
Author
박우명 / CDO & Head of Research
Category
Paper Review
Tags
MTEBEmbeddingBenchmark
Published
October 16, 2023
- MTEB(Massive Text Embedding Benchmark)
- MTEB 상위권 방법론들
- 1. FlagEmbedding
- 2. GTE
- 3. E5
- 4. InstructOR
- 논의사항
- 기타 참고할만한 방법론들
MTEB(Massive Text Embedding Benchmark)

MTEB이란:
- 다양한 임베딩 작업에서 텍스트 임베딩 모델의 성능을 측정하기 위한 만든 대규모 벤치마크
- 2023년 10월 10일 기준 데이터 세트, 언어, 점수, 모델의 개수
- Total Datasets: 129
- Total Languages: 113
- Total Scores: 14667
- Total Models: 126
참고 링크 :
https://github.com/embeddings-benchmark/mteb
https://huggingface.co/spaces/mteb/leaderboard
https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB (중국어에 특화된 모델)
MTEB 상위권 방법론들
1. FlagEmbedding
관련 논문 : [2309.07597] C-Pack: Packaged Resources To Advance General Chinese Embedding (arxiv.org)
- BAAI General Embedding
- https://github.com/FlagOpen/FlagEmbedding
(1) 데이터 세트와 훈련 과정
- 사전 훈련 데이터 세트: Pile, Wikipedia, MS MARCO 등
- 미세조정 데이터 세트: Wikipedia, CC-NET 등
- 데이터 세트 구성 : 질문, 긍정 답변, 부정 답변
(2) 훈련 상세 정보
- 자체 모델 RetroMAE로 훈련
- 사전 훈련
- 배치 크기 : 720
- 옵티마이저 : AdamW.
- 학습률 (Learning Rate, LR) =2e-5
- 미세 조정
- 배치 크기 : 32784
- 옵티마이저 : AdamW,
- 학습률 (Learning Rate, LR)LR=1e-5
- 온도 설정 : temperature=0.01
- 특성 : 미세조정 과정에서는 “하드 네거티브(hard negative)” 학습 방법도 활용
- 비율 : 포지티브(positive) 답변 1, 하드 네거티브 답변 1, 네거티브(negatives) 답변 65566 개
(3) 특징
- 검색 작업(retrieval task)에 특별한 지시(instruction)인 "Represent this sentence for searching relevant passages:")을 추가하여 퀴리 인코딩을 진행했으며 문장을 상대적으로 길게 만들어, 짧은 쿼리와 긴 문서 간의 길이 차이를 완화하고자 하는 목적으로 사용
- GTE에서는 미세 조정(fine-tuning)을 할 때 강한 부정(hard negative)의 문장이 존재하므로 오히려 배치(batch)가 그리 크지 않아도 된다고 주장
- 부정 답변은 관련성 없음에 가까운 답변을 의미
2. GTE
관련 논문 : GTE(Towards General Text Embeddings with Multi-stage Contrastive Learning)
- 데이터 세트
- 사전 학습 : 7억8천8백만 응답쌍
- E5의 CCPairs 데이터를 만드는 방법과 거의 비슷하게 응답쌍을 생성
- 필터링(Filtering) 방법론은 밝히지 않음
- Finetuning : 3 백만 응답쌍
- MS MARCO, NQ, TriviaQA, HotpotQA, Web Questions, SNLI, MNLI, FEVER, Quora, MEDI, BERRI 등 다양한 데이터 세트 사용
- 학습
- Transformer Encoder
- MiniLM, bert-base, bert-large를 백본으로 사용
- Vanilla dual-encoder 구조이며 output layer를 mean pooling 해서 사용
- 사전 학습
- “Improved” InfoNCE loss
- 일반적으로 query <-> document 로 계산하나 query 끼리, document 끼리의 비교도 추가하여 loss 를 계산
- contrastive training using only in-batch negative. hard negative가 없기 때문에 배치 크기를 매우 크게 했음 (16384). 대신 max length를 128로 함
- 미세 조정(Finetuning)
- 하드 네거티브(hard negative) 응답이 있기 때문에(없는 데이터는 랜덤 네거티브(random negative)) 배치 크기가 아주 크지 않아도 됨. 128을 사용.
- 최대 길이(max length)는 512 사용
- 관찰
- 백본에 미세 조정만 하는 것은 데이터 규모의 한계 등으로 오히려 성능이 더 안 좋을 수 있음


- 학습 데이터 개수, 배치 크기, 모델의 파라미터 개수에 따른 성능 비교

: 대조 사전 훈련 및 미세 조정 중 다양한 요인에 대한 스케일링 분석.
모델 성능은 MTEB의 평균 성능으로 측정
- 특징
- E5와 거의 비슷한 접근법으로 동일한 모델 구조, 동일한 백본 모델과 유사한 학습 방법론 사용
- 사전 학습을 위한 데이터 세트 생성 방법에는 약간의 차이가 있음
- 미세 조정에 사용한 데이터가 더 많고 teacher model을 사용하지 않음
3. E5
- EmbEddings from bidirEctional Encoder rEpresentations
- MS
- https://arxiv.org/abs/2212.03533
- 사전학습
- CCPairs라는 데이터셋을 직접 구축
- Reddit, Common Crawl, Stack Exchange, Wikipedia, Scientific papers, News 등에서 수집
- (query, passage), (post, comment), (question, upvoted answer), (entity name+section title, passage), (title, abstract), (title, passage) 등의 형태로 pair를 생성
- Reddit과 Common Crawl에는 heuristic에 기반한 필터링 적용. 1.3 억 쌍
- Consistency-based filter 적용 : 1차로 수집한 데이터로 모델을 학습한 후 다시 학습 데이터를 넣어서 쿼리 기준 top-k passage를 고르는 방법. k=2 이내 실제 매핑된 passage가 있는 데이터만 사용. (얼마나 학습하고 돌리는지가 관건). 270 억 쌍
- 뉴럴넷은 보통 깨끗한 데이터에 대해서 먼저 피팅되고 잡음이 있는 데이터에 나중에 오비피팅 되는 경향이 존재
- 미세조정
- MS MARCO, NQ, NLI 데이터
- NLI는 contradiction을 hard negative로 간주
- msmarco와 nq는 teacher 모델 (cross-encoder) 에서 추출. Teacher 모델로 SimLM 사용
- 훈련
- Transformer Encoder
- MiniLM, bert-base, bert-large를 백본으로 사용
- Bi-encoder 구조이며 output layer를 average pooling 해서 사용
- 사전 학습
- InfoNCE
- in-batch negative 사용. 명시적인 hard negative는 없음
- query / passage encoder는 parameter sharing. 대신 prefix(query: , passage: )를 붙임
- 미세 조정
- InfoNCE loss에 teacher 모델과의 distillation loss를 추가하여 사용
- 논의사항
- InstructOR보다 조금 좋아짐. 당시 SOTA
- 학습 데이터를 모으는 방법, filtering 방법, negative data mapping 방법, 학습 테크닉, objective function, 등등 요소 등을 참고할 수 있음
4. InstructOR
- The University of Hong Kong, U of Washington, Meta, AllenAI
- https://arxiv.org/abs/2212.09741
- 데이터 세트
- 미세 조정만으로 모델링
- 저자들이 MEDI 데이터 세트를 직접 구축
- 총 330 가지의 데이터 세트
- Super-NaturalInstructions 300 가지
- Embedding data 30가지 :Sentence Transformers(https://huggingface.co/datasets/sentence-transformers/embedding-training-data), KILT, MedMCQA
- 기존 임베딩 모델(Sentence-T5)를 활용해서 positive / negative 매핑을 수행
- 다양한 task에 하나의 모델로 동작할 수 있도록 튜닝 시 지시문(instruction)을 추가
- 예시-retrieval) Represent the Wikipedia question for re- trieving supporting documents:(query), Represent the Wikipedia document for retrieval:(document)
- 학습
- 단일 인코더
- GTR 모델을 백본으로 사용 : T5 모델로 초기화한 후 웹 코퍼스를 사전 학습에 사용, 정보 검색 데이터 세트로 미세 조정
- 마지막 은닉층의 표현을 mean pooling으로 하여 임베딩 벡터를 얻음
- 미세 조정 단계만 존재한다는 특징이 있음
- InfoNCE
- 관찰
- 지시문(instruction)을 넣으면 성능이 더 향상되는 경향을 보임
- super-NI 데이터로 학습한 경우가 최고와 최악 대비 성능 갭이 훨씬 적음. 즉, 지시문에 따른 성능이 강건해짐
- instruction을 세밀하게 넣을 수록 성능이 향상됨(!)
- 모델 크기에 따라 성능이 향상됨 (scaling laws)
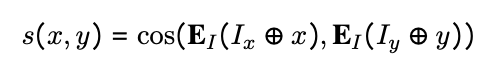
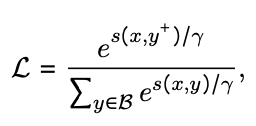
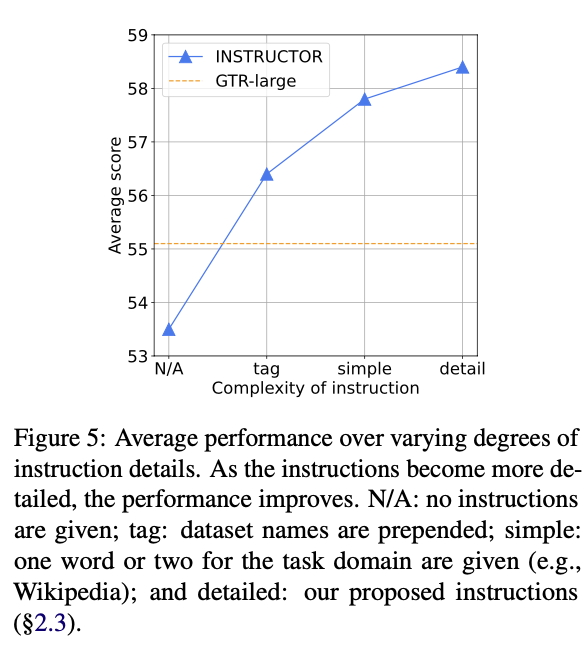
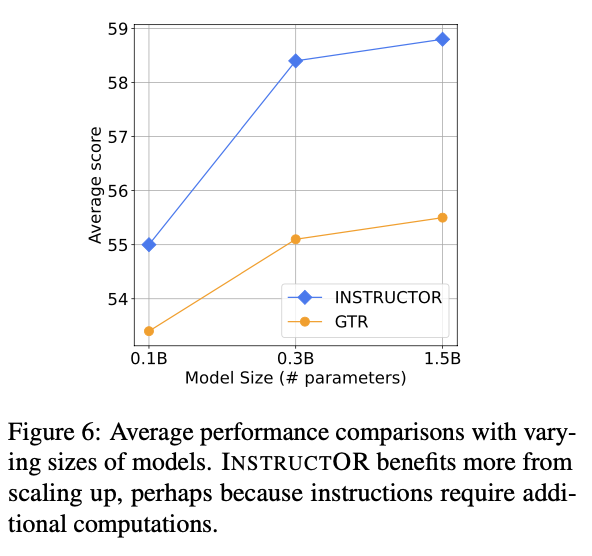
- unseen 도메인에서 더 뛰어난 성능을 보임
논의사항
- GTR 이 T5 사전 학습 + 검색 데이터로 contrastive loss 활용한 미세 조정한 형태
- 여기에 목적에 맞게 추가 데이터를 수집하여 튜닝 및 프롬프트로 성능을 향상한 모델