

전체
Paper Review
Data Curation
Hands-on
Development Glossary
Company
Search


comsat-embed 공개: 한국어·일본어 Retrieval Benchmark 1위 임베딩 모델
한국어/일본어 검색 벤치 1등 노하우 공유
유대곤 / AI/ML Researcher
Embedding
MTEB
SoTA

GPU 커널 새로 짜서 GLM-5.2 속도 10배 올리기
GPU 커널 새로 짜서 GLM-5.2 속도 10배 올리기
고석현 / CEO
MLOps
LLM
GPU

스위치 없이 B300 클러스터 구성하기
DGX B300에는 ConnectX-8 800G 포트가 8개 들어갑니다. 이 포트를 잘 쓰면 네트워크 장비 없이도 100억 원 정도 예산 안에서 소규모 클러스터를 묶는 일이 가능합니다.
고석현 / CEO
MLOps

에이전트 시대에 꼭 필요한 컨테이너 샌드박싱 전략
사람만 코드를 실행하던 시대가 끝났습니다. n8n이나 Dify 같은 AI 워크플로우 빌더에서 Code 노드가 임의 코드를 돌리고, AI 에이전트는 터미널에서 직접 명령어를 칩니다. AI가 생성한 코드, 사용자가 주입한 프롬프트가 컨테이너 내부에서 실행될 때, 우리는 어디까지 불안해해야 하고 무엇을 막아야 할까요?
송명하, ML/DevOps Engineer
DevOps

에이전트 시대에 여전히 워크플로우가 중요한 이유
사이오닉 스톰의 워크플로우 디자이너 에이전트는 자연어로 원하는 것을 설명하면 그에 맞는 워크플로우를 설계해주는 AI 에이전트입니다.
김혜원 / CPO
AI Service
Agent
Workflow

Gemini FileSearch 보다 20% 높은 성능의 스톰 파스 (STORM Parse)
Google Gemini File Search API와 STORM Parse를 실제 벤치마크로 비교 분석합니다. 270개 질문 테스트 결과, STORM Parse가 20%p 이상 높은 정확도를 보인 이유와 VLM 기반 문서 파싱이 RAG 성능에 미치는 영향을 기술적으로 깊이 있게 다룹니다.
정석현 (Julian) - AI/ML Researcher
STORM Parse
.webp&blockId=2aab25e3-2acc-8094-9368-ff1a29fc29d9&width=1024)
사이오닉에서 CEO Staff로 살아남기
사이오닉 AI에 CEO Staff로 합류한 스캇 님이 직접 소개하는 독창적인 '템플러' 문화와 열정 가득한 온보딩 스토리입니다.
안진혁 (Scott) - CEO Staff
Culture
Company

사이오닉에서 ML 리서치 인턴으로 살아남기
저는 Sionic AI에서 작년 10월부터 지금까지 (24.10 ~ 25.6) ML/AI Research Intern으로 근무한 임예원이라고 합니다. 대학 생활과 병행하며 이제는 삶의 일부가 된 Sionic 에서의 생활을 마무리하면서, 그 간의 경험을 공유하려고 합니다.
임예원 (Austin Yewon Lim) / ML Research Intern
Culture

Qwen 3 (큐웬 3) MoE Upscaling 전략
최신 AI 모델 큐웬3(Qwen3)의 핵심은 Mixture-of-Experts(MoE) 구조에 있습니다. 하지만 MoE의 성능을 최대화하려면 단순히 자주 선택되는 전문가만 쓰는 것이 아닌, 실제로 AI 출력 품질에 기여하는 전문가를 정확히 찾아 활용해야 합니다. 전문가 수를 최적화하고, 전문가 간 협력을 극대화하는 사이오닉의 혁신적인 접근법을 만나보세요.
Sigrid Jin (Jin Hyung Park) / DevRel Engineer
Mixture of Experts
Qwen3
큐웬3
.jpg&blockId=1f1b25e3-2acc-8003-a202-eb1db02a5274&width=1024)
[사이오닉 Spring AI 시리즈 2] Storm Platform으로 쉽게 구축하는 AI 에이전트
Spring AI와 Storm Platform을 이용하여 AI Agent (에이전트) 를 쉽게 구현해보는 방법에 대해 알아봅니다.
조하담 / Backend Engineer
AI
AI Service
Spring AI

작은 청크 검색 문제를 해결하는 Contextual BM25F 전략 엿보기
RAG 검색 시 작은 청크 환경에서 기존 BM25가 겪는 한계를 극복하는 Contextual BM25F 전략의 핵심 원리와 적용 사례를 가볍게 살펴봅니다.
Sigrid Jin (Jin Hyung Park) / ML DevRel Engineer
BM25F
Keyword Search

망 밖은 위험 해! 폐쇄망에서 Docker 이미지를 날렵하게 관리하는 법
해! 폐쇄망에서 Docker 이미지를 날렵하게 관리하는 법Docker 이미지가 어떤 구조로 이루어져 있고 레이어 단위의 캐싱이 어떻게 동작하는지 간략히 짚어보고, 폐쇄망 환경에서 효율적으로 증분 배포할 수 있는 전략에 대해 살펴봅니다.
송명하 / MLOps Engineer
Kubernetes
Docker
Ops
MLOps
DevOps

[Sionic Llama 4 Token Editor] 라마 4는 한국어에 가장 친화적인 오픈소스 모델입니다
Sionic AI에서 Llama 4의 토큰 분포를 분석하였고, 해당 코드를 오픈소스로 공개 합니다.
박진형 (Sigrid Jin) / DevRel Engineer
Llama4
Llama
Transformer
tokenizer
NLP

[사이오닉 Spring AI 시리즈 1] AI 나라에 봄이 찾아왔어요
Spring AI로 다양한 LLM을 유연하게 연결하고, 실습을 통해 Open AI Chat API를 만들어봅시다!
조하담 / Backend Engineer
Spring AI

[Sionic MCP 시리즈 1] Model Context Protocol을 이용하여 IntelliJ 와 코딩해보자!
최병현 (Dan) / Backend Engineer
AI Service

Terraform에서 이제 DynamoDB는 Say Good Bye!
Terraform 1.10 버전에서 가장 중요한 변화는 S3 Native State Locking 기능 입니다.
송명하 / MLOps Engineer
Kubernetes
Infrastructure

CES 2025 참가 후기
CES 2025 다녀왔습니다.
조하담 / Backend Developer
CES
Sionic AI

TDD를 통해 ModernBERT 밑바닥부터 이해하기
유닛 테스트를 작성하면서 최신 임베딩 및 리랭커 모델의 근간인 ModernBERT의 구현체를 이해하여 봅시다.
Sigrid Jin (Jin Hyung Park) | ML DevRel Engineer
Model Architectures
Encoding

인공 일반 지능(AGI)의 발전과 연구 동향 101
인공 일반 지능(AGI)의 발전을 위해 대규모 언어 모델(LLM)의 학습 과정과 성능 향상 방안을 설명하며, 다양한 학습 방법의 장단점과 실제 적용 사례를 논의합니다.
윤도균/ ML Reseacher
LLM
large language model
AGI

문서 기반 Q&A: RAG로 GPT를 더 똑똑하게 쓰는 방법
이 아티클에서는 RAG의 기본 개념과 사용하는 이유, 코드 기반의 가장 간단한 RAG 실습을 다룹니다.
송영숙 /ML research · 정책총괄
RAG
QA

BGE-M3 모델 Dense, LayerNorm만으로 처음부터 구현하기
BGE-M3 다국어 임베딩 모델의 구조와 TensorFlow Keras 구현 방법에 대해 상세히 다룹니다.
고석현 / CEO
BGE-M3
Transformer
NLP
TensorFlow
Keras

아직도 GPU 하드웨어를 고려하지 않고 모델링을 하시나요?
The Case for Co-Designing Model Architectures with Hardware 논문 리뷰"
Sigrid Jin (Jin Hyung Park) | ML Backend Engineer
Model Architectures
GPU
Hyper parameter

기계학습과 딥러닝, 그리고 언어 모델에 대한 개관
기계학습의 개념과 역사 등에 대해 개괄적으로 다룹니다.
송영숙/ML research · 정책총괄
AI
ML
NLP

ModernBERT: 최신 LLM 기법으로 BERT를 개선할 수 있을까?
2024년 12월 릴리즈된 ModernBERT를 통해 새로운 인코더 모델의 백본에 대해 알아봅니다
Sigrid Jin (Jin Hyung Park) | ML DevRel Engineer
Embedding

KoGEC: 사전 학습된 번역 모델을 활용한 한국어 문법 오류 교정
한국어 문법 오류 교정(KoGEC) 모델 연구 경험을 공유합니다.
김태은/ AI · ML Research Intern
GEC
NLLB

FlagEmbedding으로 BGE-M3 학습하기
FlagEmbedding으로 BGE-M3 학습
김태은/ AI · ML Research Intern
Embedding
BGE-M3
FlagEmbedding
Hard Negative

AI 회사에서 AI를 활용하는 법: STORM Fooding 사례
STORM Fooding 사례를 통해서 AI 회사에서 AI를 활용하는 방법을 알아봅니다.
정세민/ ML Backend Engineer · Development
Fooding
RAG
Graph RAG

실무 사례로 알아보는 Strategy Pattern
전략 패턴의 개념 및 적용 사례 소개
조하담 / Backend Engineer
Strategy Pattern
RAG
Passport.js

ReSpect
사람과의 Interaction을 통해 Agent를 점점 똑똑하게 만드는 방법
박우명 / CDO & Head of Research
LLM
Interaction

모델의 평가 능력을 평가하기
LLM evaluation 능력을 평가할 수 있는 JudgeBench 제작 방법론 및 실험 결과 소개
박우명 / CDO & Head of Research
LLM-as-a-Judge
Benchmark

문자가 포함된 이미지 기반 문장 생성(이미지 캡셔닝)의 이해
이미지 캡셔닝 작업 설명
송영숙/ML researcher
image
captioning
large language model


학습 데이터를 고르는 효과적인 방법은?
학습 데이터 선택 방법 분석
박우명 / CDO & Head of Research
Tuning
LLM
Data Selection

LLM의 평가 능력을 올리기 위한 방법들
LLM의 판단을 스스로 한번 더 평가한 'Meta-Rewarding'을 활용한 새로운 학습 방법 소개
박우명 / CDO & Head of Research
LLM
Prompting
LLM-as-a-Judge


LLM을 합쳐보자: 모델 병합 기법에 대한 고찰과 실험
LLM 모델 병합 기법에 대한 소개
백상원 / ML Researcher
LLM
AI
large language model
Research

멀티모달 문서 검색을 위한 Embedding 모델
VLM을 활용하여 Multi-modal Embedding 만드는 방법 소개
박우명 / CDO & Head of Research
Multimodal
Embedding

Prompt Recovery for LLM
LLM의 결과로부터 Prompt를 유추하는 방법
박우명 / CDO & Head of Research
LLM
Prompting


GPT를 이용한 문법 오류 교정(GEC) 모델
문법 오류 교정
송영숙/ML Researcher
GPT
GEC
Startups
LLM
Grammatical Error


CUDA C 수준에서 한국어 토크나이저 구현
한국어 토크나이저 처리
고석현 / CEO
OOV
CUDA
tokenizer
Encoding

추론을 중심으로 살펴본 AI 성능 평가의 흐름
인공지능의 성능 평가
송영숙 / ML Reseacher
Benchmark
LLM
Generation
AI

CICERO 데이터 세트
인공지능 모델의 상식적 사고와 관련된 대화 데이터
송영숙 / ML Researcher
CICERO
Reasoning
.png&blockId=1d583ee8-1821-428d-a3a1-42cd81e80e10&width=1024)
LLM의 추론 능력 높이기 : Self Discover
풀이 방법을 먼저 설계한 후 실제 문제를 푸는 2단계 방식으로 추론 능력 향상
박우명 / CDO & Head of Research
LLM
Prompting
Reasoning

LLM은 오류를 스스로 검출하고 수정할 수 있을까?
초거대 언어모델이 오류를 검출하고 답변을 수정할 수 있는지에 대한 실험
박우명 / CDO & Head of Research
LLM
Self Correction
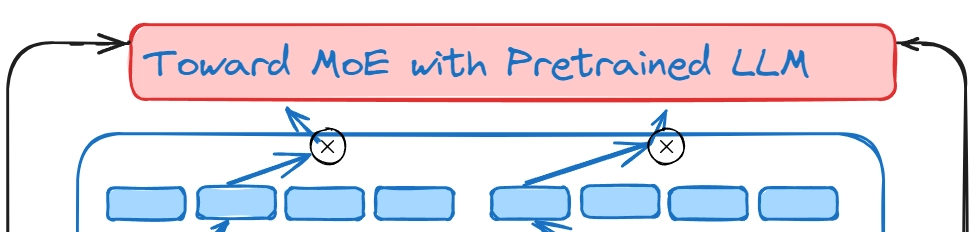
Toward MoE with Pretrained LLM
효율적인 MoE 학습 방법론 소개
박우명 / CDO & Head of Research
LLM
Mixture of Experts
Finetuning

Red Teaming Language Models to Reduce Harms
비폭력, 비윤리적 출력을 검증할 수 있는 데이터 세트
송영숙 / ML Researcher
Reduce Harms
Generation

LLM을 활용하여 최고의 Text Embedding 만들기
초거대 언어 모델을 활용한 텍스트 임베딩
박우명 / CDO & Head of Research
Embedding
MTEB
LLM
data
.png&blockId=42e9cb5b-303a-4b14-bffa-33c1e0250510&width=1024)

Clova X를 이용한 SuperNI 데이터세트 한국어 번역
StrategyQA 논문과 데이터 세트 소개
송영숙 / ML Researcher, 박우명 / CDO & Head of Research
StrategyQA
Super-NaturalInstructions
corpus
Translation data

지극히 사적인 나만의 LLM, 가질 수 있을까? [2편 - WebGPU Build & Run]
개인의 쓰임에 맞춘 초거대 언어 모델 활용
김덕현 / Head of Development
LLM
Generation
WebAssembly
WebGPU

Code를 통하여 LLM의 추론 능력을 높일 수 있을까?
코드를 통한 거대언어모델의 추론 능력 향상
박우명 / CDO & Head of Research
Prompting
Tuning
Reasoning

슬랙 사용 가이드
효과적인 슬랙 사용 가이드
김혜원 / CPO, 김덕현 / Head of Development
Culture
Slack

Super-NaturalInstructions
Super-NaturalInstructions(SuperNI) 논문 및 데이터 세트 소개
박우명 / CDO & Head of Research, 송영숙 / ML Researcher
Instruction
LLM
dataset
Super-NaturalInstructions

Vector Database 구축 실습
Vector Database 구축 실습
송명하 / MLOps Engineer
Vector Database
NLP
.png&blockId=d316aec1-9268-4da2-84c7-2f7166327ff5&width=1024)
한국어 말뭉치 구축(1)
한국어 말뭉치 소개
송영숙 / ML Researcher
data
large language model
corpus

자동으로 최적의 Prompt를 생성하기
최적의 프롬프트 방법론을 소개합니다.
박우명 / CDO & Head of Research
Prompting
AutoPrompt

지극히 사적인 나만의 LLM, 가질 수 있을까? [1편 - 파인튜닝]
초거대 언어모델에 학습시킨 내 데이터로 나에게 최적화된 일을 시도해보자.
박진형 (Sigrid Jin) / Software Engineer
Finetuning
Llama
LLM

LLM은 스스로 답변의 위험성을 판단할 수 있을까?
초거대 언어 모델의 답변 위험성 판단과 관련된 논문 소개
박우명 / CDO & Head of Research
Prompting
Alignment
LLM
프롬프팅으로 사실 확인하기(Fact Verification)
초거대 언어모델의 발화가 사실인지 아닌지를 확인하는 방법론과 관련된 논문을 소개합니다.
박우명 / CDO & Head of Research, 김덕현 / Head of Development
Prompting
Fact Verification

프롬프팅을 통한 LLM의 추론 능력 향상
초거대언어모델의 추론 능력 향상을 위한 프롬프팅 방법론
박우명 / CDO & Head of Research
Prompting
Tuning
LLM
Reasoning

표 데이터 기반 문장 생성
표 데이터 분석 방법론 소개
송영숙 / ML Researcher
Table
Generation

효과적인 프롬프팅(Prompting) 방법론 소개
효과적인 프롬프팅(Prompting) 방법론 소개
박우명 / CDO & Head of Research
Prompting
Tuning
LLM


WebGPU를 통한 private 생성 AI의 Hybrid Inference
WebGPU를 통한 개인화 생성 인공지능의 추론 방법론 소개
고석현 / CEO
WebGPU
AI
Hybrid Inference
MTEB 상위권 방법론들
MTEB 상위권 방법론 소개
박우명 / CDO & Head of Research
MTEB
Embedding
Benchmark