install mlc-llm
pip install .
Bash
복사
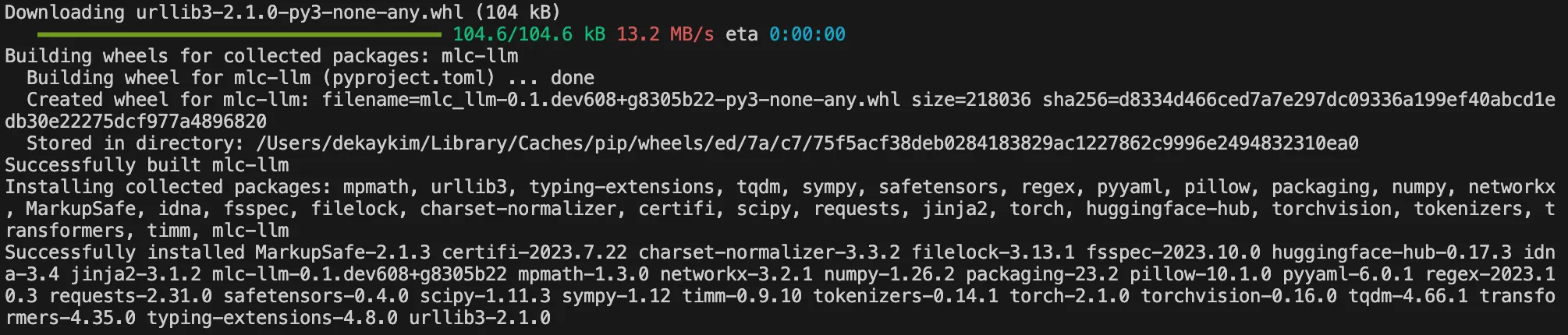
Command: pip install .
WebGPU LLM 컴파일
Conda 환경 활성화, Emscripten 환경변수 설정, prep_emcc_deps 스크립트 실행 후 컴파일을 실행합니다.
cd mlc-llm
# tvm 실행환경 activate
conda activate tvm
# Set Enviroment variables
source EMSDK_PATH/emsdk_env.sh
export TVM_HOME=./3rdparty/tvm
# This file prepares all the necessary dependencies for the web build.
./scripts/prep_emcc_deps.sh
# Compile!
python3 -m mlc_llm.build --hf-path togethercomputer/RedPajama-INCITE-Chat-3B-v1 --target webgpu --quantization q4f16_1
Bash
복사

Command: python3 -m mlc_llm.build --hf-path togethercomputer/RedPajama-INCITE-Chat-3B-v1 --target webgpu --quantization q4f16_1
•
--hf-path: 컴파일 대상의 repository의 경로 입력
•
-quantization: 양자화 값 설정
컴파일 후 아래와 같이 /dist/MODEL_ID/.wasm 파일을 확인할 수 있습니다.
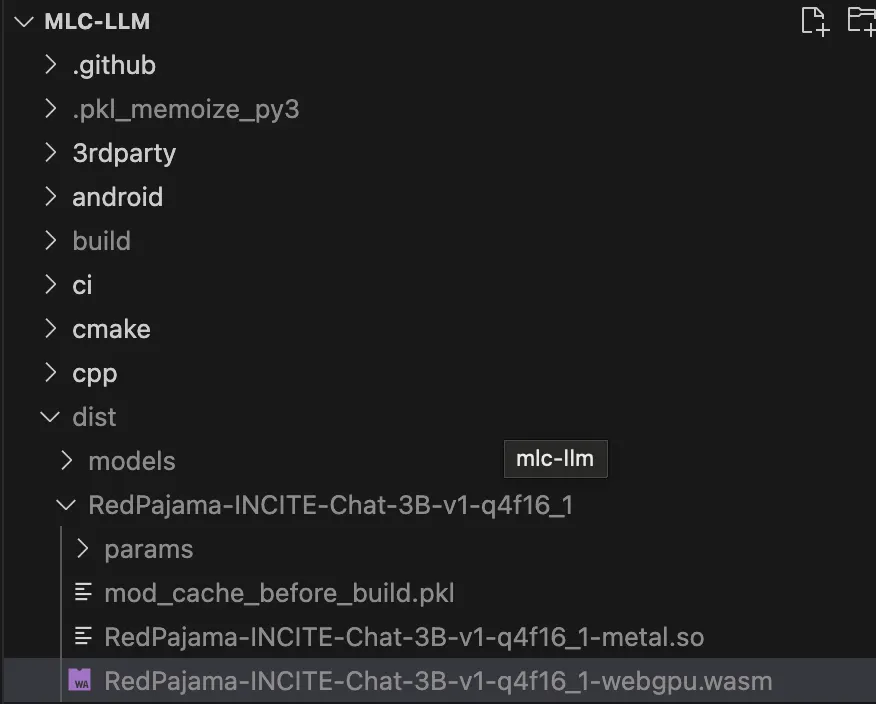
Run
WebGPU LLM Loader
•
WebGPU LLM 로더는 MLC의 tvm 웹 모듈을 기반으로 하는 web-llm 라이브러리를 사용합니다.
•
WebGPU로 빌드된 대규모 언어 모델을 웹 브라우저에서 실행할 수 있게 해주는 장점이 있습니다.
•
Vercel에 배포된 다음 링크를 통해 접근할 수 있습니다.
WebGPU LLM Loader
https://webgpu-llm-loader.vercel.app/
Vercel에 배포된 Loader 링크
•
컴파일 된 WebGPU LLM은 WebGPU LLM Loader를 통해 실행시킬 수 있습니다.
•
WebGPU LLM Loader는 MLC에서 tvm의 web 모듈을 wrapping한 web-llm 라이브러리를 사용하여 WebGPU로 빌드된 LLM을 실행해볼 수 있도록 제작된 로더입니다.
•
Loader에서 즉시 실행해볼 수 있는 LLM 목록 : 각 모델은 각기 다른 VRAM(비디오 RAM) 이 필요합니다.
◦
Llama 2 7B Chat (Required 8GB of VRAM)
◦
Llama 2 13B Chat (Required 16GB of VRAM)
◦
Llama 2 70B Chat (Required 64GB of VRAM)
•
또한 직접 컴파일한 WebGPU LLM 파일(.wasm) 또한 실행해볼 수 있습니다.
◦
Model Local Id: The local_id from your mlc-chat-config.json.
◦
Model URL: The URL of the Model you uploaded to huggingface.
◦
WASM File: The .wasm file built for your WebGPU.
Troubleshooting
ModuleNotFoundError: No module named ‘tvm’
RuntimeError: Please set TVM_HOME for webgpu build following scripts/prep_emcc_deps.sh
emcc: command not found
_pickle.UnpicklingError: invalid load key, ‘v’.
"WebGPU LLM Loader"를 통해 웹 브라우저에서 대규모 언어 모델을 효과적으로 실행하는 방법에 대해 살펴 보았습니다. 이 과정을 통해 다양한 모델을 실험하고 자신의 모델을 직접 실행해볼 수 있을 것입니다.
이번에는 MLC-LLM 패키지를 활용한 WebGPU Build & Run 가이드를 공유합니다. 이를 통해 대규모 언어 모델(LLM)을 WebGPU를 활용하여 빌드하고 실행하는 과정을 통해 나만의 데이터로 대규모 언어 모델을 구축하고 실행할 수 있을 것입니다.
Prerequisites
LLM 빌드를 위한 요구사항
•
python3 보편적으로 많이 사용하는 Conda 환경에서 python 언어를 사용하여 진행
•
conda: Python 패키지 충돌을 방지하기 위해 환경 분리 시 필요함.
•
Git LFS: weight file 등 대용량 파일을 pulling하기 위해 필요.
•
TVM Compiler: 오픈소스 딥러닝 컴파일러
WebAssembly 빌드를 위한 요구사항
•
Emscripten: LLVM을 사용하는 언어(C/C++)를 WebAssembly로 컴파일할 수 있도록 제공하는 툴 체인.
Build
환경설정 → mlc-llm 패키지 설치 → WebGPU LLM 컴파일
환경설정
LLM을 원활하게 컴파일하고 실행하기 위해서는 다음의 패키지가 필요합니다. 환경 설정은 패키지 설치와 개발 환경을 설정하는 과정으로 이루어집니다.
python3, Git LFS
공식 설치 가이드에 따라 설치를 수행합니다.
conda
TVM Compiler
Emscripten
mlc-llm 패키지 설치
# clone the repository
git clone https://github.com/mlc-ai/mlc-llm.git --recursive
# enter to root directory of the repo
cd mlc-llm
# install mlc-llm
pip install .
Bash
복사
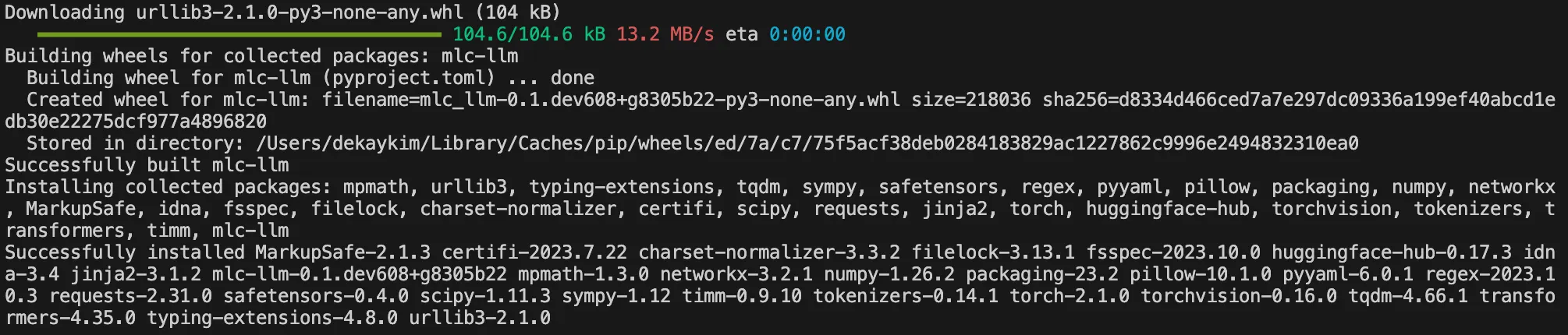
Command: pip install .
WebGPU LLM 컴파일
Conda 환경 활성화, Emscripten 환경변수 설정, prep_emcc_deps 스크립트 실행 후 컴파일을 실행합니다.
cd mlc-llm
# tvm 실행환경 activate
conda activate tvm
# Set Enviroment variables
source EMSDK_PATH/emsdk_env.sh
export TVM_HOME=./3rdparty/tvm
# This file prepares all the necessary dependencies for the web build.
./scripts/prep_emcc_deps.sh
# Compile!
python3 -m mlc_llm.build --hf-path togethercomputer/RedPajama-INCITE-Chat-3B-v1 --target webgpu --quantization q4f16_1
Bash
복사

Command: python3 -m mlc_llm.build --hf-path togethercomputer/RedPajama-INCITE-Chat-3B-v1 --target webgpu --quantization q4f16_1
•
--hf-path: 컴파일 대상의 repository의 경로 입력
•
-quantization: 양자화 값 설정
컴파일 후 아래와 같이 /dist/MODEL_ID/.wasm 파일을 확인할 수 있습니다.
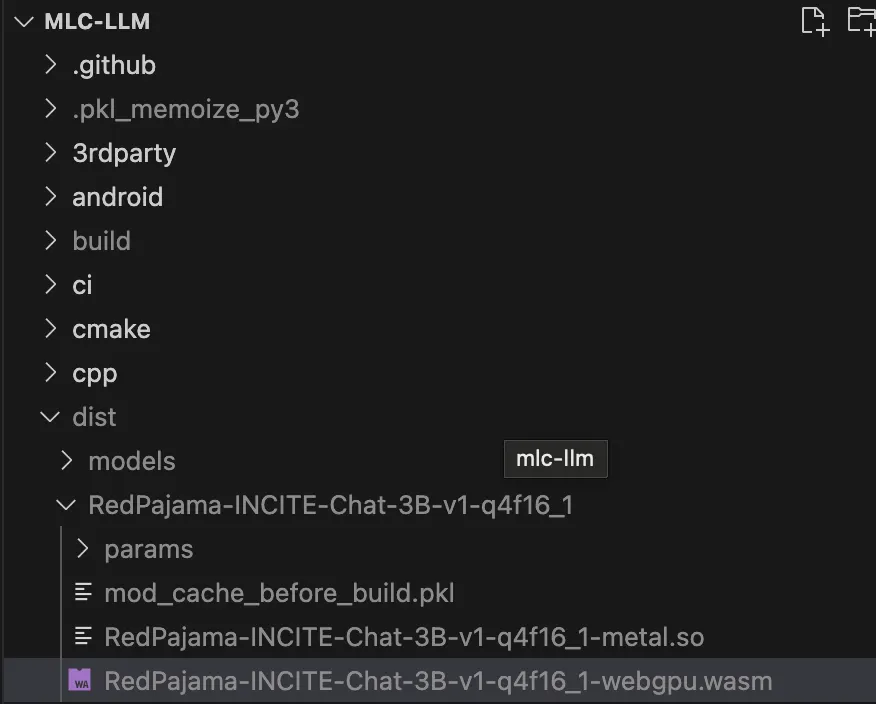
Run
WebGPU LLM Loader
•
WebGPU LLM 로더는 MLC의 tvm 웹 모듈을 기반으로 하는 web-llm 라이브러리를 사용합니다.
•
WebGPU로 빌드된 대규모 언어 모델을 웹 브라우저에서 실행할 수 있게 해주는 장점이 있습니다.
•
Vercel에 배포된 다음 링크를 통해 접근할 수 있습니다.
WebGPU LLM Loader
https://webgpu-llm-loader.vercel.app/
Vercel에 배포된 Loader 링크
•
컴파일 된 WebGPU LLM은 WebGPU LLM Loader를 통해 실행시킬 수 있습니다.
•
WebGPU LLM Loader는 MLC에서 tvm의 web 모듈을 wrapping한 web-llm 라이브러리를 사용하여 WebGPU로 빌드된 LLM을 실행해볼 수 있도록 제작된 로더입니다.
•
Loader에서 즉시 실행해볼 수 있는 LLM 목록 : 각 모델은 각기 다른 VRAM(비디오 RAM) 이 필요합니다.
◦
Llama 2 7B Chat (Required 8GB of VRAM)
◦
Llama 2 13B Chat (Required 16GB of VRAM)
◦
Llama 2 70B Chat (Required 64GB of VRAM)
•
또한 직접 컴파일한 WebGPU LLM 파일(.wasm) 또한 실행해볼 수 있습니다.
◦
Model Local Id: The local_id from your mlc-chat-config.json.
◦
Model URL: The URL of the Model you uploaded to huggingface.
◦
WASM File: The .wasm file built for your WebGPU.
Troubleshooting
ModuleNotFoundError: No module named ‘tvm’
RuntimeError: Please set TVM_HOME for webgpu build following scripts/prep_emcc_deps.sh
emcc: command not found
_pickle.UnpicklingError: invalid load key, ‘v’.
"WebGPU LLM Loader"를 통해 웹 브라우저에서 대규모 언어 모델을 효과적으로 실행하는 방법에 대해 살펴 보았습니다. 이 과정을 통해 다양한 모델을 실험하고 자신의 모델을 직접 실행해볼 수 있을 것입니다.